
ディープラーニングとは、ニューラルネットワークを基盤にした高度な機械学習技術で、近年のAI技術の進展を支える重要な技術です。データの背景にある複雑なパターンや規則を多層構造を通じて自動的に抽出することで、従来のデータ分析手法では困難だった画像、音声、自然言語などの非構造化データを効率的に処理し、これまで以上に精度の高い解析が可能になっています。
ディープラーニングは、画像認識や自然言語処理、自動運転車、音声アシスタントなど、日常生活やビジネスに大きな変革をもたらしています。特に、データから自動的に特徴を抽出し、複雑なパターンを認識する能力に優れており、膨大なデータの中から有用な情報を見つけ出す力を持っています。その結果、ディープラーニングはさまざまな分野で活用され、現代のAI革命を推進しています。

ディープラーニングとは
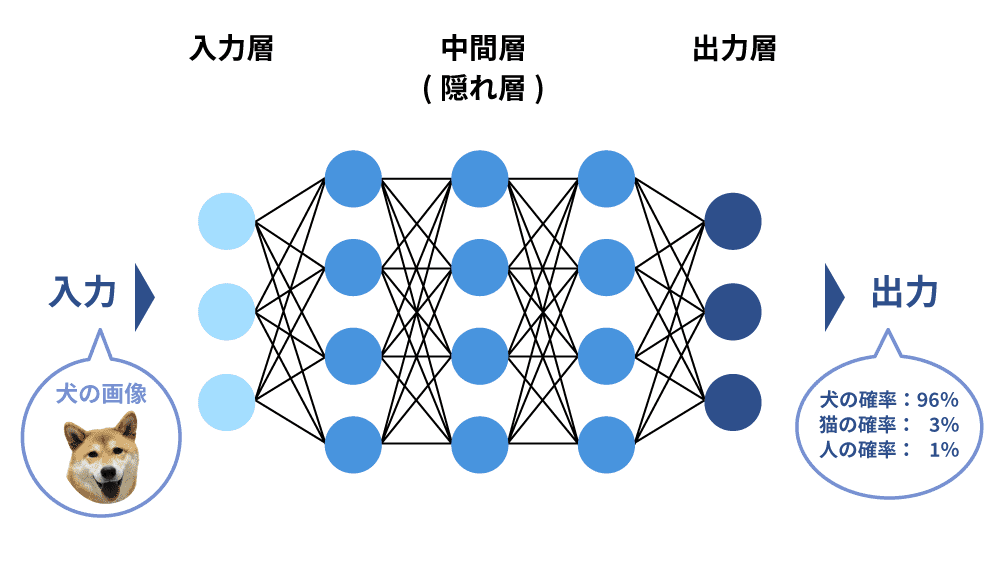
深層学習(ディープラーニング)とはニューラルネットワークを使い、共通点を自動的に抽出することで高精度な分析を可能にする学習方法です。データからルールやパターンを見つける際に処理を多層化することで、より正確な判断ができるようにしています。深層学習により、従来学習が難しいとされてきた画像や自然言語のような非構造化データも学習できるようになりました。
一般的なデータ分析ではインプットとアウトプットの関係を直接分析しますが、ディープラーニングは中間層(隠れ層)と呼ばれる構造を設け、多層化することで、データの背景にあるルールやパターンを考えることができ、データの分析精度が向上することが特徴です。ディープラーニングはビジネスの最適化やユーザー体験の向上など効率化や改善に繋がるため、画像処理、自動運転、自動翻訳など様々な分野で応用されています。
ディープラーニングの重要性
ディープラーニングが重要とされる理由の1つは精度の高さです。従来の機械学習では到達できなかったレベルにまで精度を高めることができたのは、ディープラーニングに大きく依存しています。
一例を挙げると、画像認識では人間と比較しても遜色のないレベルで識別ができるようになっており、自然言語処理でも違和感のないレベルにまで到達して音声アシスタントのような形で実現しています。AIの分野ではディープラーニングは欠かせないものとなっており、技術が進歩することでさらに多くの分野で応用されることが期待されています。
機械学習との違い
機械学習とは、コンピュータがデータからパターンを学習し、予測や意思決定を行う技術のことです。AI(人工知能)はコンピュータに人間を模倣した知性を持たせることを目的とした技術のことですが、人間を模倣するにはコンピュータ自身が学習する必要があります。このコンピュータが学習することを機械学習と呼び、ディープラーニングは機械学習の1つに分類されています。

ディープラーニングの仕組み
ディープラーニングはニューラルネットワーク(NN)を多層構造化したディープニューラルネットワーク(DNN)を用いて学習し、データの特徴を抽出していきます。まず、入力層にデータを入力し、それぞれの層でデータが重み付けされ、出力されます。その出力は次の層の入力となり、再度重み付けの処理を経て出力されます。このように多層のニューラルネットワークを通じて、入力データから目的とする出力データを求めます。
代表的な学習方法としては次のようなものがあります。
- 畳み込みニューラルネットワーク(CNN)
- リカレントニューラルネットワーク(RNN)
- Generative Adversarial Networks(GAN)
- Transformer(トランスフォーマー)
- Long Short-Term Memory(LSTM)
畳み込みニューラルネットワーク(CNN)
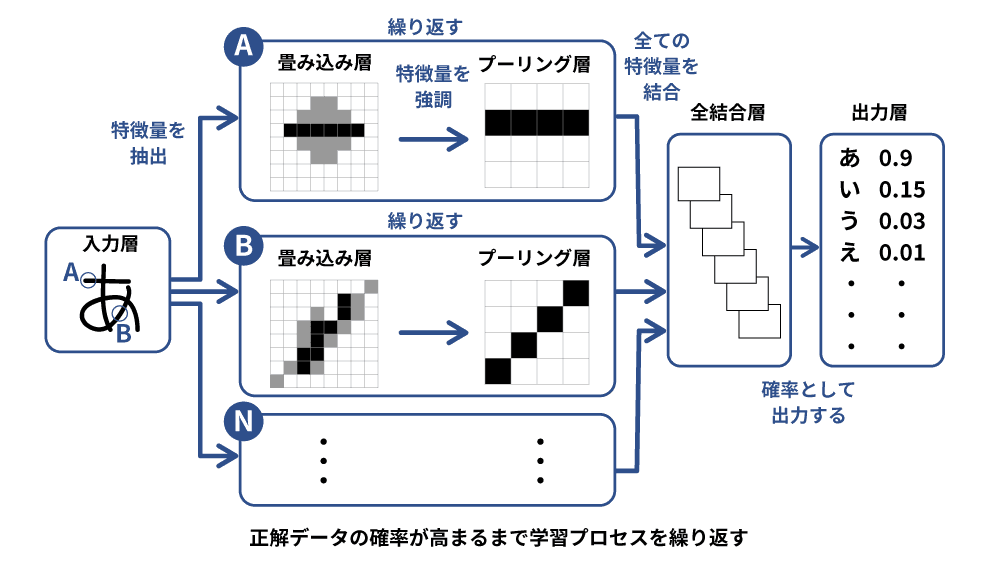
畳み込みニューラルネットワーク(CNN、Convolutional Neural Network)とは、画像認識や動画認識に広く使われている学習方法です。空間情報を捉える能力が非常に高く、画像認識分野では最も有効的な学習手法といわれています。
画像の特徴を抽出する畳み込み層と特徴を分析するプーリング層で構成されています。畳み込み層では画像の特徴を捉えるために画像の一部を数式処理して特徴マップを生成し、プーリング層では畳み込み層の出力である特徴マップのサイズを縮小し、重要な特徴を強調することでモデルの品質を高めます。CNNは画像に対する認識能力が高く、膨大なデータから自動的に特徴を抽出できることから、画像分類や物体検出などのタスクに利用されます。
リカレントニューラルネットワーク(RNN)
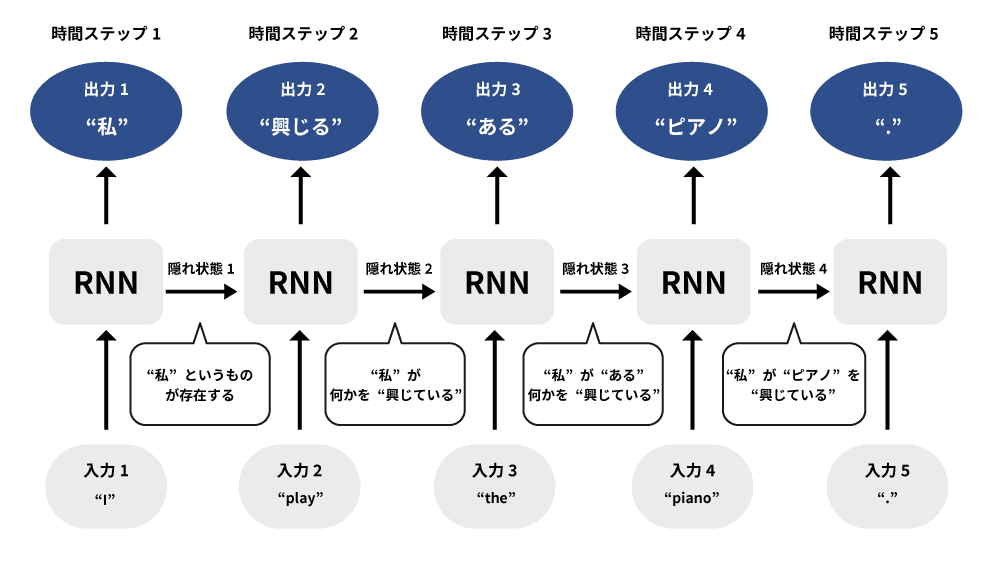
リカレントニューラルネットワーク(RNN、Recurrent Neural Network、再帰型ニューラルネットワーク)とは、ニューラルネットワークを拡張することで、時系列データを扱えるようにしたものです。各時刻での入力データに対して過去の情報を保持し、情報を次の時刻に渡すことができるため時系列データに含まれる時間的なパターンの学習が可能です。音声認識や動画認識、自然言語処理などに用いられており、特に自然言語処理では非常に優れた成果を上げています。利用例としては、機械翻訳や音声認識、動画解析など多岐にわたります。
LSTM(Long Short-Term Memory)
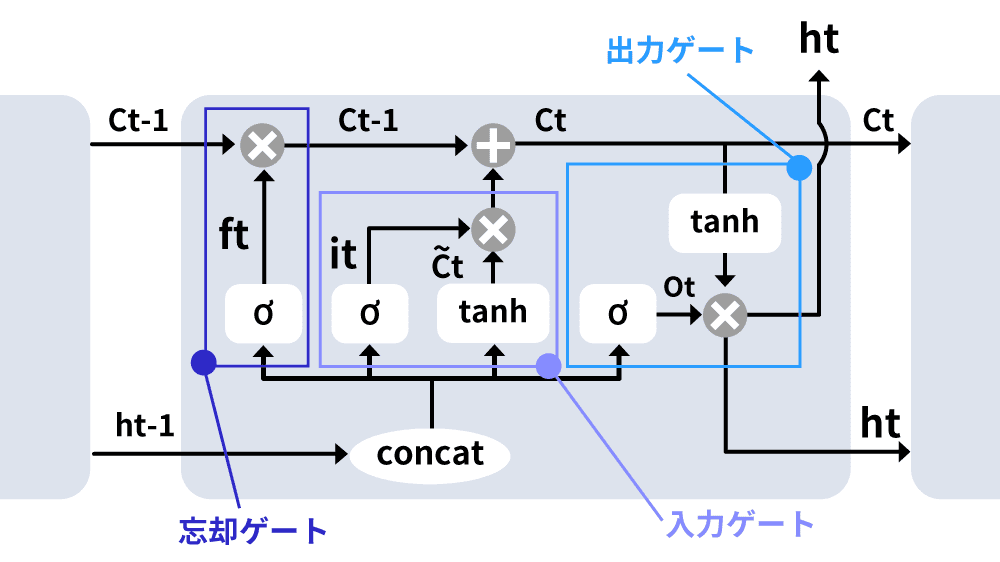
LSTM(Long Short-Term Memory)は、長期的な時系列データを扱うことができる手法です。RNNでは学習時に発生する勾配消失問題(誤差逆伝播法で各層の間の重みを修正するときに、深層にわたって伝えられる勾配が小さくなる問題)」により長い時間軸の記憶維持が困難であるという課題がありました。LSTMでは、ゲートと呼ばれるメカニズムを持ち、入力・忘却・出力を制御することで、適切な情報のみを長期記憶として保存でき、高い性能を発揮できるようになりました。
Generative Adversarial Networks(GAN)
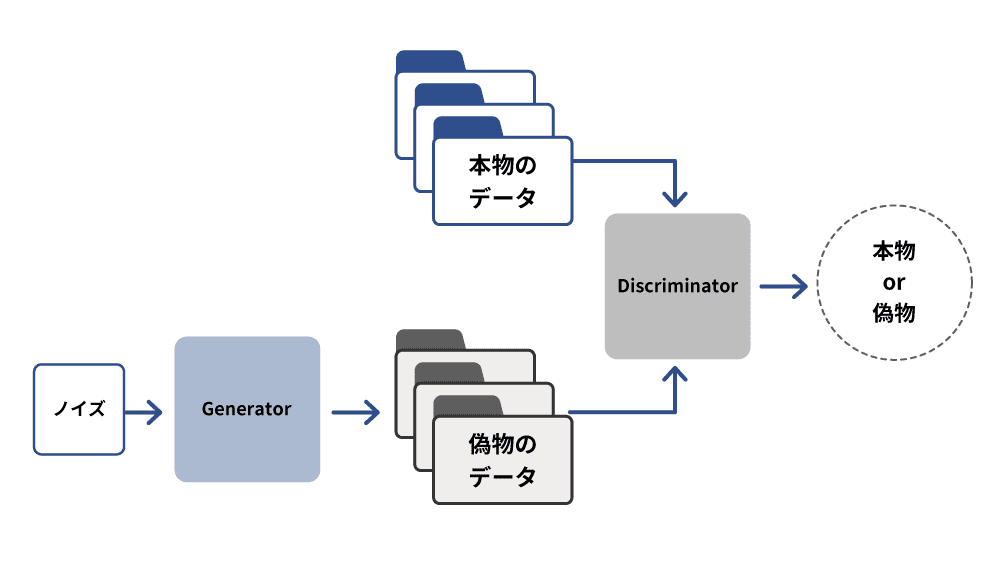
Generative Adversarial Networks(GAN、敵対的生成ネットワーク )は、2つのネットワークが相反した目的のもとに学習するネットワークモデルであり、教師なしの学習モデルです。ジェネレーター(生成器)とディスクリミネーター(識別器)という2つのニューラルネットワークから構成され、ジェネレーターがランダムに画像を生成し、学習用の正しい画像であるディスクリミネーターに近づけようと学習を繰り返すことで精度を挙げていく手法です。
GANは特に画像生成に優れており、GANは質の低い画像データからでも高品質な画像データを生成することが可能であり、テキストデータからでも画像生成をすることができます。
Transformer(トランスフォーマー)

Transformer(トランスフォーマー) は、2017年に発表された深層学習モデルであり、主に自然言語処理 (NLP)の分野で使用されています。RNNと同様に時系列データを使った翻訳やテキスト要約などのタスク用に設計されていますが、時系列データを逐次処理する必要がないため、短い学習時間で大きな成果を上げることができます。データのどこに注目すべきかを推測する特徴があり、自然言語では文章中のどの単語に注目すれば文章の意味を理解しやすいかをスコアリングして評価します。
ディープラーニングの活用事例
ディープラーニングにより、従来ではデジタル化するのが難しかった非構造化データ(画像、自然言語、音など)をAIが学習できるようになりました。データ処理の範囲が広がったことにより、最適化やレコメンデーションの精度が向上し、画像認識や音声認識などのさまざまな場面において活用されています。
画像認識
画像認識は、大量の画像データに何が映っているのか特徴をつかみ、画像に写る物体を識別するパターン認識技術です。画像解析ではデータを解析、分析し、データ内に映っている画像の行動や特徴を検知して生成を行う技術です。
音声認識
音声認識は、人間の話す声をテキストに変換したり、発生している人を識別する技術です。スマートスピーカーやスマートフォンのアシスタントアプリなどで利用されています。ディープラーニングを活用することで高い認識精度を実現し、自然な言語処理ができるようになりました。
自然言語処理
自然言語処理は日常的に会話する言語や文章などの自然言語(話し言葉や書き言葉)を対象とした解析処理技術です。日常会話では、同じ言葉でも別の意味を持つ場合や文脈によって意味が変わることがあり、曖昧さが含まれています。自然言語処理ではテキストデータを解釈し、文脈や意味を考慮して処理することで自動翻訳、ブラウザの検索、コールセンターでの問い合わせ対応などに活用されています。
異常検知
異常検知とは、センサーから収集した時系列データを使って他と異なるパターン(異常)を特定し検出する技術のことです。工場での機器故障、異常動作の検出、セキュリティ監視、設備管理、品質管理などさまざまな領域で重要な役割を担っています。
予測
予測とは、データ内の時系列パターンを学習し、傾向から将来発生する可能性の高い事象を出力することです。気象データから天候を予測する際に利用されますが、将来の製品の需要を予測し、企業の生産計画や在庫管理などの販売戦略に利用されることもあります。
レコメンデーション
レコメンデーションとは、大量のデータから対象者の嗜好性を分析し、有益な情報(お勧め情報)を提供する技術です。特にWEBマーケティングでは広告や検索エンジンに利用され、顧客の指向性に合わせた誘導を行う際に使われます。
ディープラーニングの課題
データとリソース
ディープラーニングの学習のためには大量、かつ、高品質なデータを必要とします。そのため、特定のタスクのデータが不足している場合には学習の進捗や汎用性に制限が生じる可能性があります。また、膨大なデータを処理することになるため、高性能なコンピュータが必要であり、分散処理が必要になることもありえます。
過学習
過学習とは機械学習の際にデータの傾向に合うように学習した際、学習したデータに対しては非常に良い精度を出すが、学習していないデータに対しては高い精度を出すことができないモデルを構築してしまうことです。ディープラーニングを行った結果、過学習に陥ってしまう可能性があり、解決するためには人間が介在し、モデルの複雑さを抑える必要があります。
倫理的な問題
ディープラーニングに限らず、AIを利用する際には常に倫理的な問題に直面する可能性があります。ディープラーニングは訓練データに依存した出力をするため、学習データにバイアスがある場合には意思決定が正しくならないことがありえます。AIによる出力には倫理的な問題以外にもハルシネーションや著作権の問題なども出てくることが考えられます。
最後に
ディープラーニングは、ニューラルネットワークを多層化することで、従来の手法では難しかった非構造化データの解析を飛躍的に向上させました。特に画像認識や自然言語処理など、AIの中核的な技術として重要な役割を果たしています。この技術は、入力データから複雑なパターンや規則を自動的に抽出し、精度の高い予測や判断を可能にします。
また、ディープラーニングは自動運転やレコメンデーションシステムなど、幅広い分野で活用されており、その応用は日々拡大しています。今後もディープラーニングの技術革新が続くことで、さらなる進化が予測されており、ビジネスにおける変革が一層進むことが期待されます。







