
Mistral AIが新たに公開した「Mistral OCR」は、複雑な文書の理解においてこれまでの常識を塗り替えるほどの精度と処理速度を実現しました。単なる文字認識にとどまらず、図解、図表、数式、多言語を認識することができます。文書の内容を「構造的に」理解する能力は、さまざまな業界でデジタル変革を加速させる可能性を秘めています。

Mistral OCRとは
世界中の組織が抱える文書データの約90%が活用されずに眠っているという現状があります。これらのデータを活用できるようにすることで、企業や機関は膨大な知識資源を意思決定やサービス向上に直接役立てることが可能になります。
Mistral OCRは、文書から単純なテキストを読み取る従来のOCR技術を大きく超え、画像、表、数式、さらに複雑なレイアウトやLaTeXなどの高度なフォーマットにも対応した次世代型のOCRモデルです。画像やPDFなどの多様な形式のファイルから、情報を正確かつ構造化された形式(マークダウンやJSON)で抽出します。
また、Mistral OCRは、APIとして提供されているため、開発者や組織が簡単に自社のシステムに組み込むことが可能です。画像またはPDFファイルをAPI経由で送信すると、構造化されたテキストや画像データとして即座に結果を受け取ることができます。Mistralのチャットツール「Le Chat」を通じて試用することもできます。
Mistral OCRの具体的な使用例
Mistral OCRはすでに多様な場面でその効果を発揮しています。特に、図解や数式を多く含む科学研究論文のデジタル化においては、文書に挿入された複雑なグラフや画像を正確に認識し、意味のある情報として抽出できることから、高度な研究活動を支える基盤技術となっています。
また、カスタマーサポートの領域でも活用が広がっています。例えば、製品の取扱説明書に記載された図解や技術仕様書に含まれる数式を正確に読み取り、それをFAQやマニュアルに自動的に変換することで、顧客対応のスピードと質を劇的に向上させることができます。


多言語対応の性能も非常に高く、特にヒンディー語を含む非ラテン文字系言語の認識精度が従来の技術より格段に優れている点も特徴です。これにより、多言語で構成された文書を正確にデジタル化でき、グローバルな企業や地域に密着した事業でも活用の幅が広がっています。

Mistral OCRのベンチマーク
Mistral OCRは、ベンチマークテストでGoogle Document AIやAzure OCR、Gemini、GPT-4oなど業界トップのモデルを凌駕する高い性能を発揮しています。特に、数学的表現や表形式データの認識精度で圧倒的な差を示しており、科学や金融などの専門分野での活用が期待されています。
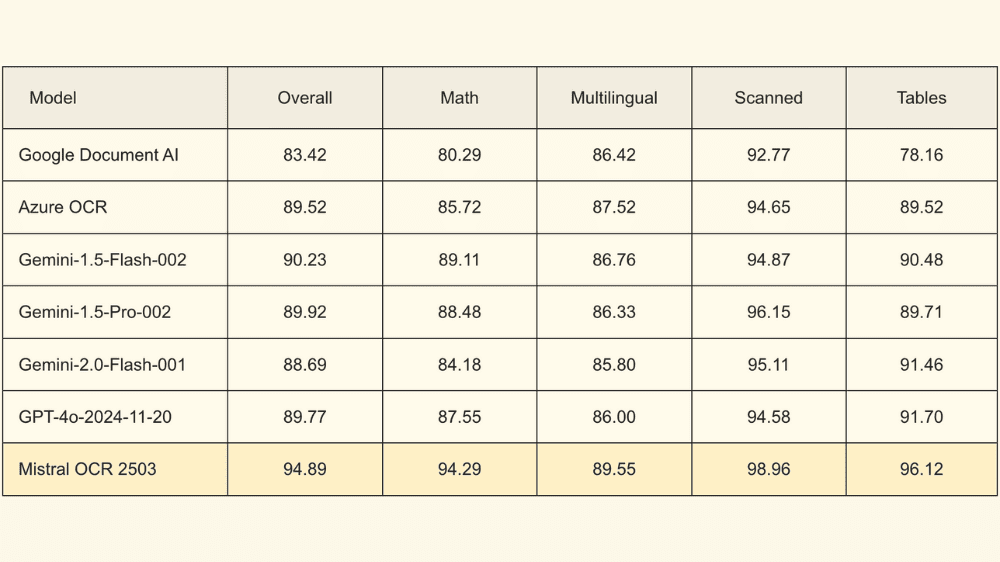
また、処理速度が毎分2000ページと非常に高速であるため、大量の文書処理が必要な大規模な企業や研究機関での導入メリットが大きくなっています。さらに、データの安全性やプライバシーを重視する組織向けに、オンプレミスでの展開も可能となっており、組織ごとのニーズに応じた柔軟な運用が可能です。
「Mistral OCR」について一言
ChatGPT、GeminiにPDFファイルを読み込ませて文字起こしや要約をさせることはよくありますが、そもそもそうしたAIモデルの仕組みとしては、裏側に画像認識、音声認識といった異なるモダリティに特化したモデルが存在しており、目的によって使い分けています。Mistral OCRはその中でも画像認識に特化したモデルとなります。
特に企業内に蓄積した内部情報はPDF形式で保存されているケースも多いのですが、今回のOCRを用いることでより幅広い種類のPDFファイルを読み込むことができます。OpenAI、GoogleのOCRよりも高性能ということで、Mistral OCRは内部情報検索用に用いる画像認識モデルとしてはとても有望かと思います。
出所:Introducing the world’s best document understanding API.