
BERTとは、Googleが2018年に発表した自然言語処理のディープラーニングモデルです。BERTは単語の前後関係を同時に把握する双方向性によって、曖昧な表現の解釈や文脈の理解を可能にし、文章の意味を正確に読み取ります。BERTはWikipediaの膨大なデータで事前学習され、質問応答や文章分類、感情分析など多様なNLPタスク(自然言語処理)に適応できる汎用性を持っています。従来の片方向的なモデルに比べて文脈を深く理解する能力が高く、検索エンジンや音声認識、チャットボットなど多くのアプリケーションで活用されています。自然言語処理の分野に革新をもたらしたBERTは、現在も高精度なNLP技術の基盤として進化し続けています。

BERTとは
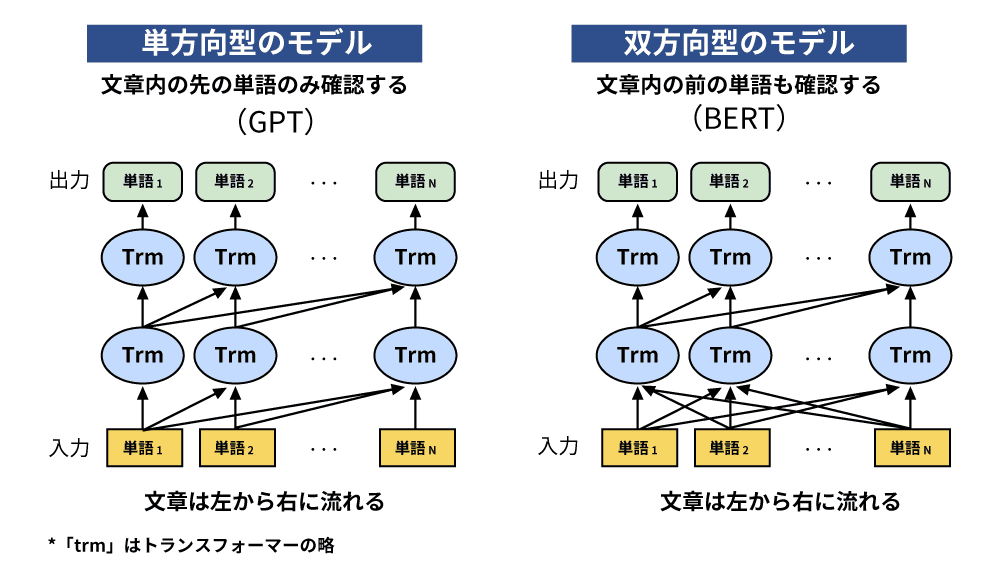
BERT(Bidirectional Encoder Representations from Transformers)は、自然言語処理(NLP)のために開発されたディープラーニングモデルで、2018年にGoogleによって発表されました。BERTは、文中の単語の前後関係を同時に捉える双方向性を持つため、テキスト内のあいまいな表現を理解するのに適しています。
BERTは、Wikipediaなどの膨大なデータで事前学習されており、質問応答や文章分類、感情分析などのさまざまなNLPタスクに転移学習で応用可能です。特に、Transformerというモデル構造を採用することで、文の前後を同時に理解する双方向性を実現しており、BERTは従来の片方向性モデルに比べて文脈を深く理解できるようになりました。
BERTの学習にはMasked Language Model(MLM)とNext Sentence Prediction(NSP)の2つの手法が使われています。MLMでは文中の単語を隠し、周囲の文脈から隠された単語を予測するように学習します。また、NSPでは2つの文が論理的な関連を持つかを予測し、文章のつながりを学習します。
BERTは高精度なNLPモデルとして、さまざまなベンチマークタスクで最先端の性能を記録しており、NLPの分野で大きな注目を集めました。膨大なラベル未付与データを活用できるため、従来のデータ不足の課題も克服しています。BERTの登場により、自然言語処理は検索エンジンの高度化や音声認識など、多様なアプリケーションに広がっています。

BERTの歴史
2017年にGoogleはTransformerモデルを導入し、自然言語処理(NLP)に新たな展開をもたらしました。当時は、主に再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)が使用されており、データを固定された順序で処理する必要がありました。しかし、Transformerは任意の順序でデータを処理できるため、大規模なデータを効率的に学習することが可能となり、BERTのような事前学習済みモデルの開発が容易になりました。
2018年、GoogleはBERTを発表し、オープンソース化しました。BERTは感情分析やテキスト分類、多義語の解消など、11の自然言語理解(NLU)タスクで最高水準の結果を達成し、既存のword2vecやGloVeといったモデルと異なり、文脈や曖昧な表現の理解を大幅に向上させ、BERTは自然言語処理における最大の課題である曖昧さの解決に大きな進展をもたらしました。
2019年10月、Googleはアメリカの検索アルゴリズムにBERTを導入し、米国英語の検索クエリの約10%に対する理解度が向上したと発表しました。BERTは自然な検索体験を提供することを目指しており、GoogleはコンテンツをBERT向けに特別な最適化を行わず、自然なクエリと自然なユーザー体験に重きを置くよう推奨しています。
また、BERTはその後、多くのAIシステムに影響を与え、軽量版や類似のトレーニング方法がGPT-2やChatGPTといったモデルにも応用されています。
BERTの目的
BERTの主な目的は人間の言語理解能力に近い精度で自然言語を処理し、テキストから意味を抽出することです。
文章の要約や文書分類、感情分析、機械翻訳、質問応答といった多様な自然言語処理タスクを高精度で実現することができ、多くの言語や分野に適用可能であるため、グローバルな自然言語処理技術として注目されています。高い精度と汎用性を備えるBERTはビジネス、医療、政治など様々な分野で活用されており、オープンソースとして公開されているため、誰でも利用できる点も自然言語処理技術の発展に大きく貢献しています。
BERTが検索エンジンに採用された背景には、モバイル端末の普及による検索クエリの多様化や、AIアシスタントの普及による音声検索の増加が挙げられます。音声検索では「電気を付けて」や「明日の天気は」といった自然な言語が使われるようになり、これに対応するためにBERTが導入されました。
BERTの特徴
BERTは、従来のGPTやELMoとは異なり、双方向から文脈を理解できるため、単語同士のつながりを把握し、高精度な自然言語処理が可能です。Google検索でも検索意図をより正確に捉え、「to」などの重要な関係詞も適切に解釈されるようになりました。また、BERTは転移学習により多様なタスクに応用できる汎用性があり、特定のデータに依存せず、ラベルなしデータを使って効率的に学習できる点でも評価されています。
高精度な言語処理
BERTが登場する以前、GPTやELMoといった言語モデルが自然言語処理に利用されていました。GPTは未来の単語のみを予測する単一方向モデル、ELMoは双方向モデルですが、文脈を理解することはできませんでした。しかし、BERTは双方向から文脈を読み取る機能を持ち、単語同士のつながりを理解することで、より精度の高い自然言語処理が可能となりました。
BERT導入以前のGoogle検索では、例えば「to」のような語の関係を正しく処理できず、検索意図を誤解することがありました。例として、「2019 brazil traveler to usa need a visa」という検索クエリでは、検索者は「ブラジルからアメリカへの旅行者にビザが必要か」を知りたい意図がありますが、BERT以前は「to」を正しく解釈できないため、「ブラジルへのアメリカ人旅行者」と誤解することがありました。BERTの導入により、このような誤解が解消され、検索意図に沿った結果が表示されるようになりました。
参考:Understanding searches better than ever before(Google)
高い汎用性
BERTはその汎用性の高さから、さまざまなタスクに応用が可能です。従来のモデルは特定のタスクに特化していましたが、BERTはファインチューニングによって既存のタスク処理モデルに簡単に接続し、精度を向上させることができます。そのため、特定のタスクに制約されず、多様な自然言語処理タスクに活用され、高い評価を得ています。
学習データ不足への対応
BERTは、ラベルなしデータを活用して学習できるため、学習データが少ない状況でも効果的に機能します。自然言語処理においてラベル付きデータは限られており、作成には時間と労力が必要ですが、ラベルなしデータは豊富に存在します。BERTはラベルなしデータを使って効率的に学習することで、データ不足の問題を克服し、学習データに依存しないモデルとして高く評価されています。
BERTの仕組み
自然言語処理(NLP)の目標は、人間が話すように自然な言語を理解することです。BERTの場合、これは文中の空白に入る単語を予測する能力を持つことを意味します。従来、このようなモデルには、言語学者がラベル付けした専門的なデータセットが必要とされてきましたが、BERTはラベルなしのプレーンテキスト、具体的には英語版WikipediaやBrown Corpusといった大量のデータで事前トレーニングされています。BERTは教師なし学習を通じて継続的に改善され、Google検索などの実アプリケーションで使用されています。
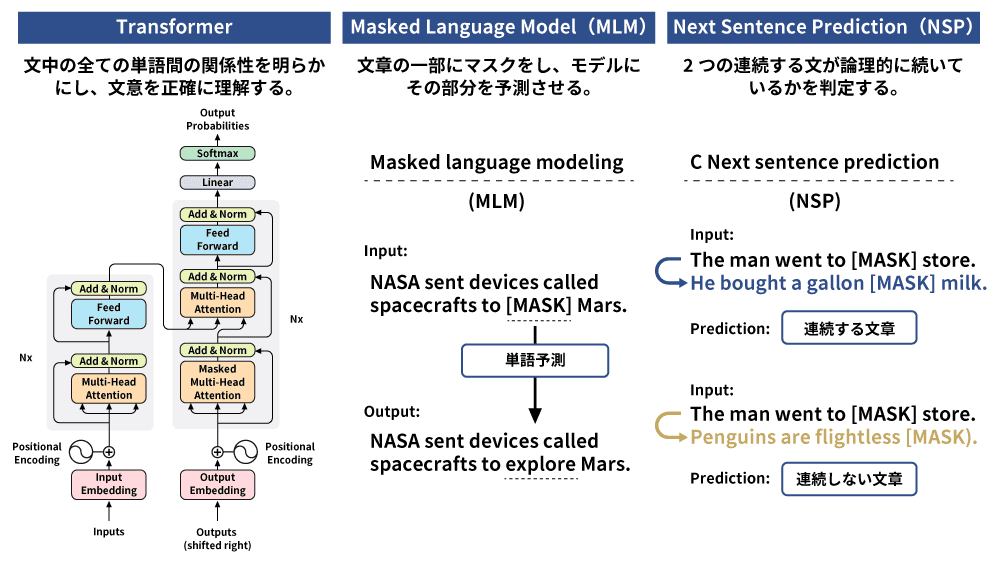
BERTの事前トレーニングは知識の基礎を構築し、転移学習によって検索クエリやユーザーのニーズに合わせて微調整されます。BERTの学習はTransformerを用いた双方向の文脈理解を特徴としており、特定の単語を左右の文脈から同時に予測します。この手法には、Masked Language Model(MLM:穴埋めクイズ)とNext Sentence Prediction(NSP:隣接文予測)の2つの手法が使用されています。
BERT以前にも事前学習モデルは存在し、例えばGPTやELMoが挙げられます。しかし、GPTは単一方向で特定の単語の前後の一方向しか予測できず、ELMoは双方向性が浅いため、BERTほどの精度は実現できませんでした。BERTは双方向性の高いTransformerアーキテクチャを活用することで、文脈を深く理解するモデルとなっています。
BERTの事前学習データは、分散表現と呼ばれる高次元ベクトルに変換され、意味の近い単語同士が近くに配置されます。これを各タスクに応じて転移学習することで、目的に特化した高精度な出力が得られます。このように、BERTはシーケンス(文章)を入力とし、特定のタスクに応じた処理を可能にする柔軟性を持っています。
Transformer
GoogleのTransformerの導入により、BERTが実現しました。Transformerは、BERTが言語の文脈や曖昧さを深く理解するための重要な基盤となっています。Transformerは各単語を文中のすべての単語との関係で処理し、単語の完全な文脈を把握できるようにすることで、検索者の意図をより的確に捉えます。
従来の単語埋め込み手法(GloVeやword2vecなど)は、単語を固定のベクトルにマッピングし、意味の一側面のみを表現していましたが、Transformerは入力トークン同士の相対的な重要度を評価することで、文章全体の文脈を理解します。このメカニズムにより、Transformerは文中の長距離依存関係も効果的に扱えるため、機械翻訳や感情分析、テキスト生成といった自然言語処理タスクで高い精度を発揮しています。
Masked Language Model
Masked Language Model(MLM)は、文章データ内のランダムに選ばれた15%のトークン(単語や文字列)をマスクし、モデルにその部分を前後の文脈から予測させる手法です。MLMは、一部の単語のみを予測対象とするため、全体を予測するより処理が効率的ではない点もありますが、文脈の理解を深めることに効果的です。
MLMによって、モデルはシーケンス内(文章の区切り)で隠されたトークンの前後の関係を学習し、単語の文脈的な意味を理解します。この仕組みは、BERTが文章分類や名前付きエンティティ認識(≒品詞の認識)、センチメント分析といった特定のタスクに対応する際の基盤となっています。
BERT以前の自然言語処理モデルは、文章を単一方向からのみ処理していたため、特定の単語を前後両方から予測することはできませんでした。しかし、BERTはTransformerを使って双方向から文脈を学習し、精度を大幅に向上させています。この双方向性を実現しているのがMasked Language Modelです。
Next Sentence Prediction
Next Sentence Prediction(NSP)は、BERTが文章間の関係を学習するための手法で、2つの文が論理的に続いているかを判定します。学習データ内の2つの文のうち、後者を50%の確率で無関係な文に置き換え、前者と後者が順序通りに続く(IsNext)か、関係がない(NotNext)かを判断することにより、文と文の間の論理的な関連性を理解する力を養い、検索や自然言語理解タスクの精度を高めています。
NSPの学習には大量のデータと高いコストが必要とされていましたが、その後の研究で効率的な学習手法が開発され、わずかな時間で学習が完了する成果も報告されています。このような進展により、事前学習を活用したNLP技術はますます幅広いタスクでの応用が期待されています。
BERTの活用事例
機械翻訳
BERTは高い翻訳精度を持ち、文脈に基づいた自然な翻訳が可能です。BERTを用いた機械翻訳は、従来のモデルに比べてより自然で文脈を意識した翻訳を実現します。
感情分析
BERTはテキストの意味を理解する能力があり、感情分析にも優れています。企業は顧客の感情やニーズを的確に把握し、マーケティング戦略の最適化に役立てることができます。
文章分類
BERTは文章分類にも応用されており、特にゼロショット学習のようにラベルがないデータの分類も可能です。フェイクニュース検知など文章分類の技術が重要性を増しています。
検索エンジン
BERTの導入により、検索エンジンはユーザーの複雑な意図や文脈を理解しやすくなりました。キーワードベースではなく文脈に基づいて処理するため、特に長い入力でも正確な検索結果を提供できます。Googleは2019年10月に米国の英語検索にBERTを導入し、同年12月には日本語を含む70以上の言語に展開しました。
チャットボット
文脈を理解することで、ユーザーの発言意図を正確に捉え、より自然な応答が可能です。また、BERTは多様な知識に基づいて幅広い話題に対応できるため、カスタマーサポートやオンラインショッピング、教育などさまざまな分野での活用が期待されています。
最後に
BERTはTransformerを基盤に文脈を双方向から理解する能力を持ち、多くのNLPタスクに高精度で対応できるモデルです。特にラベルのないデータを活用した学習により、データ不足の課題を克服し、検索エンジンや感情分析、機械翻訳など様々な分野での応用を可能にしました。BERTの登場により検索やチャットボットなどの技術が大きく進化し、自然言語処理の可能性が広がりました。今後も、計算リソースの効率化や複数の文脈を同時に扱えるモデルの開発が進み、BERTをベースにしたNLP技術の進化が期待されています。







