
Alibabaが開発する大規模言語モデルQwenファミリーの最新版「Qwen3」が発表されました。今回のモデルでは、すべてのパラメータを一括で活用する従来型の密モデルに加えて、必要な部分だけを選んで使うことで効率的な計算を可能にするMoE(Mixture of Experts)モデルがラインナップされています。この両輪展開により、精度を犠牲にすることなく、実用的な速度とコストでの応答を実現しています。119言語に対応する多言語機能、ユーザーが処理深度を制御できる思考モード切り替え、そして外部ツールとの連携も可能なエージェント実行機能など、多彩な強化が図られています。

Qwen3のモデルラインナップ
Qwen3シリーズは、大きく2つの構成に分かれます。すなわち、密モデル(Dense Model)とMoEモデル(Mixture of Experts)です。
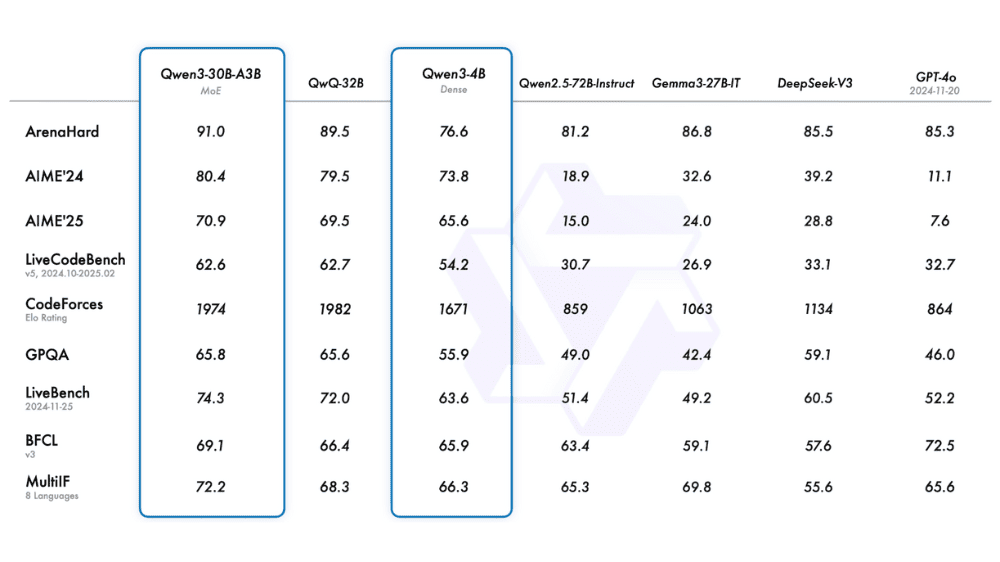
密モデルは、従来型のLLMと同様、全パラメータが推論時に使われる構造です。Qwen3の密モデルには、Qwen3-0.6B(32K)、Qwen3-1.7B(32K)、Qwen3-4B(32K)、Qwen3-8B(128K)、Qwen3-14B(128K)、Qwen3-32B(128K)の6種類が用意されています。各モデルは、コンテキスト長の違いやパラメータ数の増加により、用途に応じて選択可能です。特に8B以上のモデルは128Kの長文処理にも対応しており、実用的な処理能力と応答精度を兼ね備えています。各モデルは、前世代のQwen2.5よりも少ないパラメータで同等または上回る性能を発揮しており、特にSTEM分野やコード生成での精度が向上しています。
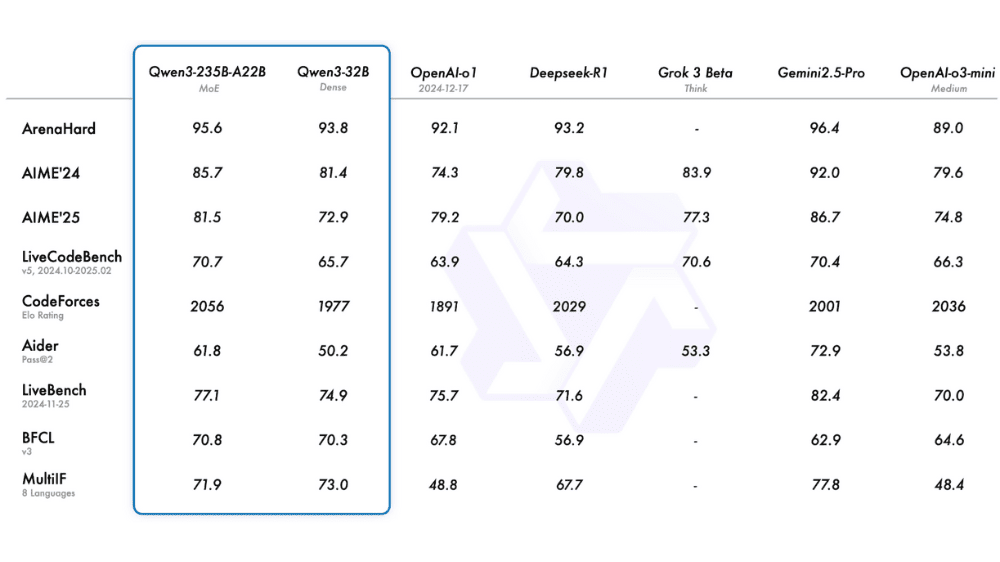
一方のMoEモデルは、膨大なパラメータ群の中から一部だけを推論時に使用する構造で、効率と性能を両立します。Qwen3のMoEモデルには、Qwen3-30B-A3BとQwen3-235B-A22Bの2種類が用意されています。前者は総パラメータ300億のうち、推論時に使用されるのは30億パラメータで、コンテキスト長は128Kです。後者のQwen3-235B-A22Bは、総パラメータがなんと2350億に達する一方、実際に計算に使われるのは220億パラメータに抑えられています。これにより、極めて大規模な知識ベースを持ちながら、計算効率に優れた高性能な推論を可能にしています。
Qwen3は、多様な開発・実行環境に対応しています。開発用途としては、Hugging Face、ModelScope、Kaggleといった機械学習プラットフォーム上で容易に導入可能で、研究用途にも適しています。また、vLLMやSGLangなどのフレームワークを使用すれば、OpenAI APIと互換性のあるエンドポイントとしてデプロイすることもできるため、既存のアプリケーションに組み込む際の互換性も確保されています。
加えて、Qwen3はWebアプリケーションとしても提供されており、chat.qwen.aiにアクセスすることで、ユーザーはブラウザベースでQwen3の機能を体験できます。モバイルアプリにも対応しているため、スマートフォンからでも利用でき、日常的なAIアシスタントとしての役割も担えるようになっています。
Qwen3の特徴
Qwen3は、ユーザーがプロンプトで”/think”(思考モード)と”/no_think”(非思考モード)を切り替えることで、推論の深さと速度を制御できます。これにより、複雑な推論が求められるタスクには段階的な推論を、簡易な質問には即答が可能な応答を選択できるようになりました。タスクの性質に応じてリソースを最適に割り当てることができ、コスト効率と品質のバランスに優れています。
Qwen3は119言語に対応し、日本語、中国語、英語はもちろん、インド系、アラビア語、スラブ系の方言にまで対応範囲を広げています。筆者が実際に日本語でテストしたところ、これまでのモデルに見られた語調の不自然さが大幅に改善されており、業務利用に耐えるレベルに達していると感じました。
Qwen3はツール呼び出しに対応したエージェント機能を強化しています。MCP(Multi Component Protocol)に対応しており、Qwen-Agentと組み合わせることで、ツールコールや外部APIとの連携を含む複雑な操作も自動化できます。内部でテンプレートとパーサーを備えているため、実装負荷も小さく抑えられています。

学習方法
Qwen3は、まず36兆トークンという非常に大規模なデータセットを使って事前学習を行っています。この数字は、従来のQwen2.5と比べて2倍に相当し、人間のあらゆる言語活動や知識の広がりを再現しようとする試みに近い規模です。
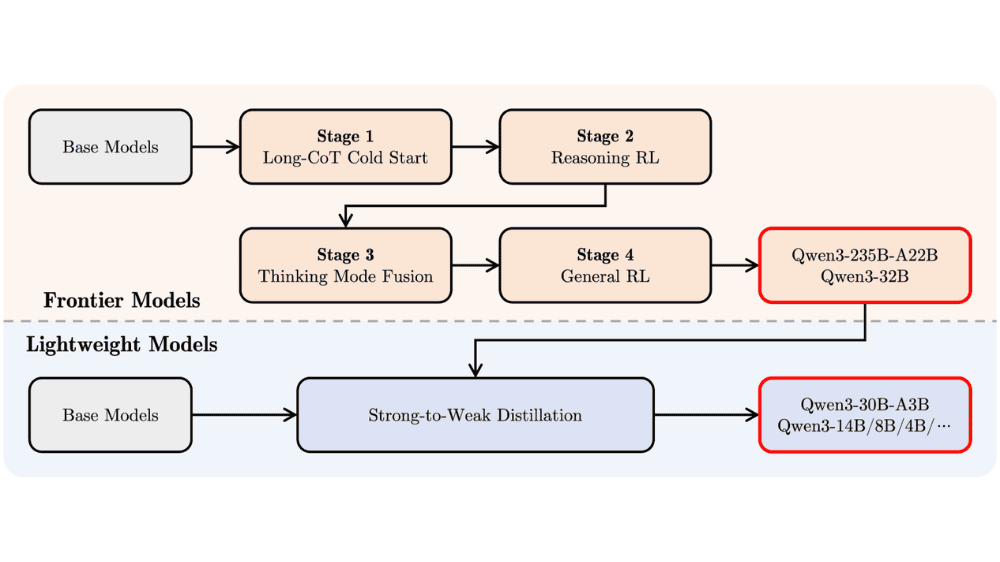
その後、Qwen3はさらに精度を高めるために、4段階の「ポストトレーニング」(事後学習)を実施しています。まず第一段階では、数学やプログラミング、科学技術(STEM)など、論理的思考や知識が問われる分野に特化したデータを用いて、長い思考の流れ(Chain of Thought: CoT)に対応できるよう訓練されました。
第二段階では、強化学習の手法を取り入れ、特定のルールに従って正しい思考を強化する訓練が行われています。これにより、推論の一貫性や信頼性が向上しました。
さらに第三段階では、これまでに獲得した”考える力”と、日常的な指示に即応する”反射的な応答力”の両立を目指し、両者を融合する学習が実施されました。
最後の第四段階では、20以上の一般的なタスク(例:命令の理解、フォーマットに従った出力、ツールの呼び出しなど)に取り組むことで、モデルの汎用性を高める調整が行われました。
このように、Qwen3はただ単に大量の情報を詰め込んだモデルではなく、段階的に「考えられるAI」へと育て上げられたことが、大きな特徴となっています。非エンジニアにとっても、「知識だけでなく、思考のプロセスまで学んだAI」と理解するとイメージしやすいかもしれません。
「Qwen3」について一言
Qwen3は、性能面では現行トップクラスのGemini 2.5 Proにも迫るレベルにあり、特に多言語性能は圧倒的です。これまで不得手だった日本語も、自然な表現と的確な応答が可能となり、業務応用が視野に入ります。
加えて、他社が密モデルでスケーリングを図る中、AlibabaがMoE(疎モデル)を重視する戦略には、モデル競争上の明確なメリットがあります。すなわち、**同等の推論品質を維持しつつ、演算コストを抑えられるため、長期的なスケーラビリティとデプロイ性に優れる(様々な環境にあるデバイスへの活用が狙える)**という点です。この設計方針は、次世代のAI基盤として多くの実装環境にフィットする可能性を持っています。
出所:Qwen3: Think Deeper, Act Faster







