
アンサンブル学習とは、複数のモデルを組み合わせて予測の精度や安定性を高める手法です。個別のモデルが持つ誤差や弱点を補い合いながら、全体としてより信頼性の高い結果を導くことができます。
機械学習において、1つのモデルだけでは対応が難しいパターンやデータのばらつきに対して、異なるアプローチを統合することにより、幅広い状況に対応可能となります。特に、バギングやブースティング、スタッキングといった代表的な手法は、それぞれ異なる仕組みを持ち、用途やデータ構造に応じて使い分けることができます。複雑な問題にも柔軟に対応できるアンサンブル学習は、実務やコンペティションの場でも多く活用されています。

アンサンブル学習とは
アンサンブル学習とは、精度が高くない複数の学習器を組み合わせて予測精度を向上させる手法です。主に弱学習器(単独で使うと精度の低い手法のこと)を使いますが、Kaggle(機械学習のコンペティションのプラットフォーム)などでは強力な学習器同士を組み合わせる手法も実践されています。単一モデルでは難しい高精度な予測を複数のモデルの協調によって実現します。
アンサンブルという言葉は、機械学習の分野では複数のモデルを統合して1つの判断を行う意味合いで使われます。たとえばデータを分割して同じモデルで学習したり、異なるモデルを同じデータに適用したりする方法があり、それぞれの弱点を補完し合うことで精度や汎用性を高めます。個々のモデルの知識を統合する点では知識蒸留(複雑で大きなモデルの知識を、より小さく単純なモデルに伝える技術)と似た効果も得られます。
予測精度の誤差を理解する
アンサンブル学習では予測精度を向上させるために誤差の性質を理解する必要があります。ここで重要となるのがバイアスとバリアンスです。
バイアス:予測値と実際の値との差。値が小さいほど正確な予測ができていることを意味する
バリアンス:予測値のばらつきの程度。ばらつきが大きいほど一貫性がなく、安定した予測が難しくなる
バイアスが高い状態ではモデルが単純すぎて十分に学習できていません。反対にバリアンスが高い場合は、学習データに過剰に適合し、新しいデータへの対応が不安定になります(この状態を過学習と呼びます)。バイアスとバリアンスはトレードオフの関係にあり、片方を下げるともう一方が上がる傾向があります。
アンサンブル学習では、異なる誤差特性を持つモデルを組み合わせることで、全体の誤差を相殺し、汎化性能の高いモデルを構築できます。
アンサンブル学習の基本構造
アンサンブル学習では、複数の学習器を用いることで未知のデータへの予測力を高めることができます。たとえば、分類問題ではそれぞれのモデルの予測結果に多数決を取り、回帰問題では平均値を用いることで、全体の精度を引き上げます。
個々の学習器の精度が低くても組み合わせることで高い精度を実現することが可能です。これは一人の判断よりも複数人の意見を合わせることで正答率が高まる構造に似ています。
アンサンブル学習の代表的な手法にはバギング、ブースティング、スタッキングなどがあります。いずれも複数モデルの出力を適切に統合し、1つの強力な予測モデルを生成することを目的としています。
バイアスとバリアンスの調整
アンサンブル学習の効果を最大限に引き出すには、バイアスとバリアンスのバランスを意識したモデル設計が不可欠です。バイアスが高いと過小適合になりやすく、バリアンスが高いと過学習に陥りやすくなります。アンサンブル学習では、バイアスの高いモデル同士を組み合わせることで精度を底上げし、バリアンスの影響を緩和する構造が基本となります。
予測精度が安定しない場合は、バイアスとバリアンスのいずれかに偏りがある可能性が高く、改善のためには適切な構成の見直しが必要です。特に実務では、バイアスとバリアンスの関係をグラフなどで可視化して確認しながらモデル調整を行うことが有効です。
アンサンブル学習は、単一モデルでは実現できない高精度な予測を実現する手法です。バイアスとバリアンスの調整によって、汎化性能に優れたモデル構築が可能となります。
アンサンブル学習の種類
アンサンブル学習にはバギング・ブースティング・スタッキングの3つの代表的な手法があります。
バギングは、学習データからランダムにサブセットを抽出し、それぞれに独立したモデルを学習させて予測を行う方法です。各モデルは並列に処理され、分類では多数決、回帰では平均を取って最終的な予測を出します。データのばらつきによる過学習を抑えるのに有効です。例えるのであれば、複数の人に同じ質問をして、それぞれの回答を総合して最終的な結論を出すイメージです。
ブースティングは、前のモデルが間違えたデータに重点を置きながら、モデルを直列に順番に学習させていく手法です。前の誤りを修正するように次のモデルを構築していくため、バイアスを下げる効果が高い一方で、過学習に注意が必要です。例えるのであれば、何度も練習問題を解いて、間違えた問題を重点的に復習することで、徐々に正解率を上げていくイメージです。
スタッキングは、異なる種類の複数モデルの予測結果を、さらに別のモデルに入力し、最終予測を行う方法です。多様なアルゴリズムを組み合わせることで、単独モデルでは捉えきれないデータの構造を表現することが可能です。処理は複雑ですが、Kaggleなどの機械学習コンペでは効果を発揮する手法として知られています。例えるのであれば、複数の専門家にそれぞれ意見を聞き、その意見を総合して最終的な判断を下すイメージです。
各手法の違いは以下の通りです。
| 手法 | モデル構造 | データの使い方 | 学習の進め方 | 出力の統合方法 |
| バギング | 複数の同種モデル | データを復元抽出して複数生成 | 並列処理 | 平均または多数決 |
| ブースティング | 複数の同種モデル | 全データを繰り返し使用 | 直列処理 | 重み付き平均 |
| スタッキング | 異種モデルの組合せ | 同一のデータセットを利用 | 段階的処理 | メタモデルによる予測 |
どの手法を使うかは、目的やデータの特性によって大きく変わります。精度が伸び悩む場合や判断がつかない場合は、まずすべて試してみるのが有効です。実際にモデルを構築し、その精度や安定性を比較していくことで、より適切な選択が見えてくるようになります。
バギング(Bagging)
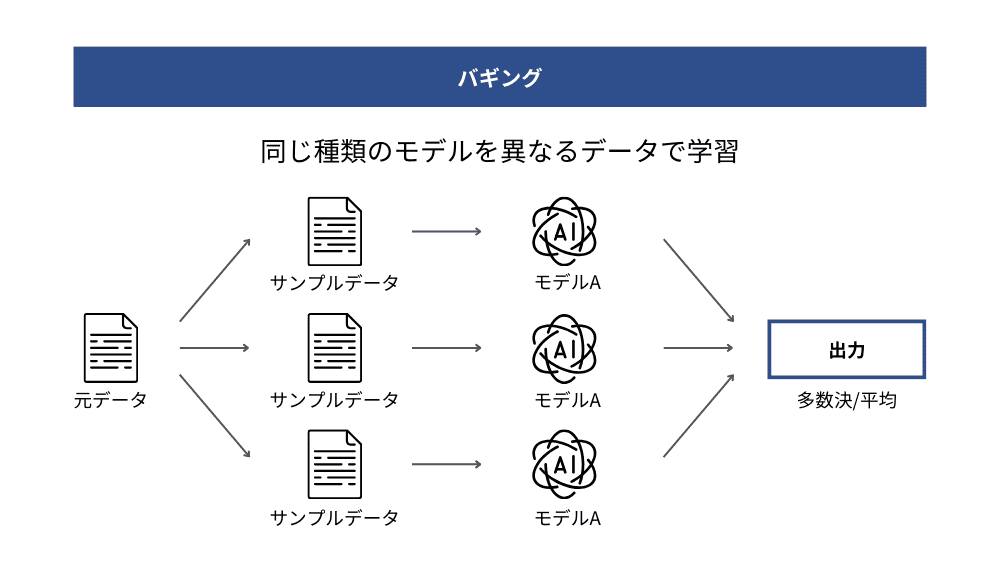
バギングとは、Bootstrap Aggregatingの略称で、同じデータセットからランダムに復元抽出したサブセットを複数作成し、それぞれに学習器を訓練させたうえで予測結果を統合する手法です。分類では多数決、回帰では平均を用いて最終予測を決定します。
バギングではデータに多様性を持たせることで、個々のモデルの過学習を防ぎ、全体のバリアンスを抑える効果が期待できます。複数の学習器が独立して学習するため、並列処理が可能で計算効率にも優れています。
代表的な例としてランダムフォレストが挙げられます。これは決定木をベースにした複数のモデルをバギングで統合するアルゴリズムで、分類や回帰に広く使われています。
バギングでは学習データの一部のみを使うことで精度の向上を目指しますが、抽出されたデータサンプルが似通っていると効果が薄れる場合があります。また、繰り返し回数が多すぎると全体のデータを使い切ってしまい、過学習を招くおそれがあるため、回数設定には注意が必要です。
モデルの予測精度が不安定な場合や、バリアンスの高い状態を改善したいときに有効な手法であり、実装も比較的容易なため、アンサンブル学習の中でも特に広く利用されています。
ブースティング(Boosting)
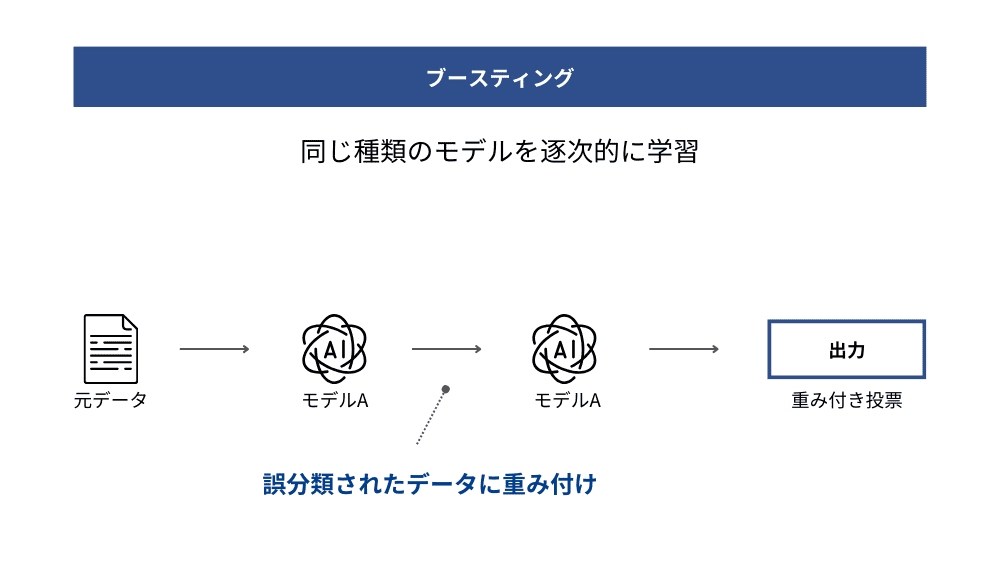
ブースティングとは、弱い予測モデルを順番に学習させていくことで、全体の予測精度を高めるアンサンブル手法です。最初のモデルで誤ったデータに重点を置き、次のモデルがその誤りを修正する形で順次改善を重ねていきます。各モデルは直列に学習され、最終的にはそれぞれのモデルに重みをつけて統合します。
ブースティングはバイアスを低減させる効果があり、分類・回帰のどちらにも利用されます。決定木と組み合わせた手法としては、XGBoostやLightGBMなどが代表的です。
ブースティングのメリットは予測精度の高さにあります。前の誤りを再利用しながら学習を進めるため、データの特性を細かく反映できますが、一方で何度も同じデータに学習を重ねることで過学習に陥りやすく、バリアンスが高くなる点には注意が必要です。
ブースティングの代表的な実装には、AdaBoostや勾配ブースティング(GBDT)があります。XGBoostはGBDTを高速化したものであり、実務で広く使われています。このような手法により誤分類されたデータに重みを与えて次の学習へ反映させる仕組みを持ち、精度が向上されていきます。
処理は並列ではなく直列で行われるため計算コストは高くなりますが、前処理が不十分でも一定の精度が得られる点は実務上の利点です。ブースティングは精度とリスクのバランスを取りながら活用される代表的なアンサンブル手法の1つです。
スタッキング(Stacking)
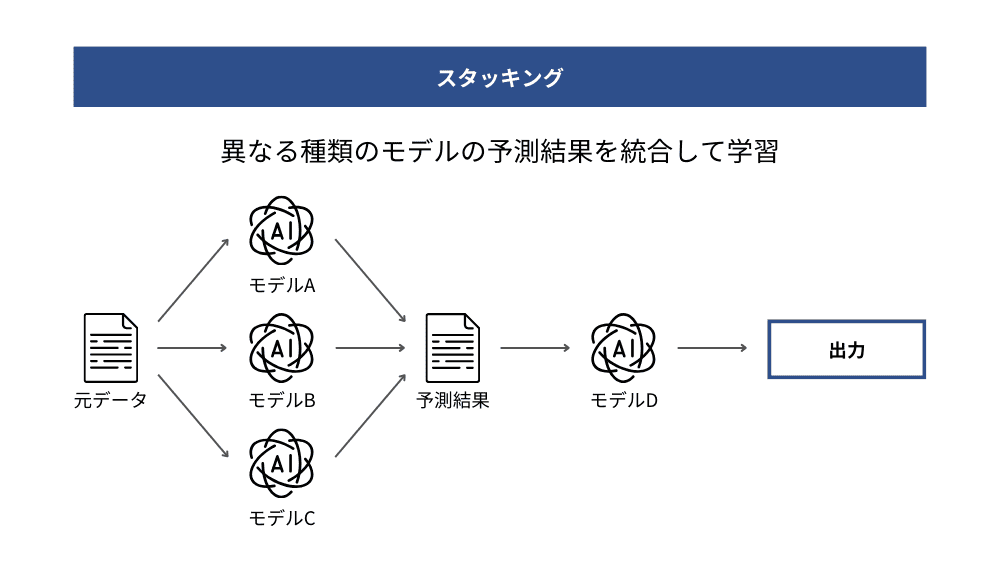
スタッキングとは、異なる種類のモデルを組み合わせて精度を高めるアンサンブル学習の手法です。複数のモデルに学習させた後、それぞれの予測結果を別のモデルに入力し、最終的な予測を行うことにより、各モデルの特徴を融合させ、単一のモデルでは捉えにくい複雑なパターンに対応できます。
スタッキングは特にKaggleなどの機械学習コンペで効果を発揮し、多様なアルゴリズムを活用することで精度を向上させる目的で用いられます。
スタッキングは一般的に2段階で構成されます。まず第一段階でロジスティック回帰やランダムフォレスト、勾配ブースティングなど複数の学習器にデータを学習させ、それぞれの予測結果を得ます。次に、その予測値をまとめて第二段階のメタモデルに入力し、最終的な出力を得ます。必要に応じて第三段階以降に進むこともあります。
スタッキングの強みは多様なアルゴリズムの視点を統合できる点にあります。異なる手法が出す予測を組み合わせることで、精度が向上する可能性があります。ただし、必ずしもすべてのケースで効果があるとは限らず、構成によっては精度が上がらない場合もあります。
また、複数のモデルと段階的な処理を必要とするため、実装やチューニングには手間がかかります。処理時間も長くなりがちですが、特徴量の表現力が高くなるため、実務やコンペティションで利用されることが多い手法です。
アンサンブル学習のメリット
精度向上
アンサンブル学習は複数のモデルの視点を統合することで、単一モデルでは捉えきれないデータのパターンや特徴を補完し合い、予測精度を高めることができます。異なるアルゴリズムが持つ強みを活かし、それぞれの誤差を平均化することでノイズや外れ値の影響を軽減し、安定した予測が可能になります。
特に、品質が一定でないデータやノイズの多いデータセットに対しては、モデルの組み合わせにより信頼性が高まります。個別モデルが誤差を出す場面でも、他のモデルがそれを補うことで全体の精度が保たれます。
また、信頼度スコアに基づいた重み付けにより、単純な多数決よりも精緻な予測が可能です。このような特性は、分類・回帰のいずれのタスクにおいても安定性と信頼性を両立させる要因となります。
汎用性向上
アンサンブル学習は用途やデータ構造に応じて柔軟に構成を変更できるため、医療、金融、製造、感情分析など多様な分野での活用が可能です。複数のモデルを組み合わせることで特定の業種や問題設定に依存せず、さまざまな課題に対応できます。
特に、大規模データの処理では処理負荷を分散し、限られたデータ環境では再利用やブートストラップを活用することで少量のデータでも効果的に学習が行えます。
単一モデルでは対処できない問題への適応
1つのモデルでは対処しきれない複雑な決定境界や構造に対しても、複数のモデルを組み合わせることで対応可能になります。たとえば、あるモデルがある領域に強くても別の領域では弱い場合、異なるモデル同士の組み合わせにより、全体の予測力を補完できます。この特性はデータの分布が多様な場合やクラス間の境界が非線形である場面において特に効果を発揮します。
情報融合による判断の強化
アンサンブル学習では、異なるデータ分布や前提条件に基づいて訓練されたモデルを融合することで、より多角的かつ偏りの少ない予測が実現します。たとえば、高解像度の画像に強いモデルと低解像度でも対応できるモデルを組み合わせれば、より頑健な分類器を構築できます。このように、異なる情報源や訓練条件を活かした情報融合は、アンサンブル学習の大きな強みです。
重要な特徴の把握
複数のモデルによる予測の比較を通じて、どの特徴量が結果に影響を与えているかを明確に把握できるようになります。視点が異なるモデルを組み合わせることで、特定の変数の重要性や役割が浮かび上がりやすくなり、モデルの解釈性や改善の方向性を見出すうえでも有効です。この特性は、実務での説明責任やモデルの透明性が求められる場面において、大きな価値を発揮します。
アンサンブル学習の注意点
過学習のリスクに注意する
アンサンブル学習は精度向上に効果的ですが、特にブースティングのような手法では訓練データに過剰に適応し、過学習に陥るリスクがあります。複雑なモデルを繰り返し強化すると、ノイズや例外的なパターンに過敏になり、未知データへの汎化性能が下がる恐れがあります。強力なモデルを無作為に組み合わせるだけではかえって精度を損なうこともあります。過学習を防ぐためには、モデルの複雑さを調整し、交差検証などで検証を繰り返すことが重要です。
計算コストと学習時間が大きい
アンサンブル学習は複数のモデルを構築・統合するため、学習や推論に時間がかかります。特にバギングやスタッキングは並列処理が前提であっても、モデル数の増加に比例して計算資源を消費します。ブースティングのように直列でモデルを積み重ねる場合は、処理時間がさらに長くなります。
実務では、精度向上と得られる成果を天秤にかけ、コストに見合うかを検討する必要があります。特にリアルタイム性が求められる場面では、応答速度にも配慮しなければなりません。
解釈性が低下しやすい
複数のモデルを組み合わせることで、予測の根拠がわかりにくくなる傾向があります。特に異なる種類のモデルを用いた場合、それぞれがどのように最終結果に寄与したのかを説明するのが難しくなります。単一モデルであれば特徴量ごとの重要性や出力根拠を追跡しやすいですが、アンサンブルでは特定が困難です。説明責任や透明性が求められる場面では、この点に注意が必要です。
バイアスとバリアンスのバランスが難しい
アンサンブル学習ではバイアス(単純すぎるモデルによる誤差)とバリアンス(過学習による不安定さ)のバランスが重要です。精度を高めようとバイアスを下げすぎるとバリアンスが高まり、モデルが不安定になります。たとえばランダムフォレストは、このバランスがとれた代表的な手法です。アンサンブルを成功させるには、この関係性を理解し、目的に応じた手法を選択することが求められます。
モデルに多様性を持たせる
アンサンブル学習の効果を最大化するには、異なる特徴を持つモデル同士を組み合わせる必要があります。同じ傾向のモデルを複数組み合わせても予測の幅は広がりません。
たとえば、決定木とサポートベクターマシンを組み合わせると、異なる特徴に反応するため、データの多様な側面をカバーできます。モデル間の相関を抑え、多様性を持たせることでアンサンブル全体の性能が安定します。
データの質が結果を左右する
データに欠損やノイズが多いと、どれだけモデルを組み合わせても精度は上がりません。アンサンブル学習の効果を発揮するためには前処理を丁寧に行い、特徴量の選定や欠損値の補完などを適切に実施する必要があります。特に複雑なモデルを構築する前提として、入力データの信頼性を高めることが最優先です。
構成を適切に設計する
アンサンブル学習は単にモデルを組み合わせればよいというものではありません。使用するアルゴリズムの特性や精度、計算コストを考慮しながら、適切な構成を設計する必要があります。たとえば、ランダムフォレストで安定性を確保しつつ、ブースティングで精度を追求するなど、目的に応じて最適な組み合わせを選ぶことが重要です。設計段階での選定ミスが、予測の安定性や運用コストに大きく影響します。
最後に
アンサンブル学習は、単一モデルでは捉えきれない情報を多様な視点で補完し合うことで、高精度かつ安定した予測を可能にします。バギングではバリアンスを抑え、ブースティングではバイアスを低減し、スタッキングでは異種モデルの組み合わせによる表現力の強化が実現されます。
こうした手法を適切に使い分けることで、複雑なデータ構造や不規則なノイズにも柔軟に対応できます。一方で、過学習のリスクや計算コスト、解釈性の低下といった注意点も存在するため、構成設計やデータの前処理が不可欠です。多様性とバランスを意識しながら、目的や制約に応じて最適なアンサンブル戦略を構築することが求められます。







