
DeepSeek V3で公開された開発手法(スケーリング)の知見をもとにAlibabaが開発した最新モデル「Qwen2.5-Max」が注目を集めています。「Qwen2.5-Max」はMoE(Mixture-of-Experts)という手法を用いており、大規模モデルでありながら、GPTやGeminiといったモデルよりも高い計算効率での推論が可能です。また、GPTやClaudeの汎用モデルを超えるパフォーマンスとしてを示しています。

Qwen2.5-Maxとは
Qwen2.5-MaxはAlibabaが開発した最新の大規模言語モデルで、Mixture-of-Experts(MoE)という開発手法を活用することで、大規模でありながら、高い計算効率を誇ります。Mixture-of-Experts(MoE)は、多数の専門家を含む層を用意し、入力された文章や単語に応じて最適な専門家だけを活性化する仕組みです。全パラメータを一度に使う高密度モデルと異なり、必要な部分だけに計算を集中させることで、大規模さと効率性を両立しやすい設計になっています。企業にたとえるなら、大規模な組織の各部署に強みが分かれており、案件に応じて適切な部署が担当するイメージに近いです。
Qwen2.5-Maxは、このMoEの設計を最大限に活用しており、20兆を超えるテキストデータによる事前学習を経て、SFT(教師ありファインチューニング)やRLHF(人間のフィードバックを用いた強化学習)などのプロセスを重ねています。膨大なトークン数を扱うことで幅広い言語能力を得ると同時に、人が求める形で応答しやすいよう工夫されています。学習にはDeepSeek V3で公開されたスケーリング手法が取り入れられており、大規模モデルの開発で蓄積された最新の知見が反映されています。
Qwen2.5-Maxはこちらのチャット画面から試すことができ、またAlibaba CloudのModel Studioを利用してAPI経由でアクセスすることもできます。
Qwen2.5-Maxのパフォーマンス
Qwen2.5-Maxは、MMLU-ProやLiveCodeBench、LiveBench、Arena-Hardといった多彩なベンチマークで評価されています。MMLU-Proでは大学レベルの知識を問われ、LiveCodeBenchではコーディング能力が試され、LiveBenchやArena-Hardなどでは一般的な言語運用能力や人間の好みに近い応答の実現度合いをチェックします。その結果、DeepSeek V3やClaude-3.5-Sonnet、GPT-4oなどの主要モデルと比べても競争力のあるスコアを示しており、なかには優位性を発揮するケースも報告されています。
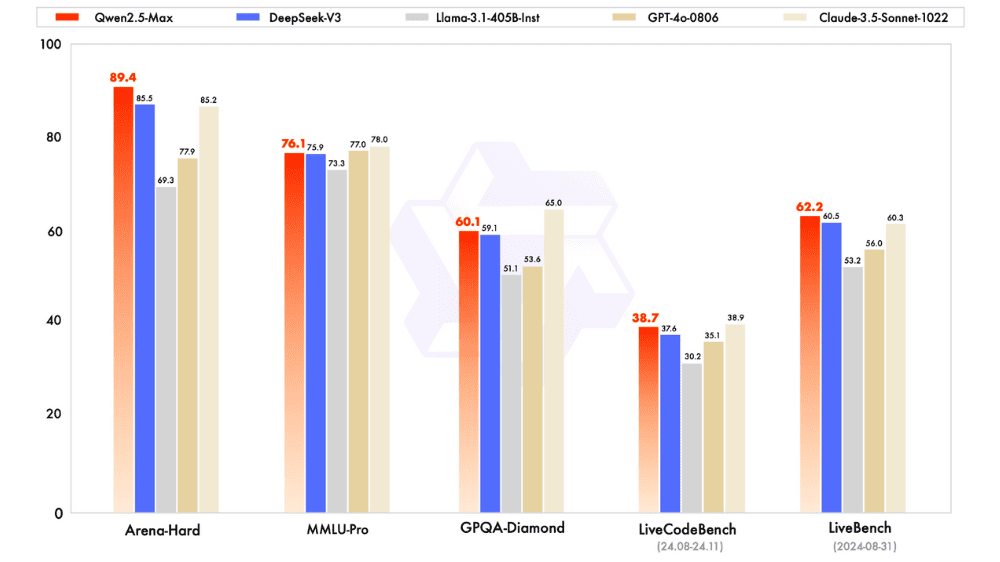
「Qwen2.5-Max」について一言
かなりテクニカルな内容ですが、DeepSeekで周辺が騒がしいことになっている中国勢(Alibaba)の最新モデルでMoEという手法を採用しています。モデル内で必要に応じて専門家を切り替えるMoE方式は、高い性能と計算効率を両立できる手法として注目を集めています。MoEはタスクに応じてモデルの中で活用する部分を使い分けることに特徴がありますが、その割り振りに課題が残存するためノウハウの確立には時間を要しますが、大規模モデルの開発アプローチとして大きな可能性を持っています。
ということで開発手法については上記の通りかなり期待の持てるものですが、パフォーマンスで言うとGPT-4o、Claude-3.5-Sonnetという昨夏以前のモデルと張れる水準であり、実用面で言うとまだまだこれからといった印象を持っています。
出所:Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model