
教師なし学習とは、正解ラベルが存在しないデータを使って、コンピュータが自らパターンや特徴を学び取る手法を指します。これは、従来の教師あり学習と異なり、データに正解が与えられていないため、分類や予測の精度を高めることよりも、データの構造や規則性を発見することに主眼が置かれています。教師なし学習では、膨大なデータセットから隠れたパターンを見つけ出す際に特に有効で、クラスタリングや次元削減、異常検知、生成モデルなどさまざまな分野で活用されています。

教師なし学習とは
教師なし学習(Unsupervised Learning)とは、コンピュータに正解を与えずにデータから規則性や特徴を見つけ出す手法です。コンピュータは入力データのみを読み込み、データの共通項や頻出性を基に分類や構造の抽出を行います。教師あり学習とは異なり、正解となるラベルやデータが存在しないため、予測や分類の問題には直接対応できませんが、データの構造分析や特徴抽出に適しています。
代表的な手法には、クラスタリングや次元削減があり、これらはデータをグループ分けしたり、本質的な特徴を簡略化する際に用いられます。クラスタリングでは、データの特徴を基に自動的にグループを作成し、次元削減では、データの次元数を減らしつつ重要な情報を抽出します。教師なし学習は、正解が明確に存在しないデータに対しても適用可能で、規則性やパターンを自動的に発見するため、膨大なデータセットに対する分析において特に有効です。
機械学習の種類
教師なし学習は、データに正解ラベルを与えずに学習を進め、データの構造や法則性をコンピュータが自動で解析する手法で、新製品のターゲット市場のように正解データが存在しないケースに適しています。教師なし学習の目的は、データを分類したりパターンを見つけ出すことや未知のデータを体系的にまとめることです。
一方、機械学習には他にも教師あり学習や強化学習などの手法があります。教師あり学習では、あらかじめ正解となるラベルが付いたデータを使って学習することで、新しいデータに対しても高精度に正解を予測できるようになります。ただし、正解データを大量に準備する必要があり、手間とコストがかかります。また、強化学習では、コンピュータが自らの行動に対して報酬を設定し、報酬を最大化するように学習します。ゲームや自動運転など、最適な行動を探す際に用いられる手法です。
近年では半教師あり学習という手法も注目されています。半教師あり学習とは正解ラベルがついているデータとついていないデータの両方を使用する方法で正解データが不足している場合に役立ちます。まず、一部の正解ラベル付きデータで予測を行い、その後で全データを統合して学習します。
これらの手法は、それぞれ目的に応じて使い分けられます。正解を予測したい場合は教師あり学習、データの新しいグループ分けを発見したい場合は教師なし学習、正解データが不足している場合は半教師あり学習、最適な行動を求める場合は強化学習が選ばれます。
教師なし学習を利用する目的
教師なし学習の目的は、データ内にある未知のパターンを見つけ出すことです。正解が存在しない問題に対して、クラスタリングや次元削減を活用し、データからパターンやグループを自動で抽出します。特に、新製品のターゲット市場のように正解データがない場合に有効ですが、得られる結果が必ずしも正しいとは限りません。そのため、正解が求められる場面では、教師あり学習の方が適していることが多いのが実情です。
教師なし学習のメリットとデメリット
教師なし学習は柔軟性があり、多くのメリットを持ちますが、解釈が難しく評価しづらい点がデメリットです。
教師なし学習のメリットとしては次のようなものがあります。
- ラベル不要:データに正解ラベルを付ける必要がないため、ラベル付けのコストや時間がかからない
- 新しいパターンの発見:データ内の隠れた構造やパターンを自動的に発見し、新しい知見を得ることができる
- 探索的データ分析:データの初期探索や未知のデータセットに対しても有用で、事前の知識が少なくても適用できる
- スケーラビリティ:大規模なデータセットにも対応でき、データ量が多いほど複雑なパターンの発見が期待できる
- 効率的な分析:ラベル付け不要で開始しやすく、教師あり学習に比べて効率的に学習できる場合がある
また、教師なし学習のデメリットとしては次のようなものが挙げられます。
- 結果の解釈が難しい:得られた結果やパターンの解釈が困難で、専門的な知識が必要となる場合がある
- 評価の困難さ:ラベルがないため、モデルの性能評価が難しく、客観的な基準が不足する傾向にある
- クラスタ数やパラメータの選択が難しい:適切なクラスタ数やパラメータの選定に試行錯誤が必要で、結果に大きな影響を与えることがある
- ノイズに敏感:データセットにノイズが多いと正確なパターンの抽出が難しくなる
- 前処理が重要:データの前処理や正規化が不十分だと不適切な結果になる
- 適用範囲の制限:回帰や分類などの問題には直接適用できず、解釈や追加の処理が必要になる
教師なし学習の種類
クラスタリング(k-means、ウォード法)
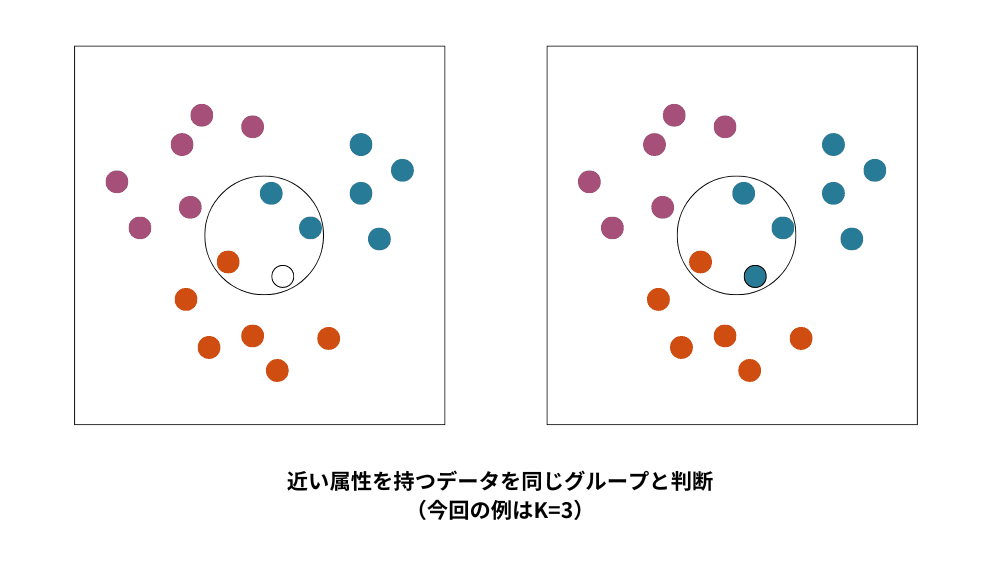
クラスタリング(クラスタ分析、データクラスタリング)とはデータ間の類似度に基づいてデータをグループ分けする手法で、主に階層なしクラスタリング(k-means)と階層ありクラスタリング(ウォード法)に分けられます。階層なしクラスタリングは事前にグループ数を決める必要がありますが、大規模なデータにも対応可能です。階層ありクラスタリングは類似したデータを樹形図でまとめる方法で、データ量が多いと計算負荷が高くなります。また、1つのグループだけに所属させる方法をハードクラスタリング、複数グループへの所属を許容する方法をソフトクラスタリングと呼びます。
なお、分類とクラスタリングの違いは学習データにあらかじめ答えがあるかどうかにあります。分類は未知のデータがどのグループに属するか、あらかじめ答えが存在し、答えに基づいて予測を行います。一方、クラスタリングは答えがないデータから特徴を学習し、類似性に基づいてデータをグループ分けすることを指します。分類は既存の答えに基づいてグループ分けを行い、クラスタリングは未知のデータからパターンを発見してグループ化します。
アソシエーション分析
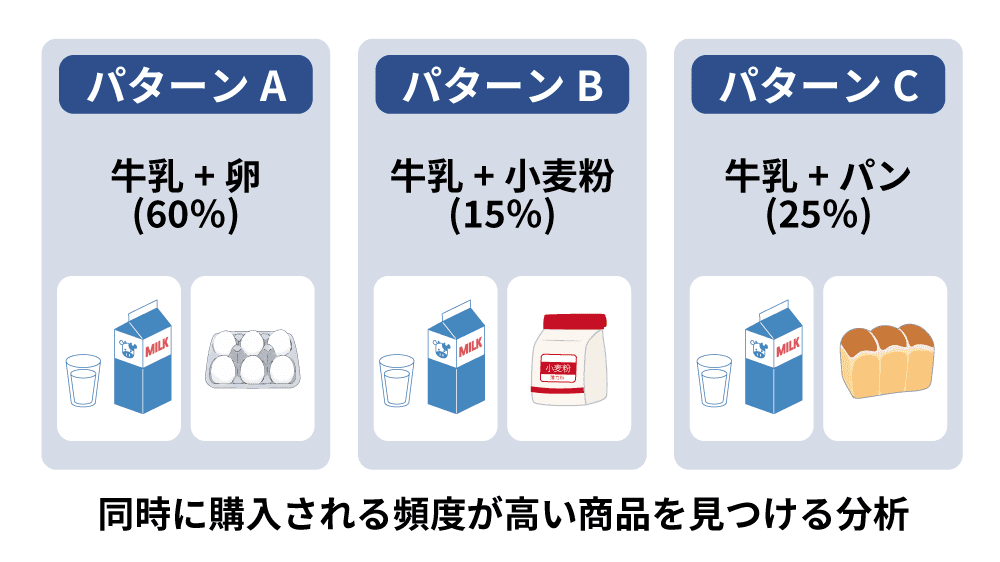
アソシエーション分析は、データ間の関連性を発見する手法で、教師なし学習の一種です。たとえば、「雨の日に傘とレインコートがよく売れる」といった関連性を見つけることができます。売上施策の効果を分析し、どの施策が最も売上に貢献したかを評価する際にも活用できます。
主成分分析(PCA)
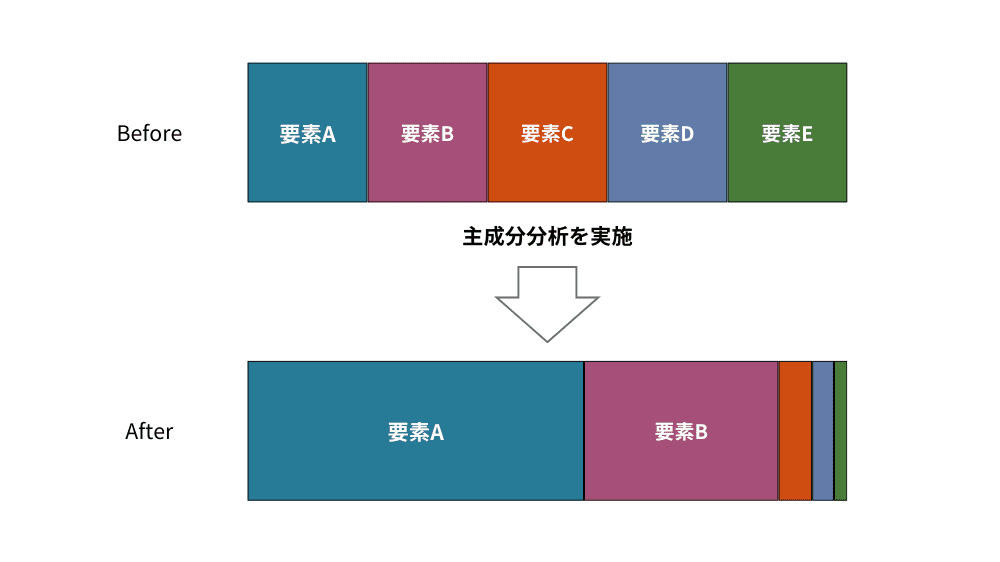
主成分分析は多種類のデータを集約し、情報を簡略化して表現する手法です。教師なし学習の一種で、たとえば甘み、苦味、酸味などのデータを集約し、総合的な味覚の評価への影響の大きい変数を導き出すことができます。元の情報をできるだけ保持しつつ、データを圧縮して扱えるため、アンケート結果の総合評価を算出する際などに活用されます。ただし、集約されたデータの解釈は人が行う必要があります。
GAN(敵対的生成ネットワーク)
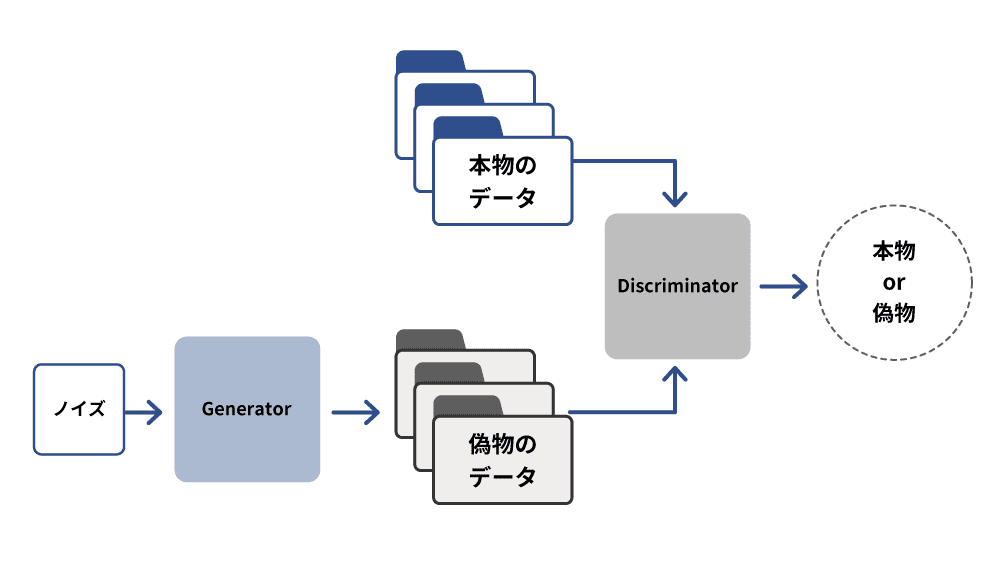
GAN(敵対的生成ネットワーク)は、Generator(生成者)とDiscriminator(判定者)の2つのネットワークが競い合いながら学習する手法です。Generatorは新しい画像を生成し、Discriminatorはその画像が訓練データか生成されたものかを判定します。このプロセスを繰り返すことで、Generatorがよりリアルなデータを生成できるようになります。GANは画像生成に強みを持ち、画像の高画質化や音声生成などにも応用されており、教師なし学習の1つとして注目され、さまざまな領域での発展が期待されています。
自己教師あり学習
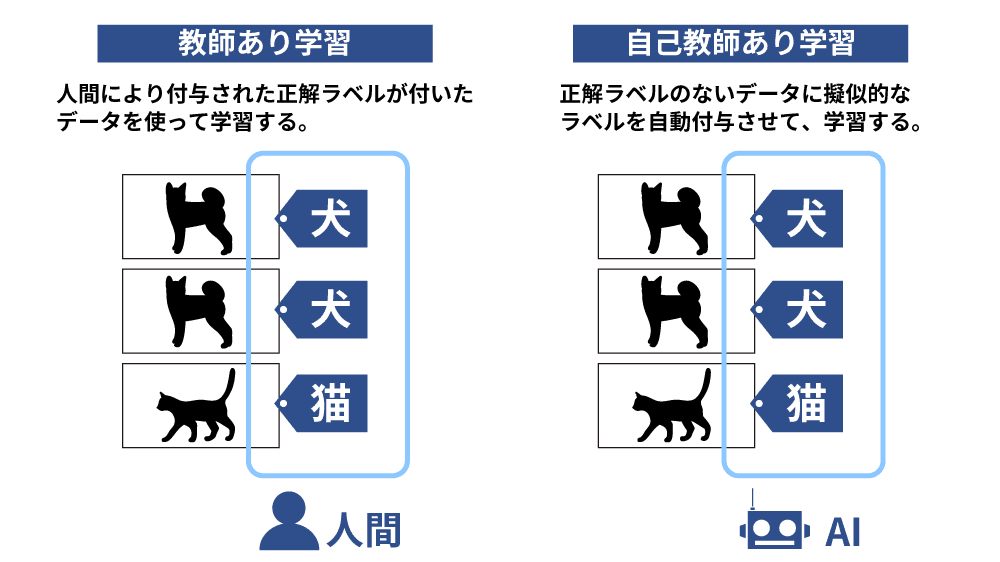
自己教師あり学習(Self-Supervised Learning, SSL)は、入力データから自動的にラベルを作成して学習する手法です。教師あり学習のように大量のラベル付きデータを必要とせず、アノテーションコストを大幅に削減できる点が特徴です。

教師なし学習の応用例
購買データの分析
教師なし学習は、スーパーマーケットなどでの購買データ分析にも活用されています。特に、隠れた購買パターンを発見し、顧客の購買傾向を分析するのに適しています。これにより、商品の配置改善やマーケティング戦略の最適化が可能になります。
レコメンドシステム
教師なし学習を使ったレコメンドシステムは、ユーザーの行動や好みに基づいて商品やサービスを提案します。オンラインショッピングや動画配信サービスで導入されており、顧客満足度の向上や売上の増加に寄与しています。
異常検知
教師なし学習は、大量のデータから異常なデータを検出する「異常検知」にも活用されています。この技術は、故障検知や不正使用検知として使われることもあり、非構造化データ(メール、文書、画像など)の分析に特に有効です。ビジネスの現場で活用するためには、データ分析の知識や経験が求められます。
参考:Can you handle the tooth? AI helps dentists design fake gnashers(The register)
自動運転AIの画像認識
自動運転の分野では、教師なし学習が注目されています。膨大なデータを必要とする教師あり学習に対して、教師なし学習はデータに正解・不正解のラベルをつける必要がないため、コストと時間の削減が可能です。
スタートアップ企業Helm.aiは、この技術を用いた自動運転向けソフトウェアを開発し、高い評価を得ています。
参考:教師は不要: Helm.ai、目指すは自動運転車開発の効率化(NVIDIA)
画像生成
教師なし学習は、画像生成の分野でも応用されています。ぼやけた写真や白黒写真から高品質な画像を生成したり、自動で画像を加工する技術として利用されています。これにより、オリジナルの画像データが不足している場合でも、高品質な結果を得られるようになっています。
人工歯のデザイン
カリフォルニア大学バークレー校とGlidewell Dental Labが共同で、GAN(敵対的生成ネットワーク)を用いて人工歯のデザインを開発しました。従来は歯科医が時間をかけて個別に調整していた人工歯を、GANにより自動生成することで、より適切な噛み合わせを実現できることが確認されています。
最後に
教師なし学習は、データに正解ラベルを付ける必要がないため、探索的データ分析やパターン発見に優れたアプローチです。この手法ではクラスタリングや次元削減などを通じてデータの特徴や規則性を自動で抽出し、ラベルなしのデータからも重要な知見を得られる可能性があります。ただし、結果の解釈が難しく、評価基準が曖昧になりやすいというデメリットも存在します。教師なし学習は、データが大量かつ複雑な場合でも、その柔軟性やスケーラビリティによって、データ構造を明らかにし、新しい洞察を提供する重要なツールです。







