Googleは、低レイテンシーかつ高性能なAIモデル「Gemini 2.0 Flash」「Gemini 2.0 Pro」「Gemini 2.0 Flash-Lite」の提供を開始しました。特に、昨年末に開発者向けにリリースされていた2.0 FlashはGeminiアプリでの利用が可能になり、より強力な推論性能とマルチモーダル対応がより身近になります。さらに、Proは過去最大の200万トークンのコンテキストウィンドウを誇り、複雑なプロンプトへの対応力を強化しています。

Gemini 2.0 Flash:高頻度タスクに最適なモデル
Googleは、昨年発表したFlashシリーズを強化し、2.0 Flashの本番環境での提供を開始しました。このモデルは、低レイテンシーでありながら、100万トークンのコンテキストウィンドウを活用したマルチモーダル推論が可能で、大規模な情報処理を求められる場面での利用に適しています。
2.0 Flashは、開発者コミュニティからのフィードバックを反映し、より優れたパフォーマンスを実現しました。現在、Google AI StudioとVertex AIのGemini APIを通じて利用可能であり、デスクトップおよびモバイルのGeminiアプリでも使用できるようになりました。
さらに、今後数か月で画像生成やテキスト読み上げ機能が追加される予定であり、より多様な用途での活用が期待されます。
Gemini 2.0 Pro:高度な推論とコーディング性能の向上
新たに試験運用が開始されたGemini 2.0 Proは、特にコーディングタスクや複雑なプロンプトに対応する能力が強化されています。このモデルの最大の特徴は、200万トークンのコンテキストウィンドウを持つ点で、これはGoogleのAIモデルとして過去最大のものです。
この拡張により、大量の情報を取り扱いながら、高度な推論を行うことが可能になり、検索エンジンやコード実行といった外部ツールの呼び出し機能も搭載されています。これにより、開発者は大規模なコードベースの理解や最適化を行いやすくなりました。
試験運用版はGoogle AI StudioとVertex AIの開発者向けに提供されており、Gemini AdvancedユーザーもGeminiアプリで利用可能となっています。
Gemini 2.0 Flash-Lite:コスト効率と速度を両立
Googleは、開発者向けに最もコスト効率の高いモデル「2.0 Flash-Lite」も公開しました。このモデルは、1.5 Flashと同等のコストと速度を維持しながら、性能を向上させたバージョンです。
Flash-Liteも100万トークンのコンテキストウィンドウとマルチモーダル入力を備えており、画像認識やキャプション生成などのタスクで活用できます。たとえば、Google AI Studioの有料プランでは、1ドル未満で約4万枚の写真に対して適切なキャプションを生成可能です。
現在、Google AI StudioとVertex AIにて一般ユーザー向けにプレビュー提供が開始されています。
Gemini 2.0シリーズのベンチマーク評価
Gemini 2.0シリーズは、用途に応じた3つのモデルを提供しています。最上位のProは、数学・推論・多言語処理などあらゆるベンチマークで最高スコアを記録し、シリーズ最強の精度を誇ります。Flashは、従来の最高モデルである1.5 Proを多くのベンチマークで上回り、バランスの取れた高性能モデルとして進化しました。一方、Flash-Liteは、FlashやProには及ばないものの、高効率モデルとしては過去最高の性能を示し、1.5 Proにも迫る場面があります。これにより、Gemini 2.0は用途に応じた最適な選択肢を提供するモデル体系へと進化しました。
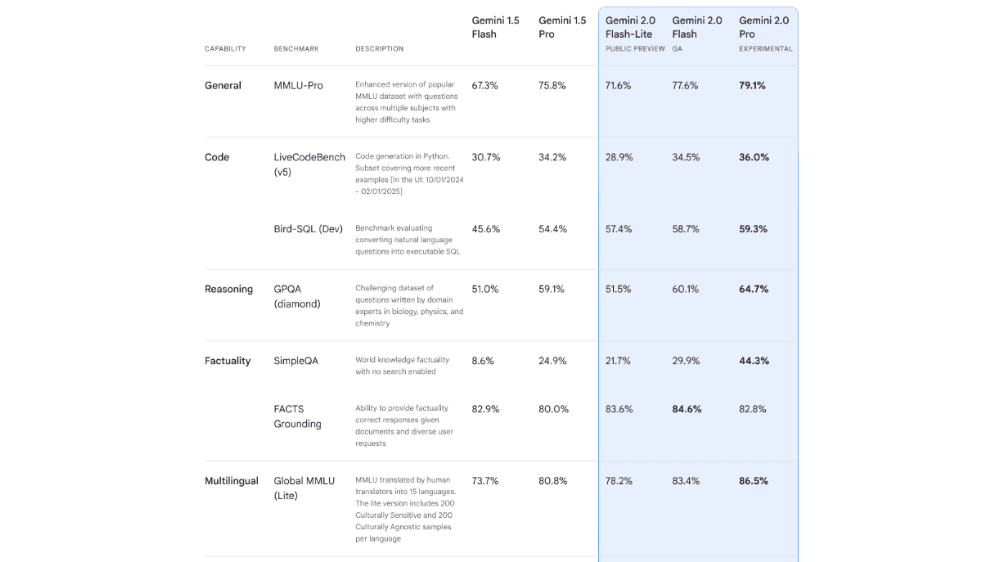
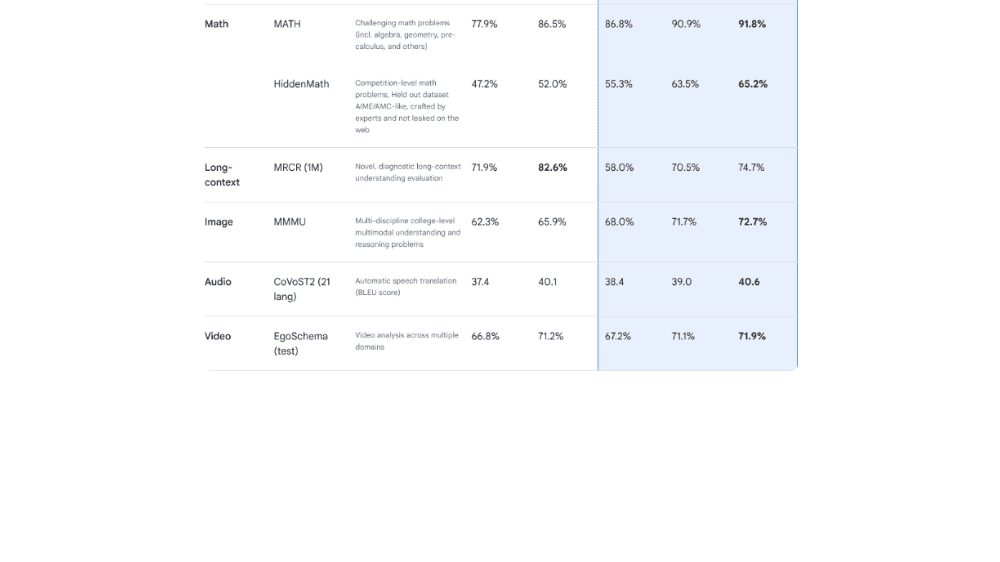
「Gemini 2.0シリーズ」について一言
モデルが色々あって混乱しがちですが、2.0 Flashは昨年末に開発者向けにリリースされたものの一般公開、2.0 Flash-Liteはその軽量版、2.0 Proはフィードバックをもとに改良された最高性能モデル、という位置づけのようです。このほかにも多段階で推論を実施する2.0 Flash Thinkingもアプリ上では利用可能です。
使い分けについては、開発向けでは性能を多少犠牲にしてコスト効率を優先するFlash-Liteのようなモデルが好まれそうです。一般ユーザーが2.0 Flash、2.0 Pro、2.0 Flash Thinkingから選ぶことになりますが、ロングコンテキスト(~200万トークン=1,500ページ相当の本)であれば2.0 Proになるかなと思います。色々と試してみようと思います。