
クラスタリングとは、データを類似性に基づいて複数のグループに分ける手法であり、マーケティング、医療、異常検知、データ分析など、さまざまな分野で幅広く利用されています。クラスタリングには階層型と非階層型の手法があり、データの特性や目的に応じて使い分けることが重要です。階層型はデータを階層的に分類し、グループの構造を視覚化できる一方、非階層型は大規模なデータを効率的に処理します。また、ハードクラスタリングとソフトクラスタリングの選択により、データの柔軟な分類が可能になります。

クラスタリングとは
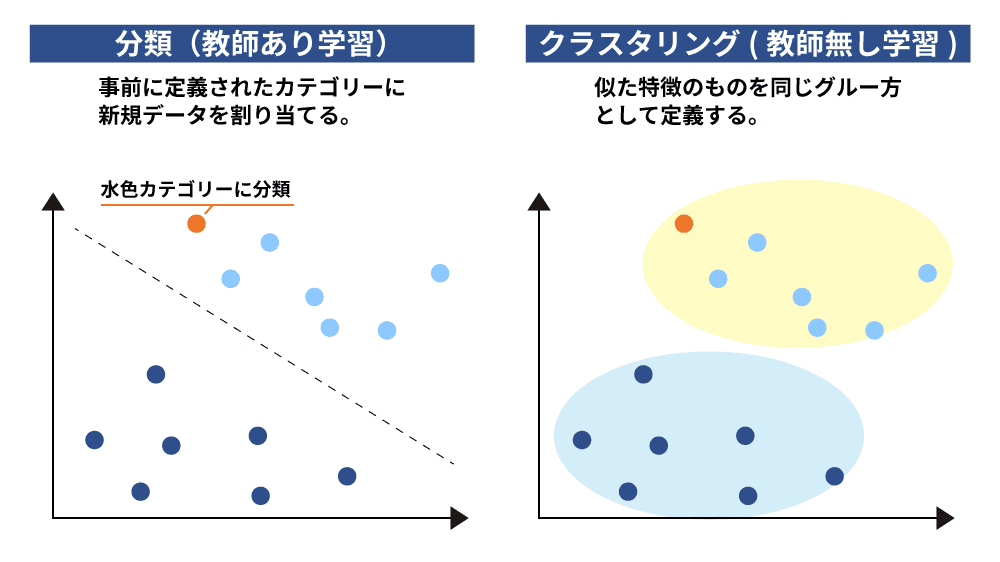
クラスタリングとは、データセットを類似性に基づいて複数のグループ(クラスター)に分類する機械学習の手法の1つです。データから導き出された客観的な分類ができる点が特徴で、マーケティングやアンケート分析などのビッグデータを扱う場面でよく活用されます。クラスタリングのメリットはデータにあらかじめラベルを付ける必要がないため、大量のデータを効率的に分類できる点にあります。
クラスタリングには主に階層型と非階層型の手法があります。階層型クラスタリングはデータを階層的にグルーピングしていく方法で、計算量が膨大になるためビッグデータの処理には向きません。一方、非階層型クラスタリングは階層構造を作らずにデータをグルーピングし、大量のデータにも対応可能です。用途に応じて、これらの手法を使い分けることが求められます。
クラスタリングは機械学習の中でも教師なし学習に分類されます。教師なし学習は、事前に正解を与えず、データの隠れたパターンや構造を発見することを目指します。これに対して、事前に正解を与えて学習させる教師あり学習もありますが、クラスタリングの強みは未知の構造を自動的に見つけ出す点にあります。
また、クラスタリングにはハードクラスタリングとソフトクラスタリングという分類方法があります。ハードクラスタリングは各データを1つのクラスタにのみ所属させる方法であり、ソフトクラスタリングはデータが複数のクラスタに同時に所属することを許容します。2つの手法により柔軟なデータ分類が可能となります。
現代では膨大なデータから有用な情報を引き出すことが企業や研究機関にとって大きな課題となっています。クラスタリングはデータ間の関連性を明らかにし、新たな洞察を得るための重要な手段です。ビジネスや科学研究において、クラスタリングは単なるデータの分類を超えて、未知の相関関係を発見し、データ駆動型の意思決定を強化する役割を果たしています。
クラスタリングの種類
クラスタリングには階層型クラスタリングと非階層型クラスタリング、そしてハードクラスタリングとソフトクラスタリングの2つの観点で分類されます。
クラスタリングの手法は、データの規模や構造、分析の目的に応じて使い分ける必要があります。例えば、少数のデータで階層的な構造が見えやすい場合には階層型クラスタリングが適していますが、大量のデータを扱う場合やクラスタ数が事前に予測できる場合には非階層型クラスタリングが有効です。また、明確に1つのクラスタに分類できるデータにはハードクラスタリングが適していますが、曖昧なデータにはソフトクラスタリングを用いることで、より適切な分類が可能になります。
それぞれの手法は異なる特徴と用途を持ち、データの性質や目的に応じて使い分けが必要です。
| 種類 | 階層型クラスタリング | 非階層型クラスタリング |
| 概要 | データの類似性を距離とし、段階的にクラスタを形成する(階層構造) | 階層を作らずにグルーピングする |
| 代表的な手法 | ウォード法、重心法、最短距離法(最長距離法)、群平均法 | k-means法、混合正規分布 |
階層型クラスタリングと非階層型クラスタリング
階層型クラスタリングは、データを類似度の近いものから順にグループ化していく手法です。観測データ同士の類似度を距離として定義し、最も距離が近いデータから順にグループを形成します。この手法では、すべてのデータがグループ化されるまでの過程が「樹形図(デンドログラム)」として可視化できるため、階層的な構造が理解しやすいのが特徴です。メリットとしては、データを視覚的に確認しやすい点が挙げられますが、計算量が増大するため、数百を超える大規模なデータには不向きです。小規模なデータセットで特に有効です。
非階層型クラスタリングは、データをあらかじめ設定したクラスタ数に基づいて分類する手法です。階層を形成せず、データの全体から近いデータをまとめてクラスタを作成します。計算速度が速いため、数百から数千のデータを扱うビッグデータ分析に適していますが、クラスタ数を事前に設定する必要があるため、データの構造に対する予備知識が求められます。例えば、マーケティングや市場のセグメント化で広く活用されます。
ハードクラスタリングとソフトクラスタリング
ハードクラスタリングは、各データを必ず1つのクラスタに割り当てる手法です。ハードクラスタリングでは、データは一意にしか分類されず、どのクラスタに属するかが明確に決まります。計算が高速で解釈も容易であるため、シンプルなグループ分けが求められる場合に有効です。ただし、複数のクラスターにまたがるデータの扱いには適していません。
ソフトクラスタリングでは、データが複数のクラスターに同時に所属する可能性を許容します。各データがどのクラスターに属するかを確率的に評価し、特定のクラスターに完全に属するのではなく、複数のクラスターにまたがる形でグルーピングされます。ソフトクラスタリングでは、データが曖昧で多義的な場合に適しており、より柔軟な分析が可能ですが、計算や解釈が複雑になるという側面があります。
クラスタリングのメリット
クラスタリングは、マーケティング戦略やデータ分析において重要な役割を果たし、多岐にわたる利点を提供します。最適なターゲット市場の選定や競合との差別化、テストマーケットの選定、さらには膨大なデータの構造化や効率的な処理など、さまざまな場面で活用されています。
ターゲット市場を選定できる
クラスタリングは顧客の属性に基づいて市場を細分化し、最適なターゲット市場を選定する際に効果的です。この作業はセグメンテーションと呼ばれ、性別や年齢、興味関心といった属性を基に顧客を分類し、特定のグループに対して自社製品やサービスを最適に訴求できます。クラスタリングを用いることで顧客の特性に合わせたマーケティング戦略を効果的に策定でき、製品の訴求力を高めることが可能になります。
競合と差別化できる
クラスタリングは自社の製品やサービスが他社とどのように異なるかを分析するための有力な手法です。新製品の市場投入に際して、クラスタリングにより競合他社の製品と自社製品を比較することで、自社の強みや独自性を見つけ出し、効果的な差別化戦略を展開することができます。また、クラスタリングを通じて未開拓の市場を発見することも可能です。
効果的なテストマーケットを選定できる
マーケティング施策の事前評価として実施されるテストマーケットの選定にもクラスタリングは役立ちます。クラスタリングにより、異なる市場間の特徴を把握し、テストマーケットを効率的に選定することで、マーケティング施策の成功確率を高めることができます。テストの網羅性と市場間の異質性を担保できるため、より効果的な事前評価が可能となります。
膨大なデータを構造的に捉えることができる
クラスタリングは膨大なデータを効率的に構造化するためのツールとしても優れています。手動では処理が難しい大量のデータを分類し、顧客の性別や年齢、興味関心などの詳細な分析が可能です。データをグループ化することで、個々の顧客グループに対する理解が深まり、セグメンテーションや市場分析の精度が向上します。
人には気づきづらい特徴を発見できる
クラスタリングによる客観的な分析は、従来の主観に基づく分析では見つけられない特徴を発見するのに役立ちます。固定概念にとらわれることなく、データから新しいパターンや傾向を導き出すことができるため、新しい市場やニーズを見つけ、競合との差別化にもつながります。クラスタリングの柔軟性が、未知のインサイトの発見を可能にします。
データ処理の効率化が図れる
クラスタリングは、大量のデータを効率的に分析し、分類する能力を持っています。ラベリングを必要としないため、大規模なデータでも迅速に処理でき、効果的なテストマーケットの選定など、時間やコストを削減することができます。クラスタリングを通じて、データの分類と処理がより効率的に行えるため、ビジネスにおいても迅速な意思決定を支援できます。
階層的クラスタリングの手法
階層的クラスタリングは、データ同士の類似度を基にしてクラスタを形成する教師なし学習の手法です。人間が正解を与えることなく、データ間の距離を計算し、距離が近いデータ同士を順にグループ化していきます。この過程は樹形図(デンドログラム)で視覚的に表現され、どのデータが似ているか、クラスタ数をいくつに設定すればよいかが分析できる点が特徴です。
特に、ボトムアップ的にデータを結びつける凝集型階層的クラスタリングは、観測値の類似性に基づき、小さなクラスタを少しずつ統合していく手法であり、データの階層的な構造が明らかになるため、分析の幅が広がります。
ウォード法
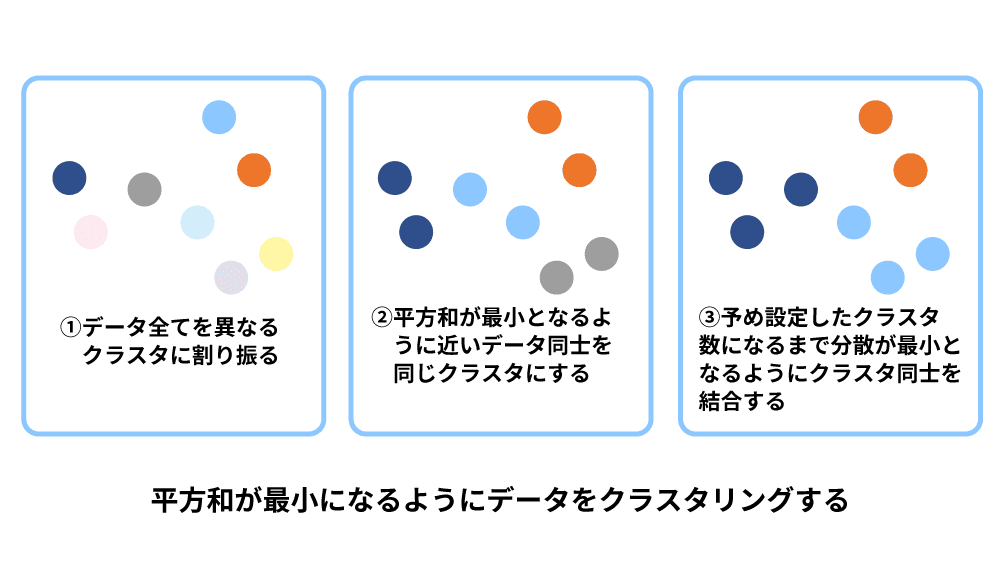
ウォード法は、データのばらつきを最小化しながらクラスタを形成する階層的クラスタリング手法の1つです。この手法では、まず各データ点を個別のクラスタとして扱い、徐々に距離が最も近いクラスタ同士を結合していきます。結合する際に基準となるのは、データの平方和(各データとそのクラスタの平均値との差を二乗した値の合計)です。平方和が小さいほどデータのばらつきが少なく、似ているとみなされます。計算量が多いものの、直感的に納得しやすい結果が得られるため、データ分析において広く使用されています。
重心法
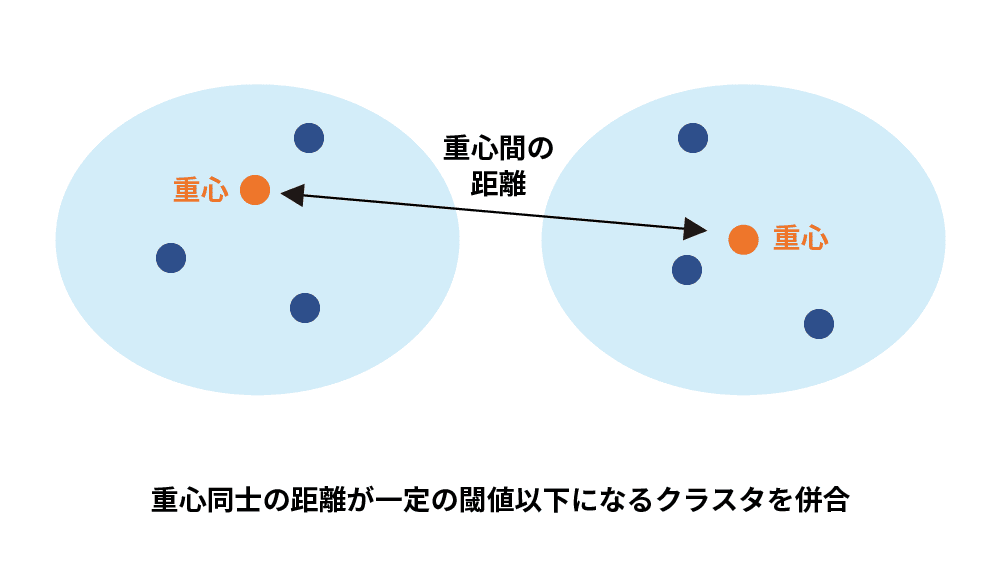
重心法は、クラスタ間の距離を各々のクラスタの重心間の距離として定義する手法です。各クラスタの重心(平均的なデータ点)を計算し、重心同士の距離が一定の閾値以下になるとクラスタを併合していきます。比較的直感的な方法ですが、デメリットとして階層の反転現象が発生することがあり(本来は併合しないような、遠くに存在するクラスタが先に併合されてしまうこと)、期待しているクラスタリングが実現しにくくなる場合があります。
最短距離法(最長距離法)
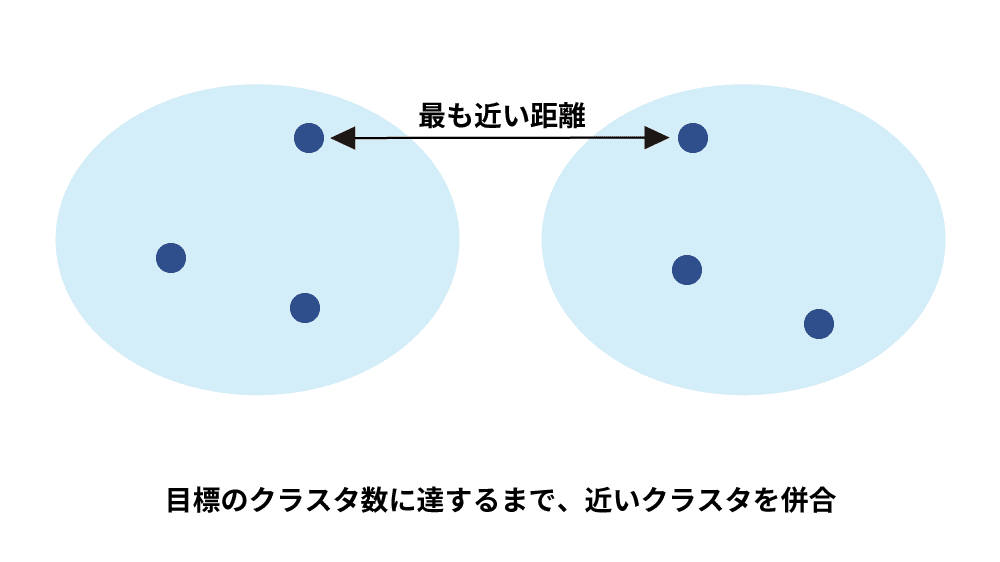
最短距離法は、クラスタ間の距離を最も近いデータ同士の距離として定義する手法で、単連結法とも呼ばれます。クラスタを構成するデータ同士の距離をすべて計算し、その中で最も距離が短い組み合わせを選び、クラスタ間の距離として扱います。目標のクラスタ数に達するまで、近いクラスタを併合します。計算量が少なく、ウォード法などと比較して効率的ですが、外れ値に弱い側面があります。また鎖効果と呼ばれる帯状のクラスタが形成されやすく(全体のデータが遠く離れていても、少しずつ最も近いデータ同士がつながっていくことで、細長い帯のようなクラスタが形成されること)、分類精度が低くなることがあります。
一方、最長距離法は最も遠いデータ同士の距離をクラスタ間の距離とする手法です。完全連結法とも呼ばれ、計算量が少ない点がメリットですが、外れ値に対して同様に弱いという特徴があります。
群平均法
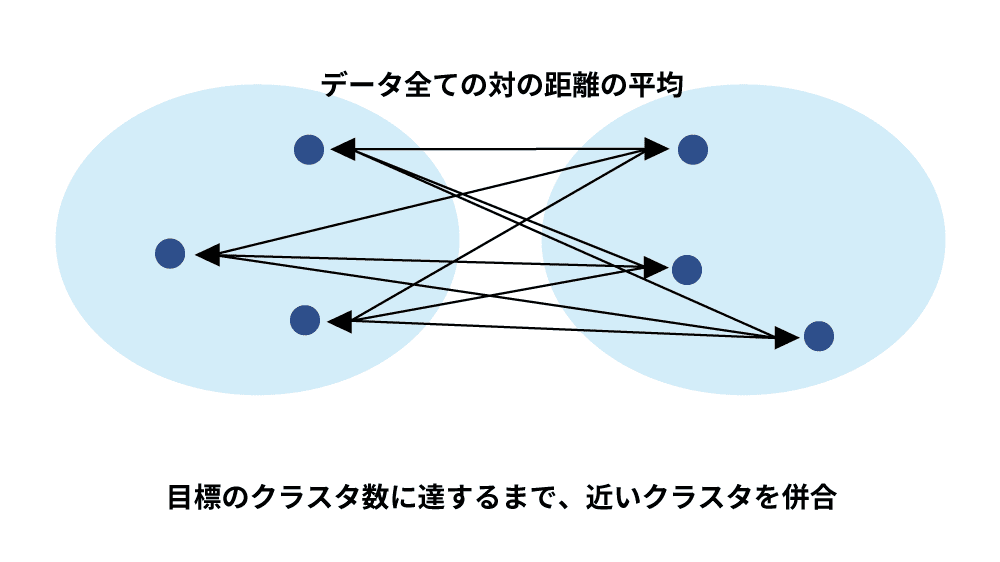
群平均法は、2つのクラスタを構成するデータ同士の全組み合わせの距離を求め、その平均をクラスタ間の距離として定義する手法です。目標のクラスタ数に達するまで、近いクラスタを併合します。外れ値の影響を受けにくく、最短距離法や最長距離法と比べて安定した結果が得られるのが特徴です。また、クラスタが帯状に連なる鎖効果を防ぐことができるため、バランスの取れたクラスタリングが可能です。計算量は比較的軽く、特に大量のデータを扱う場合にも有効です。
ウォード法と比較すると、クラスタ内の分散を最小化する点では劣る場合がありますが、計算の効率性や安定性を求める場面では群平均法が適した選択肢となります。
非階層的クラスタリングの手法
非階層的クラスタリングは、階層構造を持たずにデータを直接的にグループ分けする手法です。あらかじめ指定されたクラスタ数に基づいて、母集団の中から近いデータをまとめ、クラスタに分類します。一度クラスタを形成すると後から自由に変更できないため、最初にクラスタ数を適切に設定することが重要です。処理速度が速く、大量のデータや明確なクラスタ数が事前にわかっている場合に特に有効です。
階層的クラスタリングと異なり、非階層的クラスタリングはグループを固定的に設定し、データ全体の中で類似性が高いデータを直接分類するため、より目的志向的なアプローチとなります。
k-means法(k平均法)
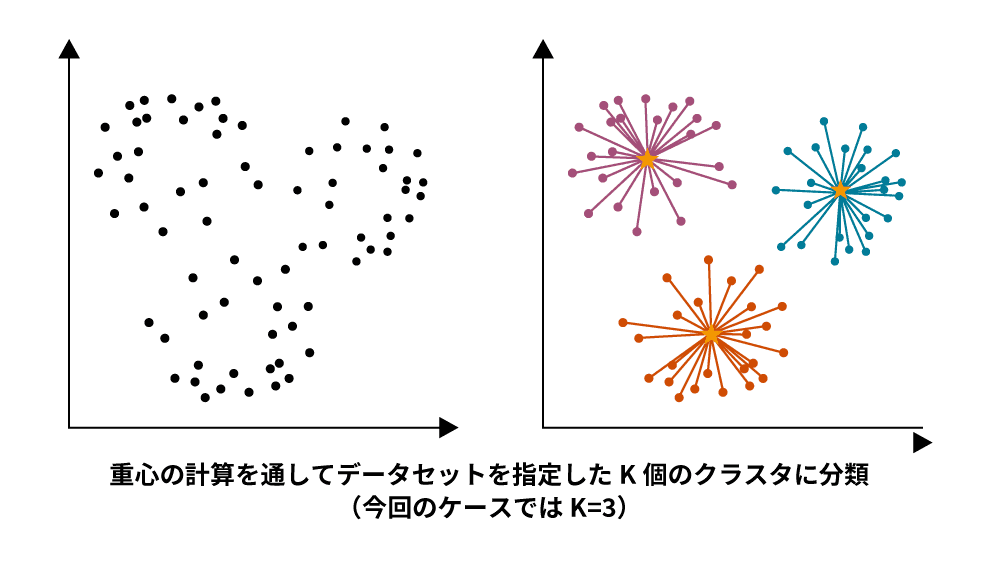
k-means法(k平均法)は、最も基本的なクラスタリング手法の1つで、似た特徴を持つデータを指定されたk個のグループに分けるアルゴリズムです。最初にランダムに配置された中心点(重心)に基づいて、各データを最も近い重心に割り当て、各グループの重心を再計算します。このプロセスを、重心が動かなくなるまで繰り返すことで、最適なクラスタ分けが達成されます。非階層型クラスタリングとして、データ間の距離を効率的に扱うことができます。
ただし、初期の中心点がランダムに設定されるため、中心点が近すぎると分類がうまくいかない場合があり、結果が異なる可能性があります。そのため、k平均法を適用する際には、複数回の試行を行い、最も適したクラスタ分けを選ぶことが重要です。
混合正規分布
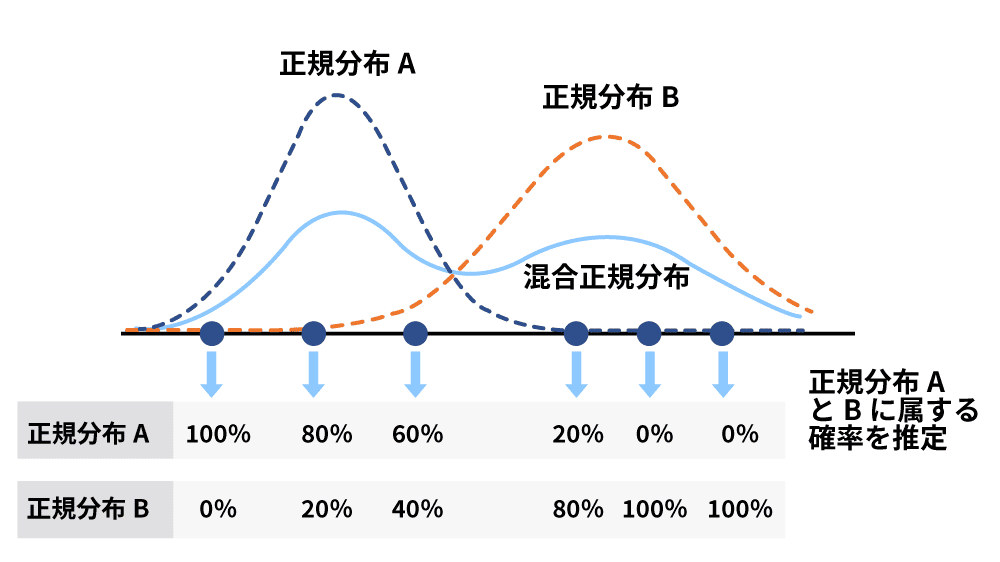
正規分布(ガウス分布)は、左右対称で釣り鐘型の確率分布を示すグラフです。これを複数重ね合わせてデータをグループ分けしたり、確率分布を推定する方法が混合正規分布(混合ガウス分布)です。混合正規分布では、データが異なる正規分布から生まれたと仮定し、そのデータがどの正規分布に最も近いかを推定して、グループ分け(クラスタリング)または確率分布の推定を行います。
k-means法と混合正規分布の違いは、k-means方がデータ点を1つのクラスタに固定するハードクラスタリングであるのに対し、混合正規分布は各データ点が複数のクラスタに所属する確率を計算するソフトクラスタリングである点です。ただし、混合正規分布とk-means法のアルゴリズムは、特定の条件下では一致するため、理論的には近い関係にあります。
クラスタリングを行う際の注意点
目的を明確にして分析する
クラスタリングを行う前に、必ず分析の目的や仮説を明確に立てておくことが必要です。目的が不明確なままでは、どのデータを分析するべきか、得られた結果をどう活用するかが分からなくなります。クラスタリングで得られるのはあくまでデータの構造化結果であり、どのようにマーケティングや戦略に役立てるかを考えることは人間が行うべき作業です。また、仮説を立てることで、予測と結果のずれから新たな発見を得ることができます。
計算に時間がかかる
クラスタリングはデータ数が多くなるほど計算量が増え、特にビッグデータの分析では処理時間が長くなります。階層的クラスタリングでは全データの組み合わせを計算するため、特に時間がかかりやすく、結果が複雑になりすぎることもあります。そのため、データの規模に応じた適切な手法を選択することが求められます。また、クラスタリング後の結果を解釈する際には、他の分析手法と組み合わせて詳細に検証する必要があるため、追加の時間がかかる場合もあります。
精度の評価が難しい
クラスタリングの結果は使用するアルゴリズムやクラスタ数の設定によって変わりやすく、精度の評価が難しいことが多いため、複数の手法を試して結果が安定しているかを検証することが重要です。また、結果の解釈には主観が入りやすいため、仮説や固定観念にとらわれず、データに基づいた客観的な評価を行うことが必要です。
クラスタリングの活用事例
AIチャットボットのチューニング
チャットボットを効果的に運用するためには、問い合わせ内容の分析や回答の最適化が必要ですが、従来は人間が手動で行うことが多く、手間がかかっていました。クラスタリングを活用することで、問い合わせ内容を分類し、効率的に応対のパターンを見つけ出すことが可能になり、チャットボットのチューニング作業が自動化され、業務効率が大幅に向上します。
医療画像の解析
クラスタリングは、医療分野でも活用されています。例えば、CT画像をクラスタリングすることで、病変の分類や進行度の評価が可能になります。これにより、医師が迅速かつ正確な診断を行うための補助ツールとして機能します。特に新しい疾患の解析や、従来の診断方法では難しい症例の分類において有効です。
顧客データのセグメンテーション
マーケティング活動では、クラスタリングは顧客データの分析に活用されます。アンケートや市場調査のデータをクラスタリングすることで、顧客の特性に基づいたグループ分けが可能となり、効果的なマーケティング戦略を立てることができます。新たなターゲット層やペルソナを発見することで販売戦略を最適化できます。
異常検知
製造業や医療業界ではデータセットの中で大多数とは異なる振る舞いを示すデータ(異常値)を検出するためにクラスタリングが用いられます。異常なデータがクラスタリングによって分類されることで、問題の早期発見や品質管理が向上します。
画像や音声データの分類
クラスタリングは、画像や音声データの分類にも利用されます。大量の画像や音声データを自動的にジャンルごとに分類することで、効率的なデータ管理が可能となります。従来の人間の判断に頼っていた分類作業が、クラスタリングを使うことで新しい発見をもたらすこともあります。
探索的データ解析(EDA:Exploratory Data Analysis)
データの中に潜在するパターンや相関関係を明らかにするために、クラスタリングを使ってグループ化し、その結果を基にサンプリングや異常値検出などに活用します。データ全体の傾向をつかみやすくなり、分析の方向性を見出すことができます。
最後に
クラスタリングはデータの構造を明らかにし、膨大な情報から有用なインサイトを引き出すための強力な手法です。様々な手法を適切に使い分けることで、さまざまな用途に応じたデータの分類が可能になります。クラスタリングは、マーケティングや医療、異常検知など多岐にわたる分野で効果を発揮し、データ駆動型の意思決定を支援するツールとして重要な役割を果たします。







