
機械学習とは、コンピュータがデータからパターンを学習し、予測や意思決定を行う技術です。日常生活で利用されている多くのアプリケーション、例えばスマートフォンの音声認識やインターネットのレコメンドシステムなどには、機械学習が活用されています。
機械学習には主に3つの種類があります。教師あり学習は、事前に正解を与えられたデータを基に予測を行う方法で、分類や回帰タスクに利用されます。教師なし学習は、正解データなしでデータ内の構造を発見する手法で、クラスタリングや次元削減に用いられます。強化学習は、試行錯誤を繰り返して最適な行動を学習する方法で、ロボット制御やゲームAIに利用されています。

機械学習とは
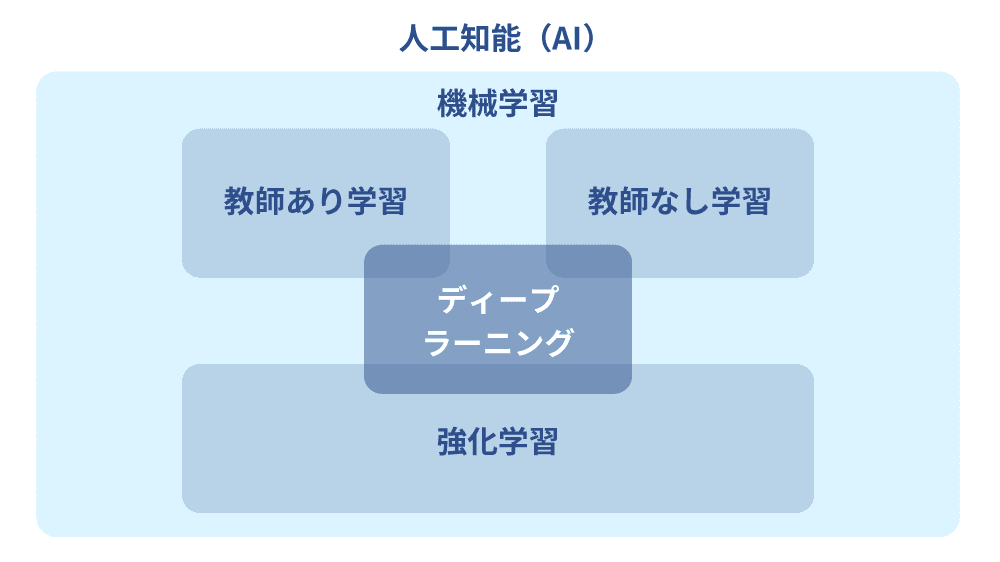
機械学習とはデータを分析する手法のことで、コンピュータが自動で学習して、データのルールやパターンを発見する方法のことです。AIの発展に伴い、学習した成果に基づいてコンピュータが予測や判断することが重要視されてくるようになりました。機械学習の関連語としてAI(人工知能)やディープラーニング(深層学習)がありますが、AIを実現するための分析技術の1つが機械学習であり、機械学習の代表的な方法の1つがディープラーニングという位置づけです。
従来の統計学的な仮説検証型のデータ分析では、データの説明はできても正しい予測までは難しかったのが実情ですが、機械学習が進むことでより高い精度の予測や新しい発見をすることができるようになりました。
機械学習はコンピュータに大量のデータを学習させ、分類や予測などのタスクを行うアルゴリズムやモデルを自動的に構築する技術ですので、膨大なデータを反復学習することになります。最終的にはデータに潜むパターンや特徴を見つけることができるようになりますが、後述する、教師あり学習、教師なし学習、強化学習の3種類の枠組みに分けて考えることができます。
機械学習と統計学の違い
統計学の分野もコンピュータの活用は日常的に行われているため機械学習と統計学の明確な違いはなくなりつつあります。しかし、統計学はデータの説明に重きを置いているのに対し、機械学習は予測に重きを置いている点で大きく異なります。言い換えると、統計学はデータの背景にあるルールを正しく説明できるかどうかを重視し、機械学習はデータを基により正しく将来予測ができるかどうかに重きを置いているといえます。
そのため、統計学では直観的に理解できる説明変数で構築されたモデルが多くなりますが、機械学習では直観的には理解できない説明変数を考慮するため、より高い精度で予測でき、この点で機械学習がビッグデータに強いといわれています。
機械学習の種類
機械学習の学習方法には大きく、次の3つに分けることができます。
- 教師あり学習
- 教師なし学習
- 強化学習
上記のいずれの方法でも変化要因に対して将来を予測し、予測結果から成果を最大化することを考えることが目的です。正しい将来予測ができるモデルを作ることでビジネスの分野でも広く用いられていますが、データ活用の目的に応じて適切な手法を選ぶ必要があります。
教師あり学習
教師あり学習(Supervised Learning)とは、最も一般的な機械学習アルゴリズムで、正解データを読み込ませて、正しい出力ができるように入力データのルールやパターンを学習していく手法で、質の高いデータを学習するほど精度が上がります。教師あり学習では、既存データを基にタスクごとにクラスを識別する「分類」と連続する値を予測する「回帰」に分けられます。
分類は、あるデータがどのクラスに属するかを予測するものです。2種類に分類することを「二値分類」、3種類以上に分類することを「多値分類」と呼び、データの情報から正しいカテゴリに分類することを目的にしています。文章の特徴から迷惑メールを自動的に振り分ける、製造現場で不良品検知をする、写真情報から何が映っているのか判断するというような使われ方がされます。
なお、分類の評価方法には大きく次の3つが用いられます。
- 正解率:学習を行って予測した結果がどれだけ正解したかの数値
- 適合率:学習を行って正解と予測したものの内、本当に正解だったものの割合
- 再現率:本当に正解だったものの内、正解と予測したものの割合
一方、回帰は、入力と出力の関係を分析するために、連続するデータの変化を読み、数値を予測する手法のことです。天候や気温、価格などの要因から売上や販売個数を予測することができるため、正確な予測をすることで利益向上や廃棄率削減などの施策に繋がります。
また、教師あり学習は正解データを読み込ませることで学習させる手法ですが、半教師学習という少数のラベルのついたデータ(正解データ)と大量のラベルのないデータを用意し、機械学習を進めるという手法もあります。一般的に、正解データを大量に用意するには大量の時間と資金がかかるため、少ないラベル付きデータで効率的に学習する手法として注目されています。
教師なし学習
教師なし学習(Unsupervised Learning)とは、正解がわからないデータを読み込ませ、アルゴリズム自身がデータ探索をすることでデータ構造やパターンを見つける手法です。答えを含まないデータを使用するため、データ自身が持っている隠れた構造を見つけるのに役立ち、代表的な学習方法には「クラスタリング」と「次元削減」があります。
クラスタリングとはデータをグループ分けする手法です。既存データを基に予測をするのではなく、データの構造理解に用いられ、似たような特徴を持つデータをグループ化します。クラスタリングは「ハードクラスタリング」と「ソフトクラスタリング」に分けられ、ハードクラスタリングはデータが1つのクラスタ(集合)に完全に属しているかどうかを判定し、ソフトクラスタリングはデータがクラスタに属する確率や尤度(ゆうど、値のもっともらしさ)を判定する手法です。
次元削減とは膨大なデータから重要な部分を抽出し、データの圧縮や可視化を目的とした手法のことです。データ量が多すぎると処理に時間がかかり、端的にまとめることが難しくなります。そのため、データの次元数(項目数)を削減し、重要な部分のみに注目することでデータ量を少なくして処理スピードを高めることができます。4次元(4項目)以上の図示は難しいものの、3次元(3項目)以下に落とすことでグラフ化を可能にできるというような使われ方がされます。
強化学習
強化学習は環境とエージェントという2つの要素からなるシステム内で、エージェントが環境内で最適に振舞うように学習する手法のことです。教師あり学習や教師なし学習とは異なり、最初からデータがあるわけではなく、環境内でシステムが試行錯誤を繰り返しながら精度を高めていきます。囲碁、将棋、オセロのようなボードゲームのAIではこの強化学習が用いられ、人間の考え方や過去の進め方に左右されず、AI自らが最適解を見つけ出すことで学んでいくことがポイントです。
機械学習のアルゴリズムと選定基準
機械学習のアルゴリズムは多数存在しますが、どのアルゴリズムを選定するかは予測精度の高さ、利用目的、処理時間の長さによります。特に重要視されるのが予測精度の高さですが、精度が高い手法ほど処理時間がかかります。また、利用目的によって目的の出力結果が得られるかどうかが変わります。機械学習が行えるタスクとしては次のようなものが挙げられます。
- データを分類する
- 将来の数値を予測する
- 正解データなしをグループにまとめる
- 重要なデータを抽出する
上記のようなタスクに対して、できるだけ精度が高く、処理時間が短いアルゴリズムを選定する必要があります。
k近傍法
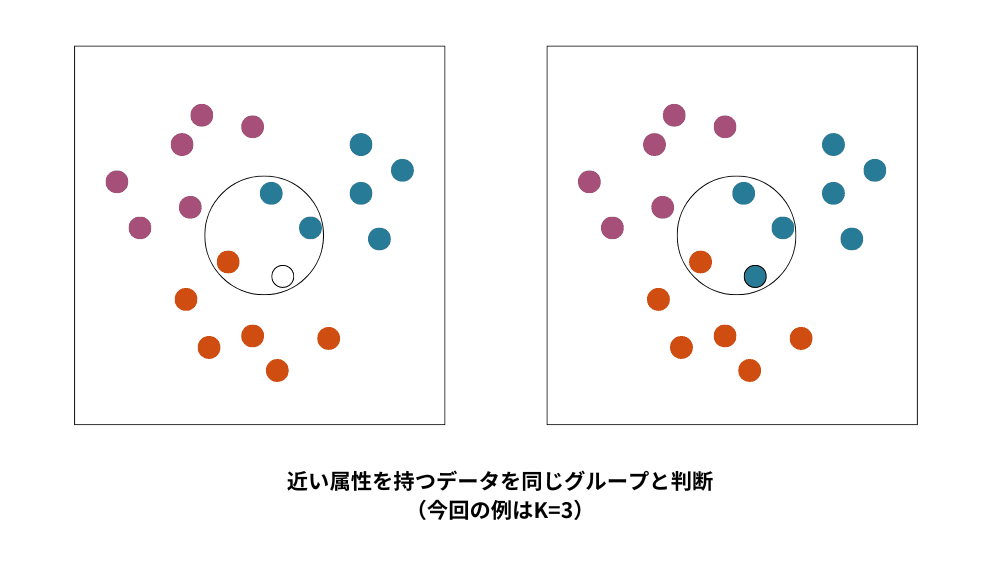
k近傍法は、近い属性を持つデータを同じグループと判断して分類する手法です。新しいデータポイントを分類する際にそのポイントに最も近いK個の既知のデータポイントを探し、K個のデータポイントの中で最も多いクラスに新しいデータポイントを分類します。機械学習のアルゴリズム内では単純でわかりやすく、分類にも回帰にも利用できますが、学習データの量が多い場合には処理時間がかかるため、膨大なデータの処理には不向きです。
決定木
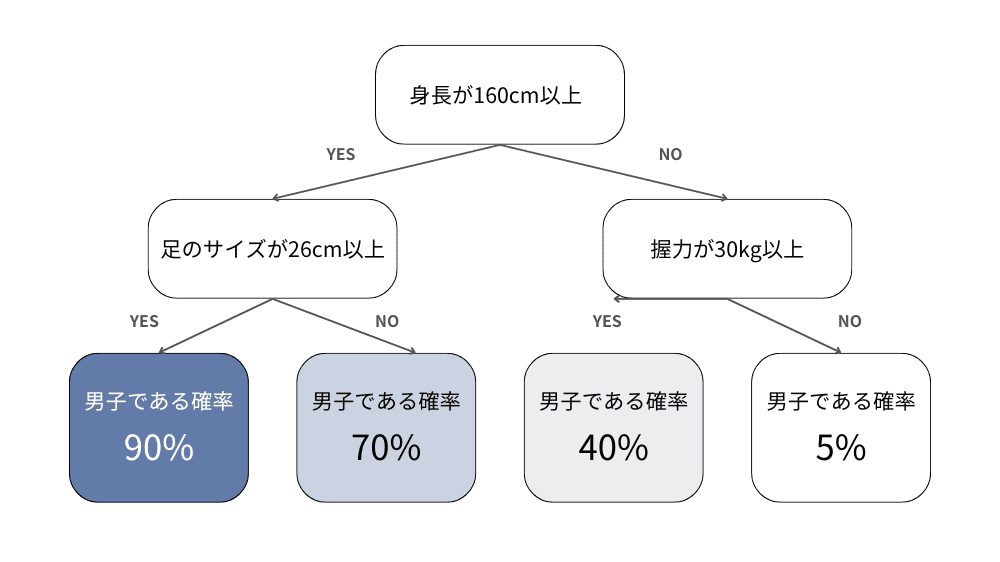
決定木はYes/Noという条件分岐だけで分類する手法です。一度決定木の教師データ(ツリー)を作ってしまえばそのロジックに従い、新しいデータを分類することができます。分類過程で階層構造を用いるため、どこで分岐されたかが理解しやすく、経緯を読み取りやすいのが特徴です。汎用性が高く、分類にも回帰にも利用できますが、分岐数が少なすぎる場合には予測精度が低くなることがあり、そもそも精度を重視する場合には、他の手法を取ることが一般的です。
ランダムフォレスト
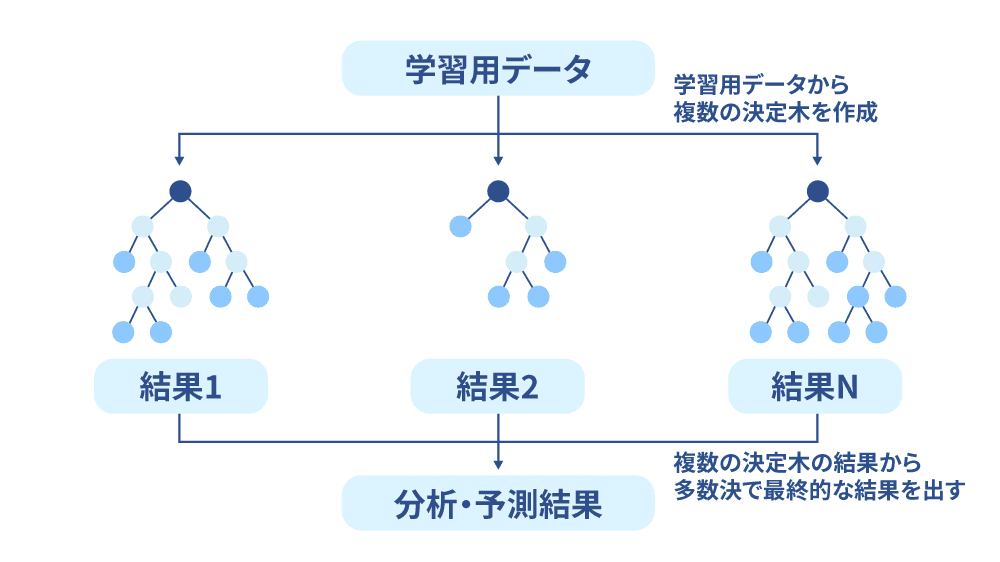
ランダムフォレストとは、並列に学習した決定木に予測を行わせ、複数の出力結果をまとめて多数決や平均を基に決定します。ざっくりと言うと複数の決定木を集めたアルゴリズムです。決定木では過学習に陥りやすいという弱点がありますが、ランダムフォレストでは過学習を抑制できるという点で優れています。
※過学習:訓練したデータに過剰に適合してしまい、未学習のデータに対する予測精度が落ちてしまう状態のこと
サポートベクターマシン(SVM)
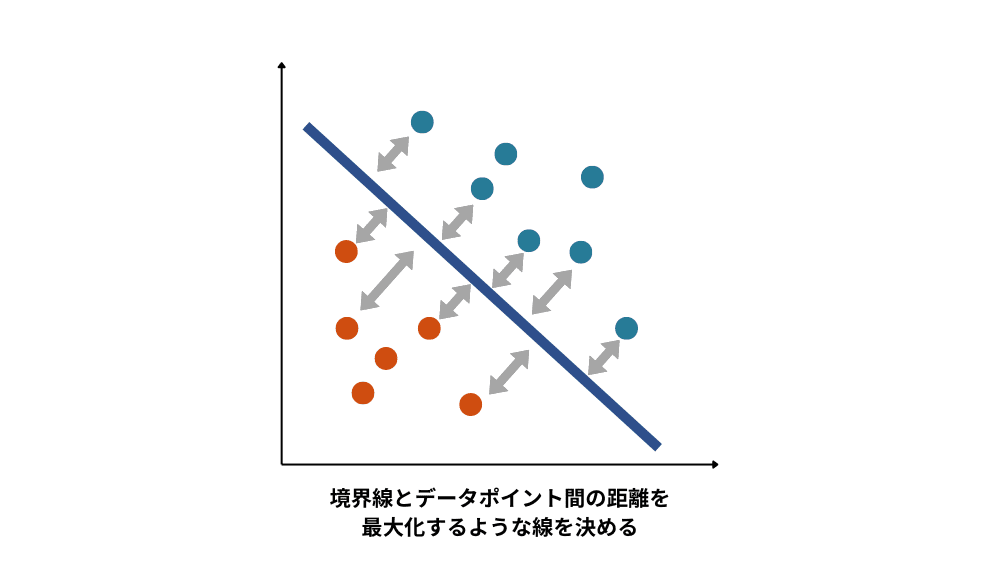
サポートベクターマシン(SVM)とは、2つのクラスのデータ群を分割するような境界線を決定することで分類データにおいて高い精度を出すことができる手法です。図のようなデータ群を境界線を用いて分類した場合に、境界線の引き方がいくつか出てきてしまいます。SVMでは「マージン最大化」と言う手法を用い、境界線とそれぞれのグループのデータポイント間の距離を最大化するように境界線を決め、新規データの分類の教師データとすることが特徴です。計算が早く、過学習も起こしにくいため広い分野で活用されているアルゴリズムですが、データのバラつきが偏ると計算量が膨大になり、学習が非効率になってしまうことがあります。
ニアレストネイバー法
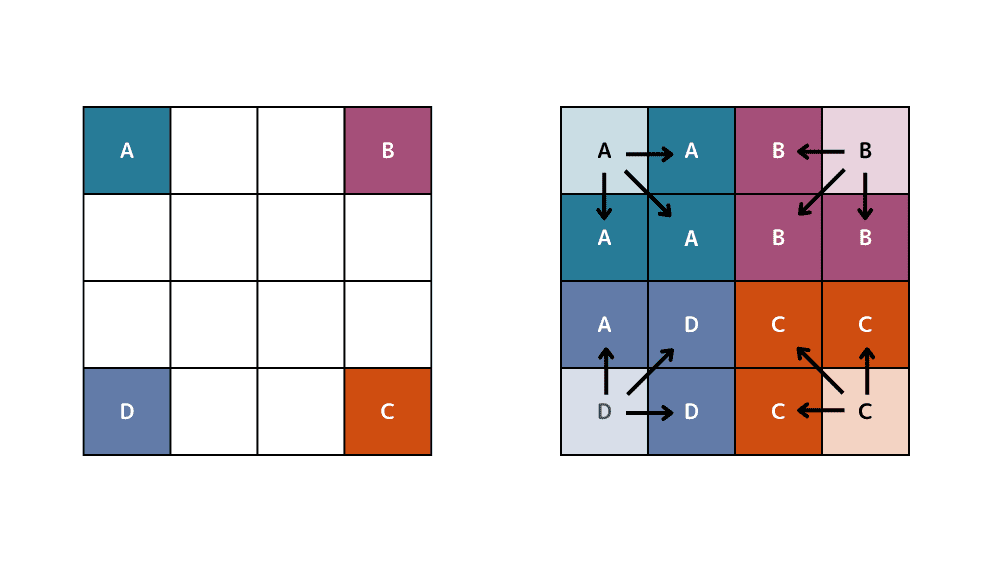
ニアレストネイバー法(最近傍補間)とは、画像の拡大縮小時など、補うべき点(画素)が発生した際に、未知の点を既存のクラスタに分類する際に使われる手法です。未知の点の値を、その点に最も近い既知の点の値で代用するだけなので必ずしも高い精度が出るとは限りません。データを補う方法としては、バイリニア法やバイキュービック法などが挙げられます。
ロジスティック回帰
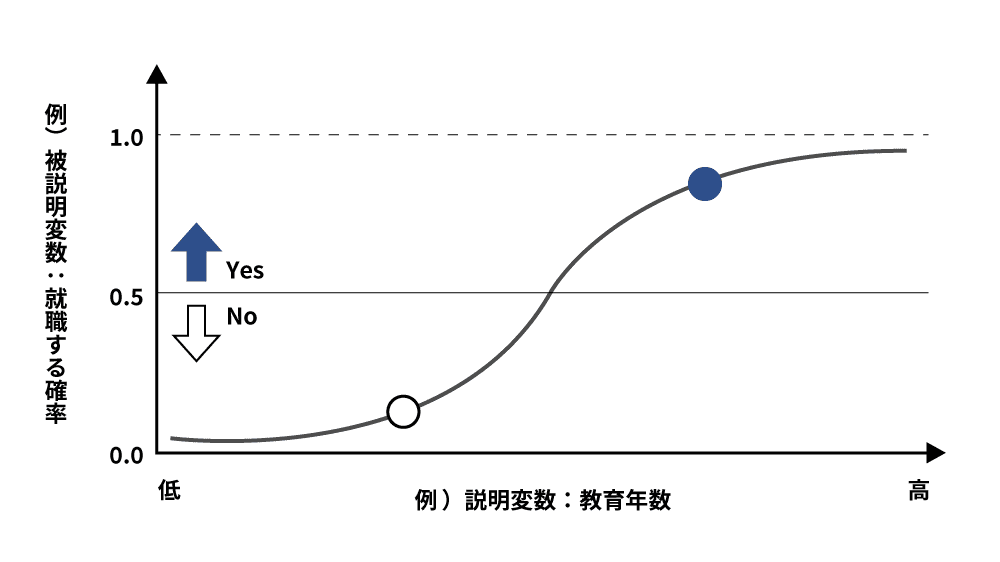
ロジスティック回帰は、いくつかの要素からYes / Noという2つの結果の確率を予測するための統計手法です。主に二値分類に使用されますが、多値分類に使用することもできます。ある事象が起こる確率をY軸、事象が起きる要因をX軸として、それらの相関を表すグラフで表現してあげます(シグモイド関数)。特定の点のY値が50%以上であればYESと判断します。
ナイーブベイズ
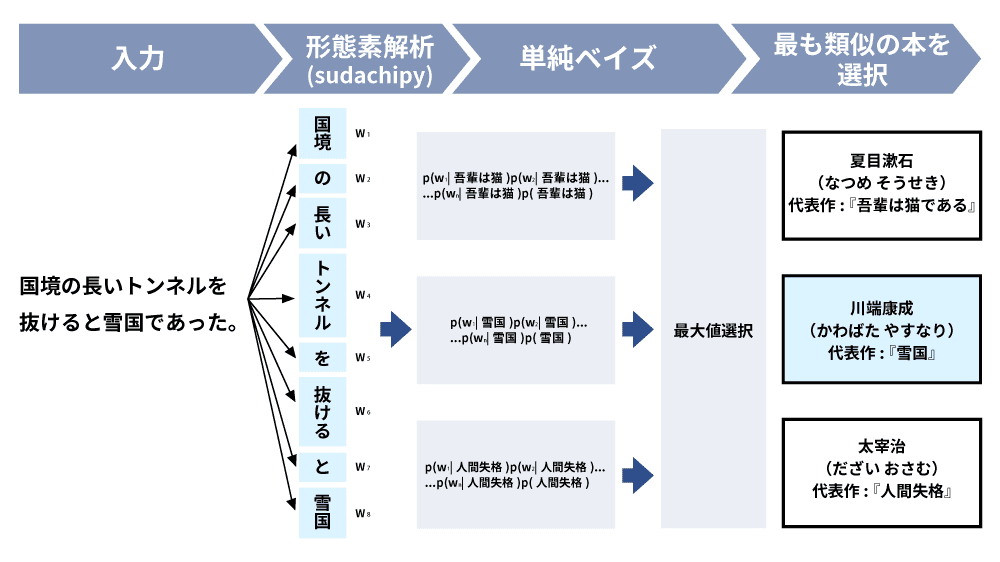
ナイーブベイズは、データが特定のカテゴリに属する確率を計算し、最も高い確率になるカテゴリに分類する手法で、スパムメールの自動振り分けのような自然言語の分類に利用されています。高速に計算でき、膨大なデータにも対応できる点が特徴です。
k平均法(k-means)
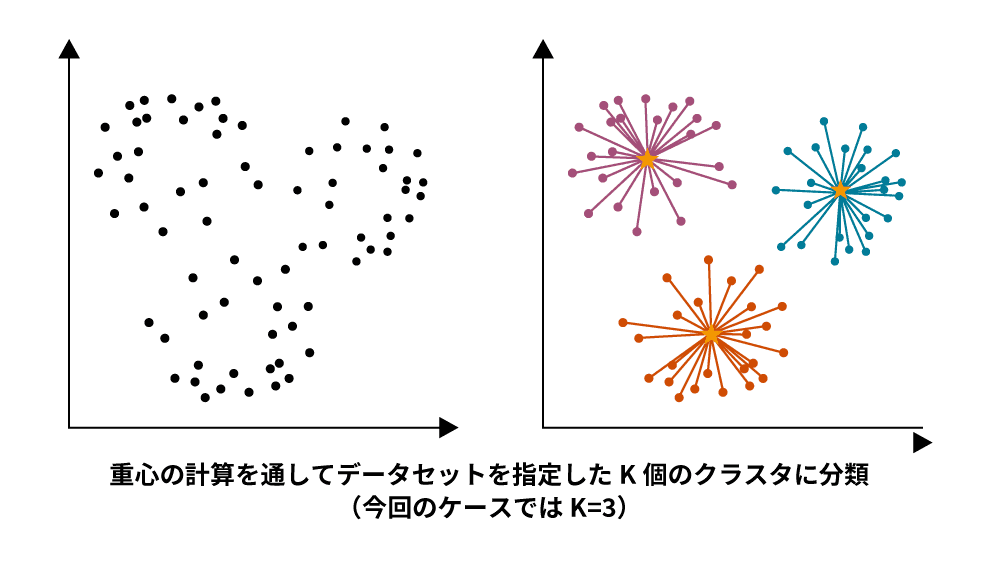
k平均法は、似たような特徴を持つデータ同士を同じグループに分けることができる手法です。分類したいグループ数に応じた中心点を配置し、最も近い中心点を紐付け、グループの重心を算定・特定します。この重心を中心点として同じプロセスを実施し、重心が移動しなくなるまで繰り返します。初期にはデータをランダムに割り当てて中心点を計算するため、中心点同士が近すぎるとうまく分類できないことがあります。
主成分分析
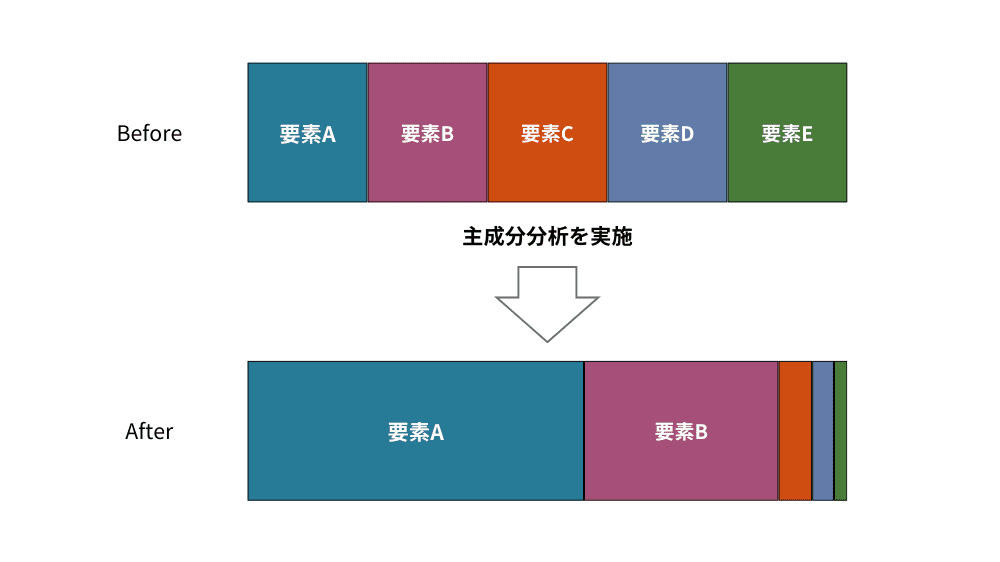
主成分分析はデータを要約し、重要要素を損なわずに少ない次元数で表す手法です。大量の変数間の関係性を調べるのに便利な手法で、3次元以下に次元を落とすことができればデータを図示することもできるようになります。
ニューラルネットワーク
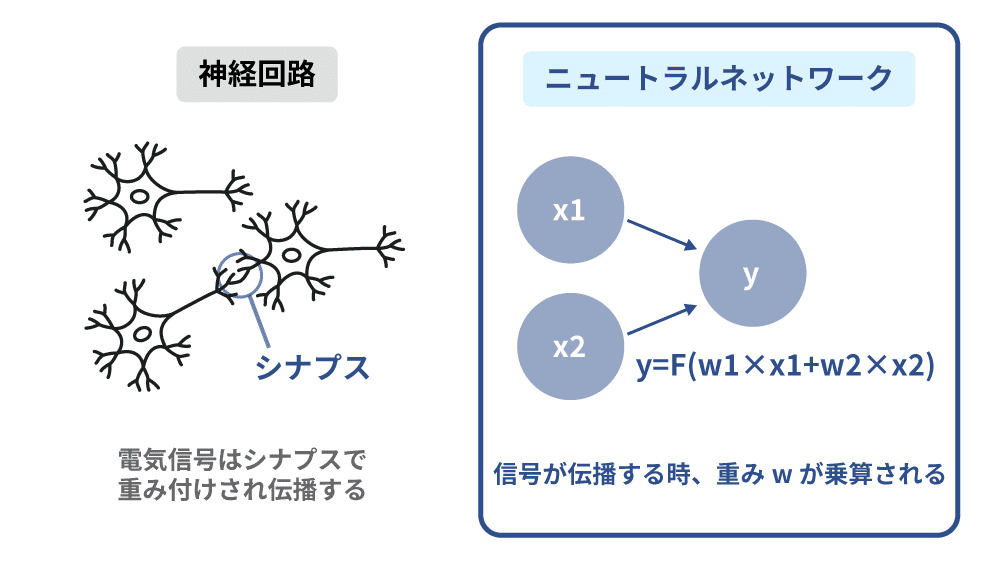
ニューラルネットワークとは、脳神経の仕組みのような機械学習アルゴリズムで、脳の回路に似た入力層、中間層、出力層の3つの層で構成されています。入力層と出力層の間に中間層を挟み、より複雑な決定境界を求める手法で、分類と回帰の両方に適用できます。この中間層を深くしたものがディープラーニング(深層学習)であり、精度を飛躍的に向上させることができます。
機械学習アルゴリズムの選定方法
機械学習のアルゴリズムの一例を前述しましたが、与えられたデータがどのような種類か、どのようなタスクを行いたいかで利用するアルゴリズムは変わります。選ぶアルゴリズムを誤ると正しい予測が難しくなるため、解決したい課題ごとにどの手法を使うべきかはチートシートと呼ばれる表を見て選定することになります。
チートシートは研究機関やオープンソースライブラリなどで配布されていますが、次の2 つが有名です。
- SAS Institute Japan:教師あり学習、教師なし学習で分類されており、日本語のチートシートが公開されています。
- Azure Machine Learning:細かいカテゴリに分かれており、英語での配布ではありますが、非公式では日本語版も配布されています。
最後に
機械学習とは、膨大なデータを用いてコンピュータが自動的に学習し、予測や意思決定を行う技術です。機械学習には教師あり学習、教師なし学習、強化学習の3つの種類があります。教師あり学習はラベル付きデータを用いてモデルを訓練し、分類や回帰などのタスクに用いられます。教師なし学習はラベルのないデータを用いてデータ内のパターンを発見する手法であり、クラスタリングや次元削減に活用されます。強化学習は、試行錯誤を通じて最適な行動を学習する手法であり、特にゲームAIやロボット制御において成果を上げています。
これらの手法はそれぞれ異なる特性を持ち、適切に選択することが重要です。機械学習の技術は日々進化しており、その応用範囲はますます広がっています。今後もさまざまな分野でその可能性を追求することが期待されます。







