Sakana AIは、複数の大規模言語モデルを融合した新しい開発手法「進化的モデルマージ」を用いて、複数の画像について質疑応答ができる日本語の視覚言語モデル(VLM:Visual Language Model)、Llama-3-EvoVLM-JP-v2を公開しました。本モデルは、従来の手法に比べて高性能であり、日本語に対応した複数画像の質疑応答が可能です。
Llama-3-EvoVLM-JP-v2の概要
Sakana AIは、「進化的モデルマージ」という手法を提案し、大規模言語モデル(LLM)や視覚言語モデル(VLM)、画像生成モデルなどを組み合わせた新たなマージモデルを開発してきました。今回、進化的モデルマージを活用して複数の画像について質疑応答できる日本語のVLM、Llama-3-EvoVLM-JP-v2を新たに公開しました。
今回公開したLlama-3-EvoVLM-JP-v2は、複数の画像に対して日本語で質疑応答ができる高性能なVLMです。進化的モデルマージを用いて「複数の画像を扱える英語のVLM」「日本語の能力に長けたLLM」「単一画像の説明能力が高いVLM」の3つのモデルを組み合わせました。
このモデルを使うことで、複数の画像についての説明を求めたり、文章の途中に画像情報を埋め込むことができます。HuggingFace(モデル、データセット)にて公開されており、こちらからデモを試すこともできます。
進化的モデルマージとは
進化的モデルマージは、Sakana AIが提案した手法で、様々な能力を持つLLMを特殊なアルゴリズムを用いて融合し、新たなモデルを作成する手法です。
従来の勾配ベースと呼ばれる手法(勾配降下法という手法を用いてパラメータを最適化する)、多くのGPUと大量のデータが必要でした。しかし、進化的モデルマージは、特殊なアルゴリズムを用いることで比較的小規模な計算機とデータで新たな基盤モデルを作成することができ、コストやリソースを大幅に削減できます。
進化的モデルマージは、特定のタスクに特化したモデルを迅速に構築することが可能であり、新しい能力を持つモデルの開発に寄与します。例えば、日本語能力と数学能力を兼ね備えたモデルや、高速な画像生成能力を持つ日本語対応モデルのように、異なる特性を持つモデルを融合して、新しい価値を提供します。
Llama-3-EvoVLM-JP-v2で出来ること
Llama-3-EvoVLM-JP-v2は、複数の画像に対して日本語で質疑応答ができる高性能なVLMです。このモデルは、進化的モデルマージを用いて「複数の画像を扱える英語のVLM」「日本語の能力に長けたLLM」「単一画像の説明能力が高いVLM」の3つのモデルを組み合わせました。これにより、複数の画像についての説明を求めたり、文章の途中に画像情報を埋め込むことが可能です。
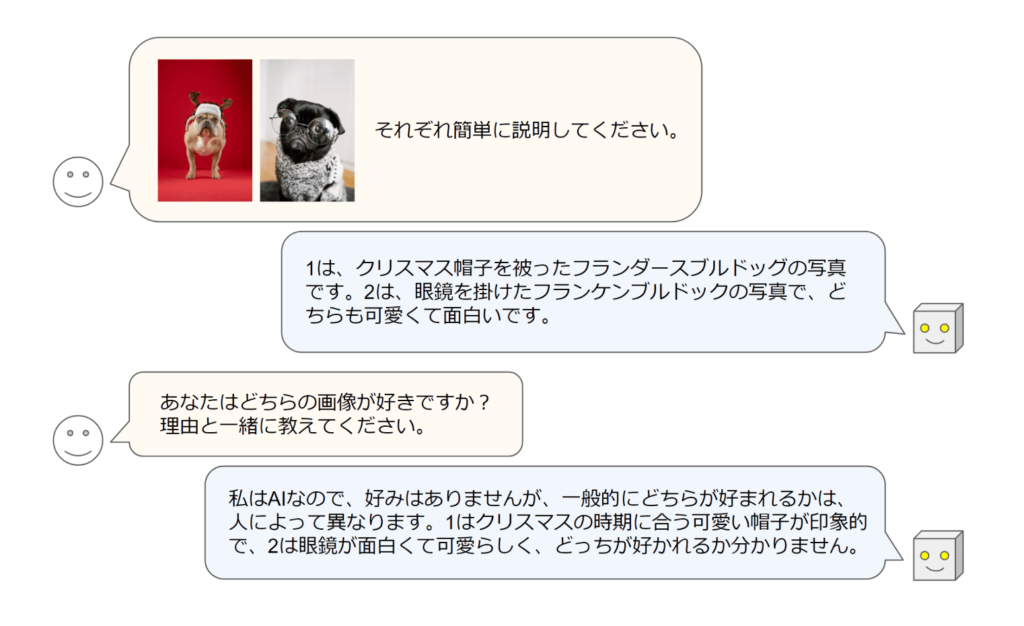
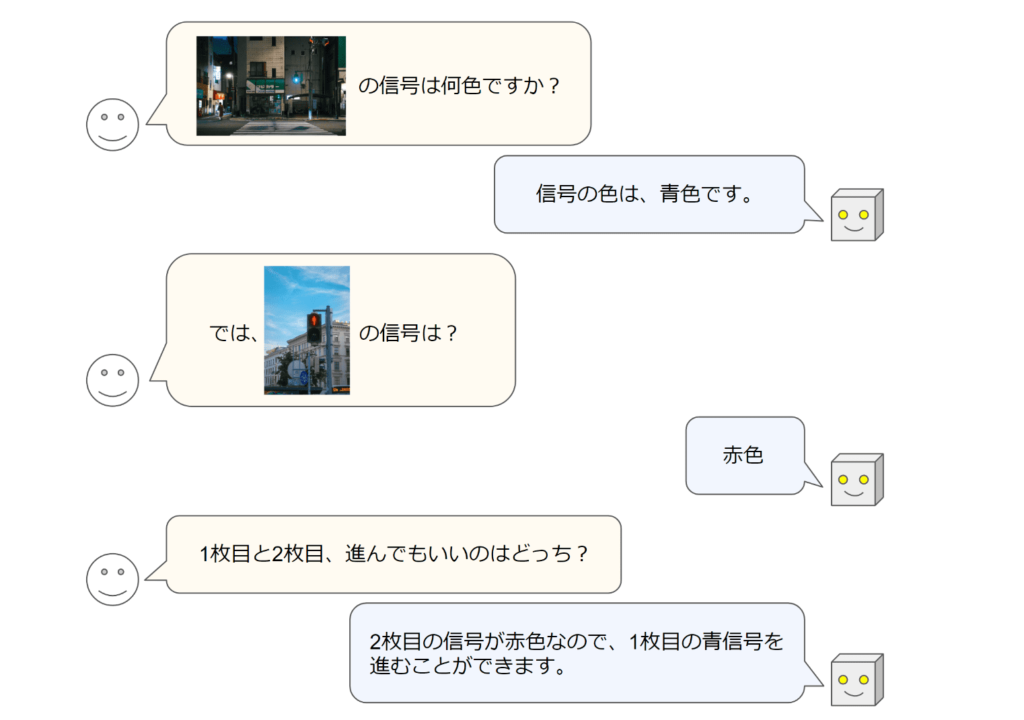
複数の画像を扱える日本語視覚言語モデルは、これまでほとんど存在せず、日本語での画像情報処理において画期的な進歩となります。日本語での質疑応答能力が向上することで、教育や情報検索、エンターテイメント分野などでの応用が期待されます。
Llama-3-EvoVLM-JP-v2の評価
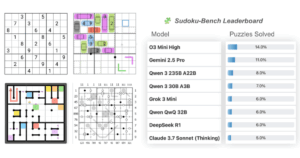
Llama-3-EvoVLM-JP-v2の複数画像に対する日本語での質疑応答能力を評価するために、JA-Multi-Image-VQAと呼ばれる新たなデータセットを使用しています。
モデルマージに使用したMantis-8B-SigLIPと比較すると(もともと日本語に対応していない)Llama-3-EvoVLM-JP-v2のスコアが大きく向上していることがわかります。一方で、GPT-4oと比較すると、Llama-3-EvoVLM-JP-v2は依然として性能差がありますが、これはLlama-3-EvoVLM-JP-v2のモデルサイズが8Bパラメータの比較的小規模なモデルであることが大きな要因です。

進化的モデルマージを使用して、低コストですぐにプロトタイプモデルを構築できる手法であることを示しました。これは日々発展が著しい分野において、研究や開発を加速できる価値の高い手法です。将来的には、オープンソースモデルの発展により、GPT-4oなどのクローズドモデルに匹敵する日本語モデルの構築が可能になると期待しています。
「進化的モデルマージ」について一言
モデル開発の最前線という感じでとても興味深いニュースです。OpenAIやMeta、Googleのように大規模言語モデル(汎用的なモデル)を開発する存在があり、Sakana AIのようにそれらをマージして特化型のモデルを開発する存在もいます。
これらのモデルを自由に利用できるようにするプラットフォームも存在し、それらをアプリケーションに組み込み開発者も今後出てくるでしょう。肝心なユーザーサイドの我々への影響ですが、汎用的な日常の作業はLLMで事足りるため、こうした特化型のモデルは翻訳ツールや製造業の画像認識検索などのニッチで質の求められるところに適しているのではないでしょうか。
OpenAIなどのクローズドモデルとの性能差が縮小することで、MetaやSakana AIの開発するオープンソースモデルが台頭するという記載もありましたが、OpenAIのアクセルの踏み方がエゲツなくかなりの認知が取れてしまっているのと、そもそも既にマルチモーダルに高性能である点を踏まえると難しい気もします。ここは意見が分かれるところでしょう。