Gemma 3n は、スマートフォンやノートPCといった日常デバイス上で高度な生成AIを動かすことをめざして設計された Google の最新オープンモデルです。テキスト・画像・音声・動画を一度に扱えるマルチモーダル性能と、MatFormer や PLE キャッシュなどの効率化技術によって、推論スピードとメモリ消費を劇的に削減しました。Gemini Nano と同系統のアーキテクチャをオープンウェイトで先行体験できる点も大きな魅力で、モバイル・エッジ領域における AI 活用の可能性を大きく押し広げています。

Gemma 3n とは
Gemma 3n は、Google が 2025 年 5 月に早期プレビューを開始した軽量生成モデルの最新バージョンです。名称中の「n」は Nano を意味し、Pixel 端末向けに搭載されている Gemini Nano と同じ設計思想を受け継いでいます。ただし Gemma 3n は オープンウェイト(学習済み重みを一般公開)で提供され、かつ商用利用が許可されているため、企業や開発者が自社アプリに組み込み、追加学習(ファインチューニング)して配布することもできます。Gemma 3n は現在アーリープレビューとして提供されており、Google AI Studio と Google AI Edge で試用できます。
Gemini Nano は Google が Pixel デバイス向けに閉じた形で提供する組み込みモデルです。一方 Gemma 3n はオープンライセンスで公開されているため、Pixel 以外の Android 端末や IoT 機器にも搭載できます。両モデルは同じ基盤技術を共有しているため、Gemma 3n で培ったカスタマイズや最適化ノウハウは、将来 Gemini Nano を利用する場面でもそのまま活用できる可能性があります。要するに、Gemma 3n は Gemini Nano を「誰でも試せる形」に開放したモデルと捉えると分かりやすいでしょう。
Gemma 3n を端末内で動かせば、第一にクラウドとの通信回数が減るため ネットワーク帯域と GPU 料金を節約できます。第二にデータを外部に送らないことで プライバシーや国内外の規制対応が容易になります。さらに地下鉄や山間部のように通信が不安定な場所でも <100 ms 程度の応答が得られるため、リアルタイム性が求められる AR グラスや車載アシスタントとの相性が良好です。オープンウェイトゆえに、日本語固有の専門用語や社内文書を追加学習させることで カスタマイズの自由度 も高まります。
スマートフォン分野では、カメラで映したメニューをその場で翻訳したり、観光地の建物を AR で解説したりといったオフライン体験が実現できます。スマート家電では、冷蔵庫の内蔵カメラが食材を識別し、そのままレシピを提案する仕組みをクラウド不要で提供できるため応答がスムーズになります。自動車の HMI(Human‑Machine Interface)では、トンネル内など通信が途切れる環境でもドライバー支援を継続できます。産業 IoT では工場のエッジサーバー上で設備異常を検知し、ネットワーク負荷を抑えつつ即時アラートを発報。医療分野では、リハビリ用アプリが患者の姿勢をカメラで解析し、機微データをクラウドへ送信せずに安全にフィードバックを提供できます。これらの例は、「高性能だが軽量」な Gemma 3n がエッジ側の新しいビジネス機会を広げることを示しています。
Gemma 3n の技術
Gemma 3n が小さなメモリでも高速に動く背景には、主に二つの仕組みがあります。 ひとつは MatFormer(Matryoshka Transformer) という入れ子構造です。これは「ロシアのマトリョーシカ人形」のように、1 つの大きなモデルの中にサイズの異なるサブモデルを収納するアイデアで、処理のたびに「高精度が必要か、それとも速度を優先するか」を選び、不要なパラメータを休ませることで計算コストを節約します。 もう一つは PLE(Per‑Layer Embedding)キャッシュです。推論時に各層が生成するデータを高速ストレージへ一時退避させ、次のステップで再利用することで、毎回すべてをメモリに置かずに済む仕組みです。さらに音声や画像に関係する重たいパラメータは「条件付き読み込み」で必要になったときだけ取り込みます。これらの工夫により、実行時に実際に読み込むパラメータは理論値の半分以下となり、3 GB 前後の RAM があれば 4B モードでも動作します。
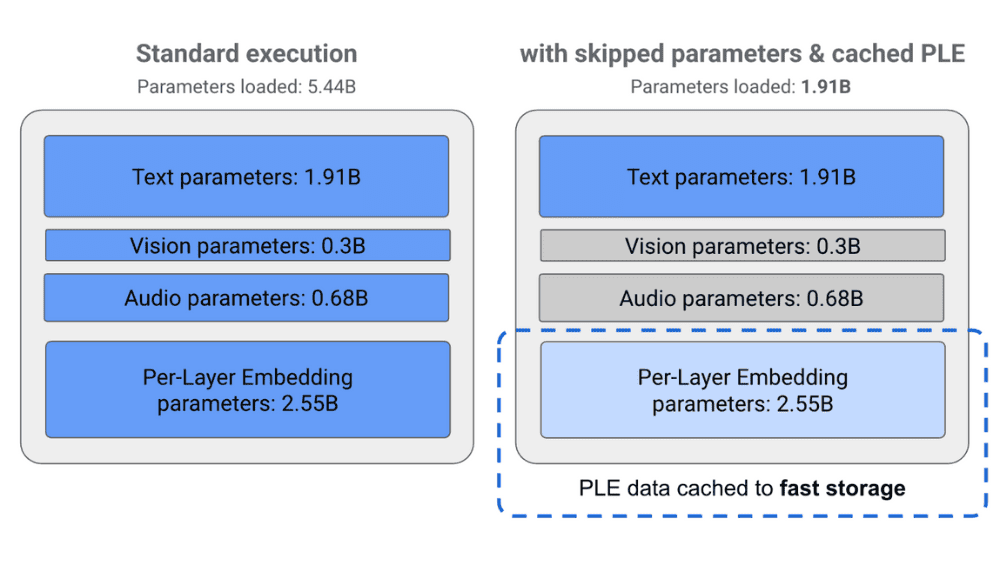
Google AI Studio のデモ環境で計測したところ、Gemma 3n は従来の Gemma 3 4B と比べてプレフィル(入力を内部表現へ展開する前処理)が約 1.5 倍高速でした。生成速度も、最新のスマートフォン向け System‑on‑Chip(SoC)であれば 4B モードでも毎秒 10 トークン以上、より軽い 2B モードでは 25 トークン以上を記録しています。ここで言う「トークン」は文章を細かく分解した単位で、英単語の約 0.75 語、日本語の 1〜2 文字に相当します。 メモリ面では 2B モードで約 2 GB、4B モードで約 3 GB の RAM を消費するため、RAM 8 GB クラスの一般的なスマートフォンでも余裕を持って動かせる計算です。
「Gemma 3n」について一言
Googleの軽量ラインナップから、エッジデバイス用のモデルがリリースされました。このモデルでは、処理内容の一部を記憶しておくキャッシュ機能や、推論時のモデル使用効率を向上させるアプローチが採用されており、実際の処理時におけるモデルサイズを実質的に小さくする技術が活用されています。
特に注目すべき点は、対応するモダリティの幅が非常に広いことです。このモデルはモバイル端末での動作を前提として設計されており、テキスト、画像、音声など複数の入力形式に対応できる汎用性を持っています。
モバイル端末では、処理能力やメモリ容量に制約があり、大規模な計算処理を実行することも、大容量のデータ通信を行うことも困難です。このような制約がある環境において、オフラインでの高品質なAI機能の提供や、通信コストの削減を実現できるため、スマートフォンアプリ、IoTデバイス、リアルタイムでの画像・音声処理といった用途での活用が大いに期待されます。また、プライバシーを重視するアプリケーションにおいても、データをクラウドに送信せずにローカルで処理できるメリットは非常に大きいでしょう。