
過学習とは、機械学習においてモデルが特定のデータセットに過剰に適応し、訓練データに対しては高い精度を示すものの、未知のデータに対しては正確な予測ができなくなる現象です。この問題は、モデルの実用性を著しく損ない、新たなデータに対する信頼性を低下させる原因となります。過学習は、データの偏りやモデルの複雑さが影響し、特定のデータセットに過剰に適合してしまうことで発生します。その結果、学習時には高い精度を示すものの、実際の運用環境では適切な結果を得ることができなくなります。

過学習とは
過学習とは、機械学習において、特定のデータセットにモデルが過剰に適合してしまうことにより、学習時のデータに対しては高い精度を出すものの、未知のデータに対しては高い精度を出すことができないモデルが構築されてしまうことです。過学習が起こったモデルは実運用に耐えることができませんので、正しい予測ができるようなモデルを構築することが重要です。
AIの性能が十分でない状態に見られる特徴として、未学習と過学習があります。
- 未学習(underfitting):モデルが単純すぎて、訓練データの傾向を十分に学習できていない状態
- 適正(properly trained):求めるモデルを正しく表現している状態
- 過学習(overfitting):過剰にデータフィットしていて、未知のデータに対する予測性能が低下してしまう状態
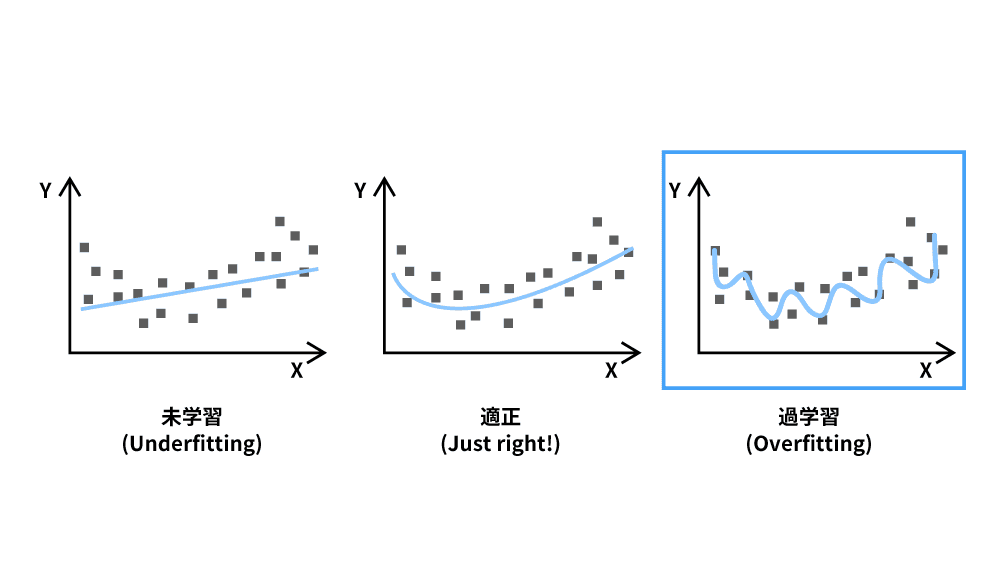
中でも過学習の状態では、データのノイズ(極端な値)や学習データにしか存在しない特徴まで過剰に捉えてしまうため、分析したい未知のデータに対して誤った予測を出してしまうことが問題点として挙げられます。
また、学習データが持つ偏りに適合してしまうため、データ全体の傾向が曖昧な状態になる結果、学習データに対する精度とテストデータに対する予測精度に大きな差が出てしまい、機械学習や分析などの目的が果たせなくなります。
過学習が起きる要因
過学習が起きる原因は、以下の4つに分けられます。
- 学習データの不足:モデルが限られたデータに過剰に適応してしまい、新しいデータへの対応が難しくなります
- 偏ったデータ:特定のパターンに偏りすぎたデータを使用することで、全体の傾向を正しく捉えられなくなります
- 目的が不明確:関連性の低いデータを学習に使うことになり、過学習のリスクが高まります
- モデルが複雑すぎる:ノイズにまで過剰に適応しやすくなり、過学習が発生しやすくなります
これらの要因を避けるためには、適切なデータ量と質、明確な目的設定、そしてモデルの複雑さのバランスが重要です。
学習データの不足
過学習は学習データが足りていないことが原因で起こります。機械学習では与えられた学習データを基にモデルを構築するため、データ数が少なすぎる場合にはすべての事例を記憶してしまい、結果的に記憶できているデータに対しては完全な予測ができるものの、学習データ外のデータに対しての精度が著しく低くなります。目的に応じたデータ分析をするためには、可能な限り多くのデータを用意し、さまざまな情報からモデルを作成できるようにする必要があります。
偏ったデータでの学習
機械学習には量が求められますが、同時に高い品質のデータも必要です。仮に十分なデータを使って学習をしたとしても偏ったデータを使っていた場合には過学習は起こります。特定の要素だけのパターンや特定のデータだけではなく、目的に沿ったデータを網羅的に学習させるなど、学習データの質の面でも配慮が必要です。
目的が不明確
機械学習の目的が明確になっていれば、必要な関連データから学習をさせて精度を上げることができますが、目的が不明確な場合には関連性の高いデータを集められなかったり、不必要なデータや偏ったデータを使ってしまったりすることで過学習のリスクが上がります。学習データには質の高いものが求められますので、必ず目的を明確にしてください。
モデルが複雑すぎる
モデルが複雑とは予測をするために使う変数(パラメータ)が多い状態のことです。変数が多いと、ノイズ(極端な値)にまで適合しようとする動きが出てくるため、変数の多さによって高度な分析ができるようになると同時に過学習のリスクも上がります。変数が少ないほうが良いとは一概にいえませんが、必要以上に複雑なモデルは避けるべきです。
過学習状態の判断方法
学習したモデルが過学習状態にあるかどうかを確認する方法はいくつかありますが、代表的な手法としては次の3つが挙げられます。
- ホールドアウト法
- 交差検証法
- 学習曲線の比較
ホールドアウト法での検証
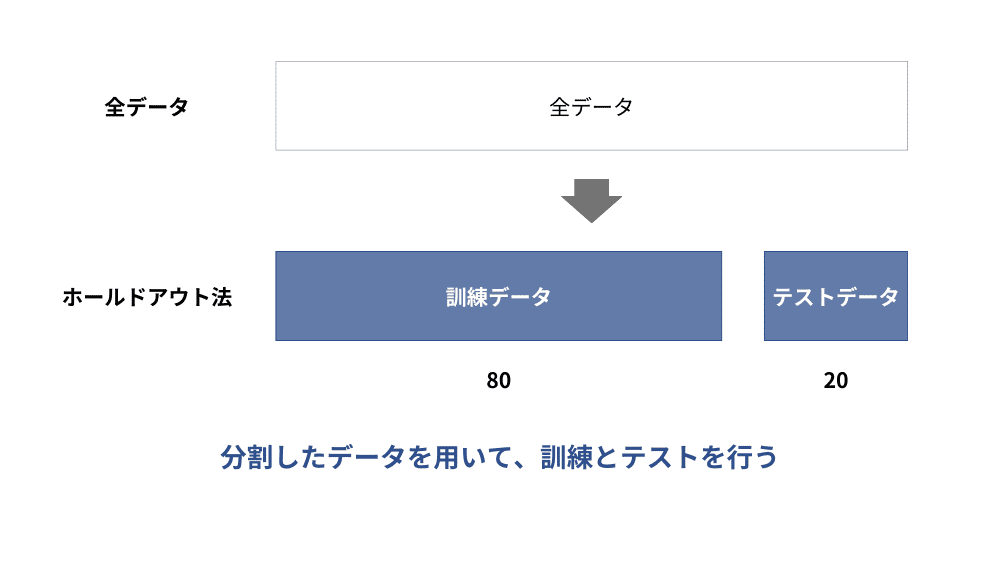
ホールドアウト法(Holdout-Method)とは、準備したデータセットを訓練データとテストデータを7:3~8:2に分け、訓練データを使って学習した後にテストデータを使ってモデルの性能をチェックすることで過学習していないかどうかを確認する手法です。
過学習のチェック方法としてはスタンダードな手法であり、簡単に実装できることとコンピュータへの負荷が小さいことが特徴です。データをランダムに分割して学習とチェックを行い、未知のデータに対する汎用性を高めることができるため過学習の起きにくいモデル構築にも役立ちます。
ただし、データの分割方法が1通りしかないため、分割がうまくいかない場合にはデータに偏りが生じ、結果的に過学習が起きてしまう可能性はあり得ます。
交差検証法での検証
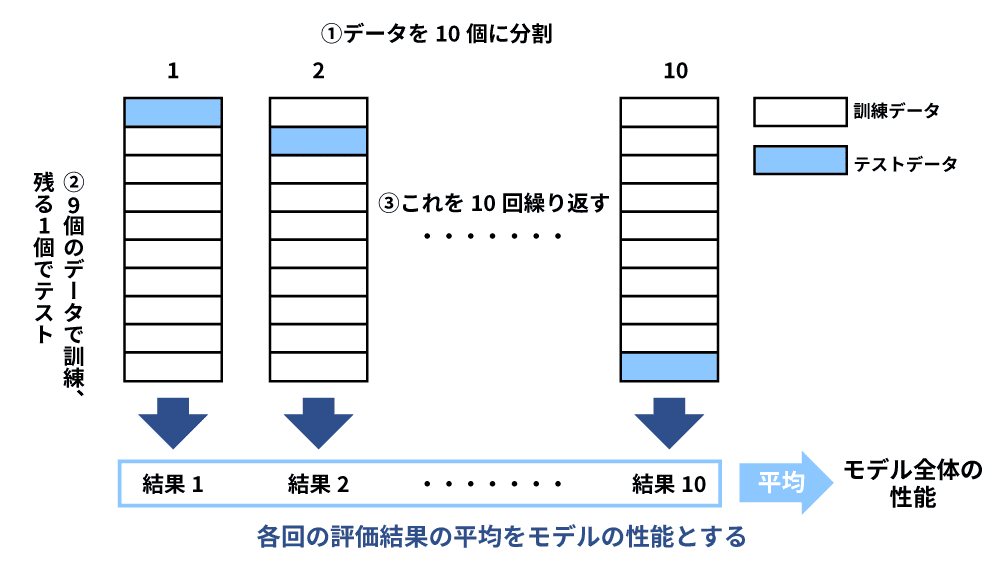
交差検証(cross-validation)法とは、準備したデータセットを訓練データとテストデータに分割して、複数の分割方法を試して全体の平均を取ることで過学習になっていないかどうかを確認する手法です。データセットを分割する点はホールドアウト法と同様ですが、1通りの分割だったものを複数の分割方法で試す点で異なります。
一般的には元データをK個に分割し、1つをテストデータに使い、残りを訓練データとしてモデル構築するK分割交差検証が使われます。データセットの重複がなく、高い精度が期待できる点が特徴ですが、K回の検証をすることになるため時間と計算負荷がかかる点に注意が必要です。例えば、Kが10の場合にはデータを10分割します。まずは9つを訓練データとしてモデルを学習させ、1つのテストデータでモデルを評価します。この訓練と評価のプロセスを異なる組み合わせで10回実施します。
また、データが少ない場合には一つ抜き交差検証(leave-one-out cross-validation、LOOCV)という手法が使われることもあります。LOOCVはK分割交差検証がK個の分割単位で訓練・評価するのに対して、データサンプルの単位で訓練・評価する方法です(K分割交差検証と比較してより細かい単位)。
学習曲線での検証
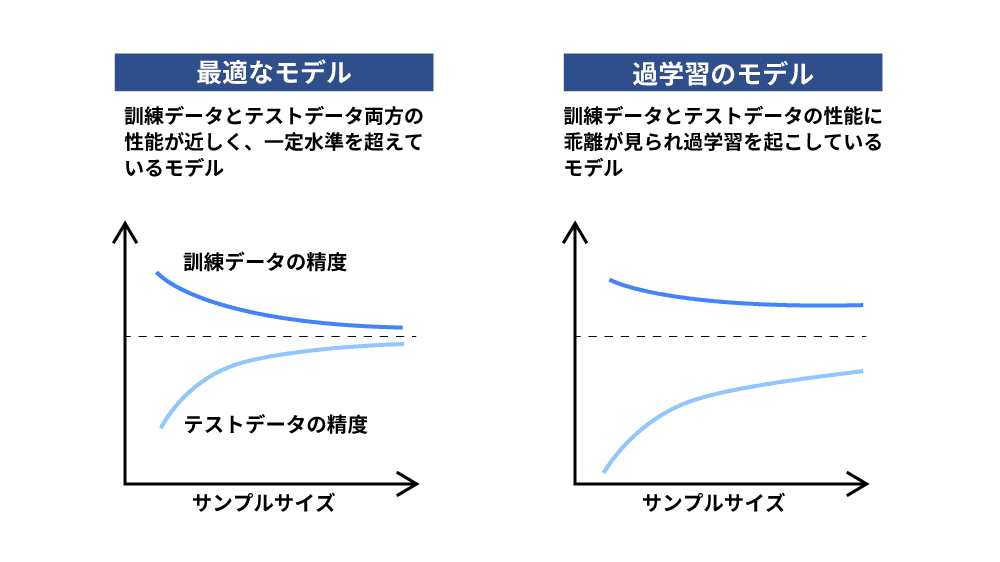
学習曲線での検証とは、訓練データでの精度と検証データでの精度を表す曲線を確認し、ギャップがどの程度あるかを確認することで過学習が起きていないかどうかを判断する方法です。
学習曲線とは、訓練データの数を横軸、評価指標を縦軸に取り、訓練データとテストデータの両方の性能の変化を表したグラフのことです。十分に学習できている状態であれば訓練データでもテストデータでも同じ精度が出るため、2つの曲線が近づきますが、曲線の差が大きい場合には予測モデルとして実運用には耐えられないということを意味しています。
過学習を避けるための対策
最適なモデルを作るためには、データの量と質を担保し、モデルの複雑さを避けることが基本です。特に学習データが少なかったり、偏ったデータが多すぎたりしても問題が起こります。学習データ量を最適化しつつ、次のような方法を取り入れることで過学習状態に陥るリスクを下げることができます。
- 正則化
- ドロップアウト
- ハイパーパラメータチューニング
- アンサンブルモデル
学習データ数の増加
学習データ数は多ければ多いほどAIの予測精度が向上します。そのため、AI開発を行う際には学習に必要なデータがどの程度なのかを確認することが必要です。データ数が少ない場合にはデータのバリエーションが少ないため、過学習になるリスクが上がります。データが少なすぎる場合にはデータの多様性担保のため、手作りでの加工や機械的なクローンデータの作成なども検討する必要が出てきます。
ただし、データは単に多ければよいというわけではありません。学習に不要な情報や項目は事前に除外し、無駄な変数を減らすことも過学習のリスクを抑えることに繋がります。
正則化
正則化(Min-Max Normalization)とは、複雑なモデルを単純なモデルへ変化させていく手法です。過学習が起きる原因の1つは、モデルが複雑すぎることですので、モデルの誤差を調整する過程で、モデルの変数の影響度が大きくならないように制約をかけることでモデルの誤差を調整する過程で、モデルの変数の影響度が大きくならないように制約をかけることでで性能の高さを維持したまま、複雑性の排除をすることができます。
正則化には主に2つの手法があります。
- L1正則化:余分な変数を減らし、重要な変数が選択される方法
- L2正則化:変数全体を小さく抑え、特定の変数が大きくなるのを防ぐ方法
L1正則化はデータ数や変数が多い場合に余計な変数を減らすことで、本当に必要な変数だけを反映させたいときに利用されます。L2正則化は複雑化させている要素を抑えることで過学習を防ぐ方法で、L1正則化を使ったモデルよりも精度が高くなる傾向にあります。
ドロップアウト
ドロップアウトは学習によるモデルの複雑化を解消し、単純な構造にする手法です。モデルは解決したい問題に合わせて作られているため、簡単に変更できないことが一般的です。そこで、確率的に必要なネットワークを選び、選定したネットワーク以外を無効化することでモデルを簡素化することができます。すべてのデータを学習するのではなく、データを部分的に選定して学習することで過学習を避けるといいかえることもできます。
ハイパーパラメータチューニング
ハイパーパラメータとは学習プロセス自体を管理する変数であり、ハイパーパラメータチューニングとは、予測モデルの自由度を決める設定を最適化することです。一例として、決定木を用いてデータ分析する場合(樹形図を用いて予測をする機械学習の手法)、樹形図の深さが決定木のハイパーパラメーターとなります。この樹形図の深さを調整することで過学習を防ぐことにつながります。
アンサンブルモデル
アンサンブルモデルとは、複数の予測モデルを組み合わせ、それぞれの予測結果に対して多数決的に予測結果を出す手法です。モデルの精度を向上させつつ、過学習を避けることができます。
アンサンブルモデルに使われる手法として主に次の3つがあります。
- バギング:複数のモデルを独立して学習させ、れらの結果を平均または多数決で組み合わせる手法
- ブースティング:複数のモデルを順次学習させ、各モデルが前のモデルの誤りを重点的に補うように訓練する手法
- スタッキング:複数の異なるモデルの予測結果を新たな2次モデルで学習し最終的な予測を行う手法
最後に
過学習は、特定のデータセットにモデルが過剰に適応し、新たなデータに対して正確な予測ができなくなる現象です。これを防ぐためには、データの量と質を適切に管理し、モデルの複雑さを抑えることが重要です。過学習の原因には、学習データの不足や偏り、目的の不明確さ、過度に複雑なモデル構造などが挙げられます。これらの問題を解決するためには、データのバリエーションを増やすことや正則化、ドロップアウト、ハイパーパラメータチューニングといった手法が有効です。また、アンサンブルモデルを活用することで、モデルの精度を保ちながら過学習のリスクを低減できます。これらの対策を講じることで、信頼性の高い機械学習モデルを構築し、実際の応用に耐えうる結果を得ることが可能になります。







