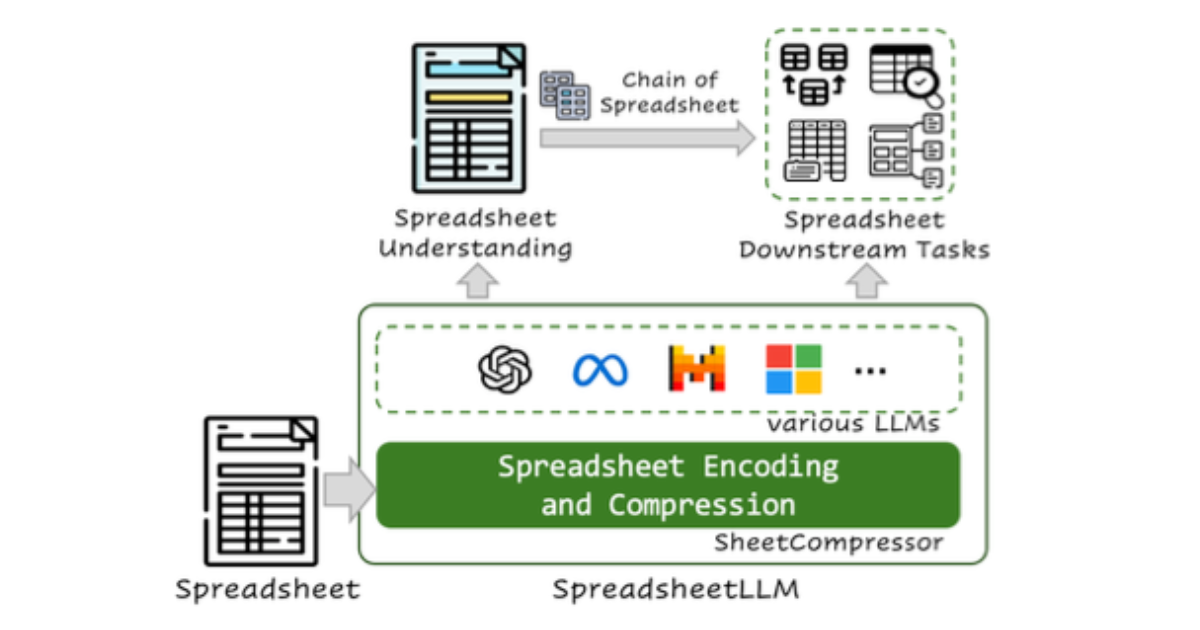
Microsoftの研究陣は大規模言語モデル(LLM)を用いてスプレッドシートデータを理解・分析するための新しいフレームワークである「SPREADSHEETLLM」の研究結果を発表しました。発展途上ながら、自然言語ベースでの分析が困難であったExcelなどのスプレッドシート分析の未来を垣間見ることができます。
SPREADSHEETLLMの概要
「SPREADSHEETLLM」は、大規模言語モデル(LLM)を用いてスプレッドシートデータを理解・分析するための新しいフレームワークです。
スプレッドシート処理は、従来のLLMにとって非常に難しい課題を抱えていました。例えば、スプレッドシートは広範囲なグリッドを持つため、一般的なLLMのトークン制限を超えてしまうことや、 2次元のレイアウトと構造を持つため、線形および連続した一方向の入力に適したLLMには適していないことなどが挙げられます。
「SPREADSHEETLLM」は「SHEET COMPRESSOR」という独自の手法で、容量圧縮によるデータ処理を効率化し、スプレッドシートの理解・分析に貢献します。
SHEET COMPRESSORとは
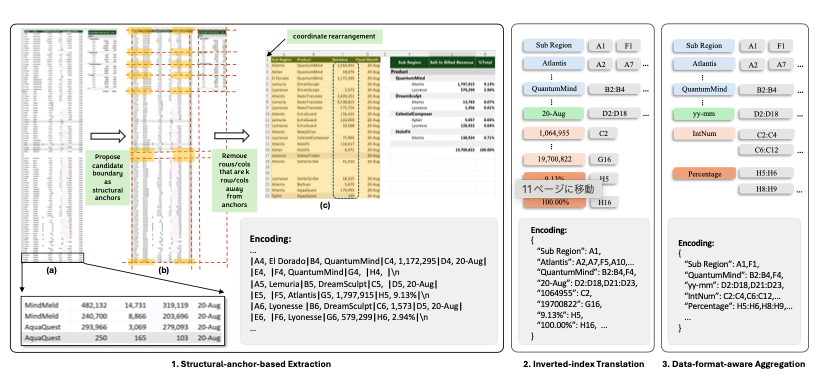
「SHEET COMPRESSOR「は、「SPREADSHEETLLM」の中核となる革新的な技術です。LLMがスプレッドシートを効率的に処理できるように、スプレッドシートを圧縮します。「SHEET COMPRESSOR」は、以下の3つのモジュールで構成されています。
- 構造アンカーに基づく抽出:レイアウトの理解に寄与しない行や列を特定・削除することで、スプレッドシートを効果的に圧縮します。
- 転置インデックス変換:空のセルと繰り返し値を処理する際のトークン効率を向上させるために、可逆データ圧縮技術を採用します。これにより、トークンの使用を最適化しながら、データの整合性を維持します。
- データ形式認識型集約:隣接する数値セルの数値形式の類似性を認識し、正確な数値よりもデータ型を優先してクラスタリングします。これにより、トークンの消費を抑えながら、数値データの分布を効率的に表現します。
SPREADSHEETLLMのパフォーマンス
「SPREADSHEETLLM」は、表計算ソフトの表検出、QA、データ抽出、数式やコードの生成、エラー検出など、幅広いタスクに有効です。
実験の結果、「SPREADSHEETLLM」は、表の検出において従来の最先端手法を凌駕し、最大12.3%高いF1スコアを達成しました(F1スコアは機械学習の精度を測る指標の一つ)。また、スプレッドシートのQAにおいても、既存の最先端手法を大幅に上回る精度を達成しました。
SPREADSHEETLLMの展望
SPREADSHEETLLMは研究途上であり制約があります。例えば、背景色や罫線などのフォーマットの詳細を理解することはできません。また、数値データの集約は効果的ですが、自然言語を含むセルに対しては、高度な意味ベースの圧縮手法を確立できていません。
フォーマット詳細の活用、自然言語の意味解析の改善、より高度な圧縮技術の探求など、さらなる研究開発を進めることで、SPREADSHEETLLMは、よりインテリジェントで効率的な表計算ソフトのデータ管理と分析への道を切り開き、ユーザーインタラクションの変革の可能性を秘めています。
「SPREADSHEETLLM」について一言
Microsoft Copilotを試して絶望したことがある方であれば、この研究の成果については色々と感じるものがあるのではないでしょうか。
そもそもMicrosoft Copilot全般の生煮えなクオリティと自信過剰な価格水準には呆れましたが、特にExcelはその最たる例でした。というのも、表形式の分析をしようとしても、ほとんどのプロンプトを処理できず、処理させるためには表を加工する一手間が必要でした。
今回の論文を読み、この理由が、というか表計算ツールのデータ処理の難易度の高さを感じることができました。確かにデータボリュームや二次元のデータ配置など特殊性があり、この辺りが現在の研究の最前線であることを考えると、Microsoft CopilotのExcelに対してのみクオリティに疑義を感じるのは見当違いでした、すみません(プライシングには納得いっていませんが)。
ChatGPTではセルアドレスを指定してデータ処理をすることはできるようになってきましたがクオリティ面では今ひとつな感じがするので、SPREADSHEETLLMの研究が進捗することで、また一つ生成AIを使う意義が出てくると思います。
出典:SPREADSHEETLLM: Encoding Spreadsheets for Large Language Models







