
Word2Vecとは、自然言語処理において文章内の単語をベクトル化し、単語同士の意味的な関係性を数値的に捉える技術です。この技術の特徴は、単語間の距離や類似性を数値で表現することにあります。従来の表現では単語同士の意味的なつながりを捉えることができず、単語は独立して扱われていました。しかし、Word2Vecでは、ニューラルネットワークを用いた分散表現により、単語同士の関連性を効率的に学習することにより、単語同士の加法性や文脈に基づく推論が可能となり、感情分析や文章生成、レコメンドシステム、対話型AIなど、さまざまな応用が現実のビジネスや日常のサービスで広く利用されています。

Word2Vecとは

Word2Vecとは、文章中の単語を数値ベクトルに変換し、その意味や関連性を解析するための自然言語処理技術です。単語間の関係性を効率的に捉えられる方法として広く用いられています。この技術の背後には「似た環境で使われる単語は似た意味を持つ」という仮説があり、これに基づいて単語を数値化します。
従来、単語はそれぞれ独立した存在として扱われ、関係性を無視していましたが、Word2Vecでは単語を多次元空間上のベクトルとして表現することで、単語間の意味的な「距離」や「近さ」を数値で示すことができます。例えば、「犬」と「猫」はどちらもペットとしてよく使われる単語であり、ベクトル表現にすると似た特徴を持つことが確認できます。
このベクトル表現は、商品レビューの自動分析や感情解析など、さまざまな実用的なシナリオで活用されています。ベクトルの次元数は通常50〜300程度の数値列で表され、単語の分散表現として知られています。Word2Vecでは、ニューラルネットワークを使って単語の使われ方を学習し、似た使われ方をする単語は似たベクトルとして表現されます。
また、Word2Vecでは加法性と呼ばれる特徴もあり、例えば「王」から「男」を引き、「女」を足すと「女王」という単語を導き出すことができ、単語の意味や文脈に基づいた推論が可能となり、自然言語処理の精度を大幅に向上させています。
自然言語処理の手法のうち、単語をベクトルで表現する代表的な手法にはone-hot表現と分散表現の2つがあり、Word2Vecの意味ベクトルは分散表現に該当し、分散表現を使うことで単語の意味を数値的に表現し、さまざまな応用が可能です。
| 感情分析 | 例えば、心理学者ポール・エクマンが提唱した怒り、嫌悪、恐れ、幸福、悲しみ、驚きという6つの基本感情と文章内の単語のベクトルを比較し、文章がどの感情に近いかを数値的に推測して、文章に込められた筆者の感情を自動的に解析することができます。 |
| 単語の演算処理 | Word2Vecは単語を実数値ベクトルで表現するため、単語間の演算が可能です。単語同士の意味的な関係を数値的に表現し、新たな意味を推測することができます。 |
| 文章生成 | Word2Vecは再帰型ニューラルネットワーク(RNN)と組み合わせることで、文章の自動生成も可能です。例えば、夏目漱石の文章を学習させると、似た作風の新しい文章を生成することができます。 |
| 文章要約 | 主要な情報を抽出し、簡潔な形で提供することで、読者が素早く重要な内容を理解できるようにするために使われています。長文のニュースやレポートの要約に活用され、多くのアプリケーションで利用されています。 |
one-hot表現

One-hot表現とは、K次元のベクトルで1つの要素だけが1になり、他のすべての要素が0であるベクトル形式のことを指します。この形式は、自然言語処理や機械学習の分野で広く使われており、特にクラス分類の問題でよく利用されます。例えば、コンピュータビジョンの物体認識において、クラスの正解ラベルを表すために使われることがよくあります。
自然言語処理でも、one-hot表現を用いて単語を数値化します。例えば、単語に犬、猫、鳥が含まれている場合、犬は[1,0,0]、猫は[0,1,0]といった形で表現します。one-hot表現では単語ごとに専用のベクトルが与えられますが、次元数が増えるとベクトルのサイズが急激に大きくなるという欠点があります。例えば、文章に1万語が含まれている場合、ベクトルの次元数は1万にもなり、効率的な計算が難しくなります。
さらに、one-hot表現ではベクトル間の距離や関係性を直接計算できないという課題があります。例えば、犬と猫がどれだけ似ているかを測ることはできず、各単語は独立して扱われるため、意味の類似性を捉えることができません。そのため、より高度な表現方法が必要になる場面が出てきます。
分散表現
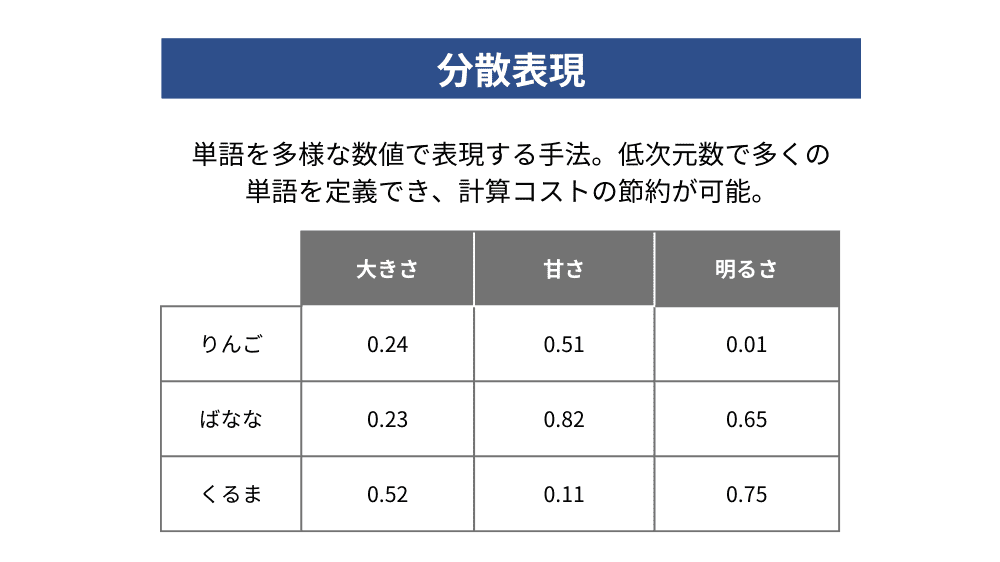
分散表現とは、単語を数百次元のベクトルで表現する手法です。
例えば、分散表現では猫は[0.23, 0.34, 0.56]のような実数値を使って表すことになります。one-hot表現と異なり、ベクトルの値が0か1ではなく、実数値になることが特徴です。
この分散表現の大きな特徴は、単語間の演算が可能になる点です。例えば、犬と猫のベクトル間の距離を計算することで、2つの単語がどれだけ似ているかを定量的に評価でき、意味的に近い単語を捉えることができるようになります。
さらに、分散表現では各単語を数百次元のベクトルで表現するため、one-hot表現に比べてデータの次元数を大幅に削減できます。文章中に多くの単語が含まれていても、効率的に処理できる点が分散表現の強みです。分散表現はone-hot表現の欠点を克服し、単語の意味をより正確に捉えるための効果的な手法として広く利用されています。
Word2Vecの仕組み
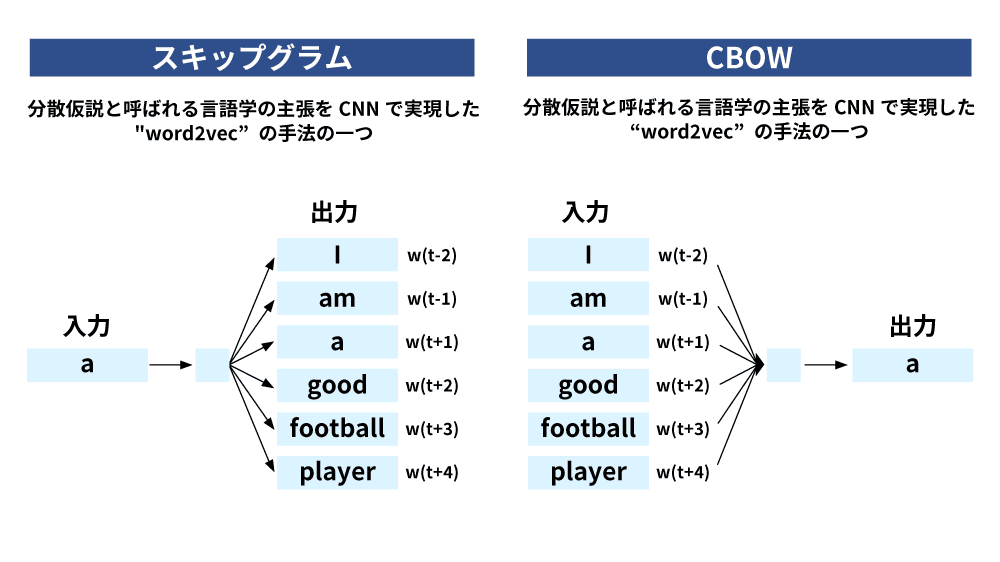
Word2Vecの仕組みについて、Skip-gramモデルとCBOW(Continuous Bag of Words)モデルにはそれぞれ異なる特徴があります。
Skip-gramモデルは中心の単語から周辺単語を予測することで学習を行います。この方法では低頻度の単語に対しても効果的な学習が可能で、単語間の細かな意味の違いを捉えることができますが、学習速度が比較的遅く、より大きなモデルサイズを必要とします。
一方、CBOWモデルは周辺の複数の単語から中心の単語を予測するというアプローチを取ります。このモデルは高速で、小規模なデータセットでも良好な結果が得られやすく、頻出する単語に対して特に効果的です。
どちらのモデルを使用するかは、データセットの規模やタスクの目的に応じて選択されます。Skip-gramはより高精度な意味解析に向いており、CBOWは高速な処理が求められる場合に適しています。
| Skip-gram | CBOW | |
| 予測の方向 | 中心の単語から周辺単語を予測 | 周辺単語から中心の単語を予測 |
| 学習速度 | 遅い | 速い |
| 低頻度語の扱い | 低頻度語に対して効果的 | 高頻度語に対して効果的 |
| 精度 | 高精度 | やや劣る |
| データサイズ | 大規模データセットで効果的 | 小規模データセットでも良好 |
| 意味の捕捉 | 細かな意味の違いを捉える | 全体的な文脈を捉える |
| モデルサイズ | 大きい | 小さい |
Word2Vecの特徴
単語間の意味的関係の捕捉
Word2Vecの最も重要な特徴は単語間の意味的関係を数値的に表現できる点です。単語をベクトル空間上の点として表現することで、単語同士の類似性や関係性を数値化することができます。
例えば、「王様」から「男性」を引き「女性」を足すと「女王」という結果を得られるなど、直感的な意味の演算が可能で、類義語の発見やアナロジー推論、感情分析といったタスクに応用されています。実際にAmazonのレコメンドシステムでは、Word2Vecを活用して顧客に合った商品提案を行っています。
高速処理
Word2Vecは高速な処理能力と効率的なメモリ使用が特徴です。モデルの構造がシンプルで計算量が少ないため、大規模なテキストデータを短時間で処理でき、大規模なデータセットでも実用的です。また、100万語の語彙を300次元のベクトルで表現しても必要なメモリ量は数ギガバイト程度に抑えられるため実用性が高く、Googleの検索エンジンでもWord2Vecを利用して関連性の高い検索結果を素早く提供しています。
教師なし学習による柔軟性
Word2Vecは教師なし学習によって単語の分散表現を獲得できます。ラベル付けされたデータを必要とせず、生のテキストデータから自動的に学習できるため、多様な分野や言語に適用可能です。
例えば、医療分野では論文データを使ってWord2Vecを学習させ、医学用語間の関係を捉えることで診断支援システムの精度向上に役立てています。また、複数言語のデータを同時に学習させることで、機械翻訳にも応用でき、言語間の対応関係を学習して翻訳精度の向上に貢献しています。
Word2Vecの活用事例
対話型AI
チャットボットやボイスアシスタントなどの対話型AIでは自然な会話を実現するために活用されています。例えば、顧客対応やカスタマーサポートにおいて、単語やフレーズの意味をベクトルで表現し、リアルタイムで適切な応答を生成することで、顧客体験の向上や効率的な情報提供ができます。対話型AIはユーザーの質問に応じた自然な会話の流れを作り出すため、エンターテイメントや教育分野でも活用されています。
レコメンドシステム
ユーザーの行動や嗜好に基づいて商品やコンテンツを推薦するレコメンドシステムにも応用されています。例えば、オンラインショッピングや音楽ストリーミングサービスにおいて、ユーザーの過去の閲覧履歴や購入履歴をベクトル化し、類似度の高い商品や楽曲を推薦します。ユーザーが新しい商品やサービスを発見しやすくなり、エンゲージメントやコンバージョン率の向上が期待できます。Word2Vecは単純なキーワードマッチングに留まらず、深い意味的な類似性に基づいたレコメンドを行うため、パーソナライズされた体験を提供します。
レビュー分析
商品やサービスに対する口コミやレビューの分析にも役立ちます。テキストデータから感情やトレンドを抽出し、企業が顧客満足度の向上や商品改善に取り組むための洞察を提供します。例えば、大量のレビューを自動的に解析し、ポジティブな感想や改善が求められている点を特定することで効率的なフィードバックループを形成でき、企業は顧客ニーズに迅速に対応できるようになります。
機械翻訳
Word2Vecは、異なる言語間の単語の関連性を捉えることができるため、機械翻訳にも応用されています。Word2Vecによって単語の意味がベクトルとして表現され、これを基にして異なる言語間での翻訳が行われます。これにより、翻訳精度が向上し、グローバルなビジネスや教育において言語の壁を越えたコミュニケーションが実現されています。Word2Vecは、機械翻訳の分野で大きな進展をもたらし、異なる文化や言語をつなげる技術として重要な役割を果たしています。
質疑応答システム
質疑応答システムにも幅広く活用されています。企業のQ&Aシステムに導入することで、顧客が質問した内容に対して、的確で自然な返答が可能になります。例えば、FAQシステムではユーザーが入力した質問をベクトル化し、その質問に関連する回答を素早く提供でき、カスタマーサポートの効率が向上し、顧客満足度が向上します。
検索エンジンの関連性向上
検索エンジンの精度を高めるためにも利用されています。ユーザーの検索クエリをベクトル化し、意味的に関連する情報を検索結果として提供することで、従来の単語一致に依存する検索システムよりも精度の高い結果を提供できます。例えば、「人工知能」と検索した場合、「機械学習」や「ニューラルネットワーク」といった関連トピックも表示されるため、ユーザーは効率的に情報を得ることができます。
Word2Vecの課題
未知の単語への対応
Word2Vecの主要な課題の1つには新しい単語や未知の単語への対応があります。学習データに含まれる単語のみをベクトル化するため、学習後に登場した新しい単語や学習データに含まれていなかった稀少な単語を適切に処理することができません。たとえば、急速に進化するテクノロジーの分野で頻繁に使われる「ブロックチェーン」や「量子コンピューティング」といった単語が学習データに含まれていない場合にはベクトル化することが困難です。
文脈の長期依存性の捉えにくさ
Word2Vecは単語の局所的な文脈を捉えることは得意ですが、文章全体や段落レベルの長期的な文脈を適切に処理することや文脈に依存した複雑な意味の解釈は苦手です。
多義語の扱いの難しさ
Word2Vecは1つの単語に対して1つのベクトルを割り当てるため、多義語の異なる意味を区別することができません。例えば、医療分野では「オペレーション」という単語が「手術」と「作業」の両方を意味しますが、Word2Vecではこの区別をつけることができません。この問題に対処するために、文脈に基づいた動的な単語表現を生成するBERTやELMoのようなモデルが研究されています。
大量のテキストデータの必要性
Word2Vecは大量のテキストデータを使って学習を行うため大量の学習データが必要です。小規模なデータセットでは語彙が限られ、稀少な単語や特殊な用法を学習できない可能性がありますが、大規模データセットでは誤字やノイズの影響を軽減できるため精度の向上が期待できます。小規模なデータセットでの限界に対しては、事前学習されたモデルを使用し、ファインチューニングを行うことが有効です。
単語の順序や優先度を無視する
Word2Vecは単語の順序や優先度を考慮しないという制約があります。たとえば、「猫が犬を追いかける」と「犬が猫を追いかける」は全く意味の違う文章ですが、Word2Vecでは順序を考慮しないため同じように扱われてしまいます。単語の出現頻度に基づいてベクトルが生成されるため、文脈や単語の順序が無視されてしまうのです。この課題を解決するためには、文脈や順序を考慮したモデルを使用する必要があります。
対義語に対応できない
Word2Vecは対義語の区別ができません。たとえば、「明るい」と「暗い」という対義語は文脈上では似た構造を持つため、Word2Vecでは適切に区別できないことがあります。対義語が重要なタスクにおいては、他のアプローチを考える必要があります。
アウト・オブ・ボキャブラリー問題 (OOV)
Word2Vecは学習データに含まれていない単語に対してベクトル表現を生成することができません。この問題は新しい単語や専門用語に対しても適用されOOV問題と呼ばれます。OOV問題を解決するためには定期的にモデルを更新したり、サブワード情報を利用する技術が有効です。
固定次元のベクトル
Word2Vecでは単語が固定次元のベクトルで表現されますが、すべての単語や表現を適切に捉えることが難しくなる場合があります。新しい単語やフレーズが登場した場合は再学習が必要になる点も課題です。
データのスパース性
データのスパース性(データの特徴を決定づける要素が少ないという性質)はWord2Vecでは一般的な問題です。トレーニングデータに登場する頻度が少ない単語は正確なベクトル表現が得られにくく、レアな単語や専門用語の場合、この問題が顕著に現れます。
最後に
Word2Vecは自然言語処理において単語同士の意味的な関係を数値的に表現できる点で従来のone-hot表現と比較して大きな進化を遂げた技術です。特に、単語間の距離を計算することで、意味的な類似性を捉えたり、単語の加法性による推論が可能となるなど、文章理解や情報検索において高い精度を実現しています。Skip-gramモデルとCBOWモデルの2つのアプローチにより、処理の高速化や低頻度語の扱いなど、タスクに応じた柔軟な選択が可能である点もWord2Vecの大きな特徴です。
また、商品レビューの分析や感情の自動解析、さらにはレコメンドシステムや対話型AIの自然な応答生成にも活用されており、さまざまな分野でその有用性が証明されていますが、未知の単語への対応や文脈を超えた解釈が難しいという課題もあり、対義語の処理や多義語の扱いなど、いくつかの技術的制約が残っています。それでもなお、自然言語処理の重要な基盤として、引き続き進化を続けていく技術であることは間違いありません。







