
サポートベクターマシン(SVM)とは、教師あり学習における分類タスクで使用される機械学習アルゴリズムの1つです。データを最適に分類するために、マージンを最大化する超平面を見つけることを目的とし、高い汎化性能を発揮します。少ないデータでも精度の高い分類が可能で、非線形な分類問題にも対応できる柔軟性が特徴です。カーネルトリックを活用することで低次元では分類できないデータでも高次元に拡張し、精度を高めることができますが、大規模データに対する計算コストの増大や、スケーリングの必要性といった課題も存在します。

サポートベクターマシン(SVM)とは
サポートベクターマシン(SVM)は、教師あり学習における分類タスクで主に使用される機械学習アルゴリズムの1つです。データを最適に分類するために、データを分割する直線や超平面を見つけ、そのマージン(データと直線または超平面との距離)を最大化することを目指します。このマージンの最大化が、SVMの高い汎化性能を支える重要な要素となっています。
SVMは、少ない教師データでも効率的に学習できる点が特徴で、未知のデータに対しても高い精度を発揮します。また、非線形な分類問題にも対応可能で、広範囲にわたる問題に応用されています。2000年から2010年頃にかけて特に注目を集めていましたが、現在もPythonなどのライブラリを通じて多くのシーンで活用されています。
機械学習とサポートベクターマシン
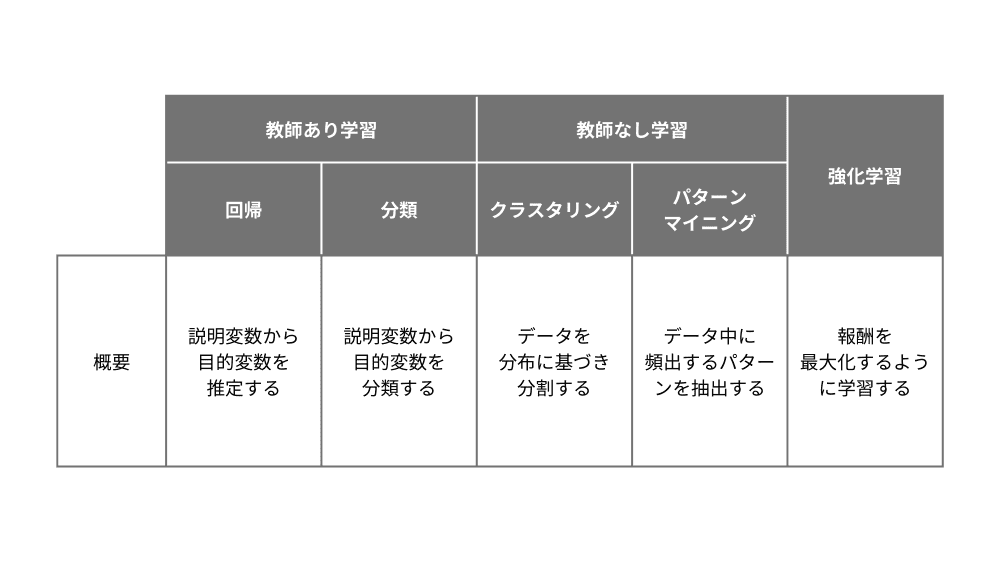
AIによる機械学習は大きく次の3つに分類されます。
- 教師あり学習
- 教師なし学習
- 強化学習
このうち、サポートベクターマシンは教師あり学習の分類に該当します。特に、2つの選択肢を用いる2値分類はサポートベクターマシンの得意分野の1つで、2値分類のアルゴリズムを複数並べた多値分類にも対応しています。分類に比べると頻度は少ないものの、教師あり学習の「回帰(数値の予測)」へも応用可能で、サポートベクター回帰(SVR)と呼びます。

マージンの最大化
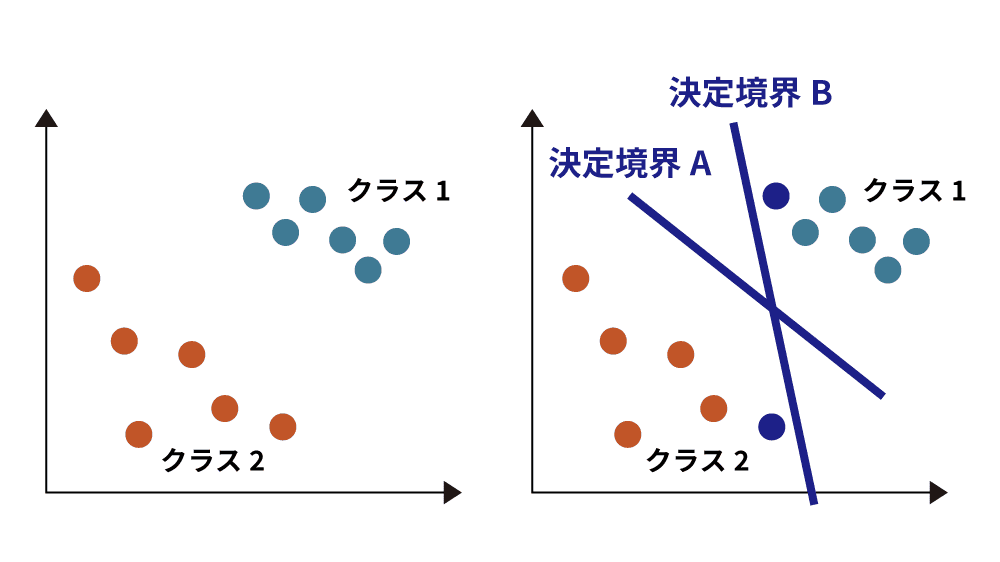
機械学習の分類問題では、各々のクラス間に境目となる直線や超平面(決定境界)を引くことで分類をします。左図のようなクラスがあったとき、決定境界AとBを引いた場合にはAの方がより正確に分類できているといえます。これは決定境界Bでは近すぎる点が存在するためです。
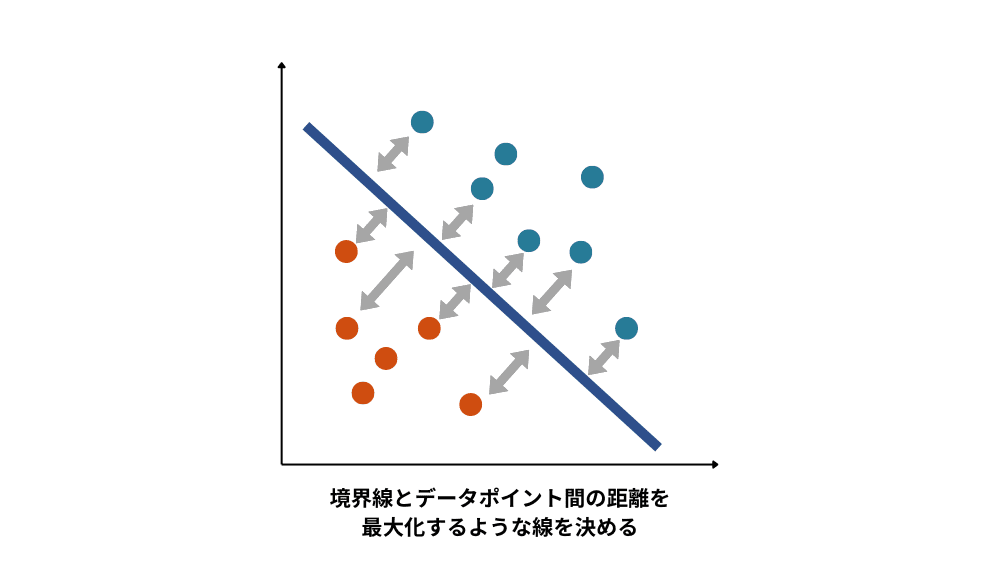
このように、マージン(クラスの分類基準となる境界と各データとの距離のこと)が最大化になるように学習するアルゴリズムのことをサポートベクターマシンと呼びます。
カーネルトリックとは
サポートベクターマシンでは直線や超平面によりデータを分類しますが、現実的な分類ではデータが入り乱れて配置されることもあるため、必ずしも直線や平面により分類できるわけではありません。そのため、元の空間から高次元の空間へとデータを写像し、拡張した高次元空間で分離を行う方法をカーネルトリック(カーネル法)と呼びます。具体的には、直接高次元空間で計算するのではなく、特定のカーネル関数を用いることで、元の空間のままで計算を行います。
一般的な次元拡張では計算量が膨大になり、計算も複雑になる傾向が強いのですが、カーネルトリックを使った方法では難しい計算を回避して実行することができます。
サポートベクターマシン(SVM)のメリット
サポートベクターマシンのメリットは過学習が起こりにくく、識別精度が高いことが挙げられます。
一般的な機械学習方法で分類する場合、データを完全に分類することを目指すため、学習データに極度にフィットさせようとして結果、過学習が起こります(訓練データのみに最適化すること)。しかし、サポートベクターマシンの場合ではマージンの最大化が目的であり、データを完全に分類することが目的になっているわけではありません。そのため、過学習のリスクが少なく、誤検知が起こりにくいというメリットがあります。
また、カーネルトリックを使うことで低次元では識別できなかったようなデータであっても、高次元にすることで高い精度で分類できることが大きな特徴です。

サポートベクターマシンの課題
計算コストと効率化
サポートベクターマシンは、データが増えると計算量が急激に増加し、大規模データに対して非効率になる場合があります。特に非線形データが多い実際のケースでは、データ数の増加とともに計算コストが指数関数的に上がり、大規模データの処理が困難です。中小規模のデータには向いていますが、10万を超えるサンプルを持つ大規模データには適応が難しいとされています。
また、計算コストも大きな課題です。解決のために分散処理による学習の高速化や近似アルゴリズム、カーネル関数(カーネルトリックを実装するための関数)の近似手法が開発されていますが、計算コストを抑える反面、分類精度が低下するリスクもあるためバランスが求められます。
スケーリングの実施
サポートベクターマシンは特徴量のスケールに敏感なため、データのスケーリングが必要となる場合があります。スケーリングとはデータの範囲を調整することで、例えば身長や体重といった異なる属性データの幅を0〜1のような共通の尺度に調整することを言います。スケーリングを行わないと異なるスケールのデータが正常に処理されず、結果に影響を及ぼす可能性が高く、カーネルトリックを使う場合にはスケーリングが欠かせない前処理です。
カーネル関数の設計
また、カーネル関数の選択に大きく依存するため、データの特性に合ったカーネル関数を選択し、パラメータを適切に調整することが重要です。複数のカーネル関数を組み合わせた複合カーネルやカーネル関数の設計も有効です。
他の機械学習手法との比較
サポートベクターマシンは少ないサンプル数で効果的に学習でき、高次元データや非線形分類に強いという特徴がありますが、大規模データへの対応やカーネル関数の選択が難しいといった短所もあります。他の機械学習手法と比較すると外れ値に影響されにくい点は強みですが、計算コストや確率的な出力の難しさが課題となります。
サポートベクターマシン(SVM)の活用事例
株価の予測
株式市場において株価の予測に活用されています。過去の株価変動データを学習させ、株価が上がるか下がるかを予測することが可能です。日経平均や企業の株価のデータを用い、半年以上のデータを収集すると予測精度が向上します。
災害の予測
土砂崩れや洪水などの災害予測にも応用できるため、土地の傾斜、地質、降水量などのデータを学習させ、災害リスクの高い場所を予測することにも利用されます。被害のリスクが高い場所を特定し、事前に対策を講じることが可能です。
異常検知
製造業での製品異常検知やクレジットカードの不正取引検出にも利用されています。通常の教師あり学習に加えて、1クラス分類という教師なし学習を使うことで正常データのみを学習し、異常を検出します。
数値の認識
手書きの数字認識にも利用できるため、0〜9の手書き数字を学習させ、多値分類に拡張して識別を行います。この技術は、アンケートの集計や郵便番号の自動認識などで活用されています。
顔検出
日常生活で利用されている顔検出技術にも応用されており、画像のピクセルデータを学習し、顔の有無を識別するほか、性別や個人の識別も可能です。セキュリティや入退室管理、犯人の特定など多様な用途で使用されています。
テキストの分類
スパムメールの検出や文章のカテゴリ分類に応用され、単語やフレーズを学習させて分類できます。文章をデータとして扱う際は単語やフレーズを数値化し、数値を基に分析を行います。
最後に
サポートベクターマシンは、高い汎化性能と非線形分類への対応能力を持つ優れたアルゴリズムです。マージン最大化を通じて、少ないデータでも高い精度で分類が可能な点が大きな利点ですが、一方で、大規模データに対する計算コストの高さや、データのスケーリングが必要になるなどの課題もあります。さらに、カーネル関数の選択がモデルの性能に大きく影響するため、適切な設計と調整が求められます。データの特性を理解し、それに合ったアプローチを取ることが、サポートベクターマシンを効果的に活用する鍵となります。







