Metaが提供するオープンソースモデルであるLlamaの最新モデル「Llama 3.3」をリリースしました。70Bのパラメーターを持つこのモデルは、同サイズの旧モデルと比較して高い性能を示し、またフラッグシップの大型モデルであるLlama 3.1 405Bと比較しても劣らない推論性能とコスト効率を示しています。

Llama 3.3 とは
Llama 3.3 は、Metaが開発した多言語対応の大規模言語モデル(LLM)です。パラメータ数は70B(700億)に及び、テキストの入力・出力専用で設計されています。トレーニングには、15兆トークン以上の公開オンラインデータが使用され、最新の知識を2023年12月までカバーしています。英語、ドイツ語、フランス語、スペイン語、ヒンディー語など、広い範囲の言語をサポート。これにより、多国経済や多様な言語ユーザーに適したモデルとなっています。入力トークンの処理コストが$0.1と非常に低価格で、業界最安水準です。
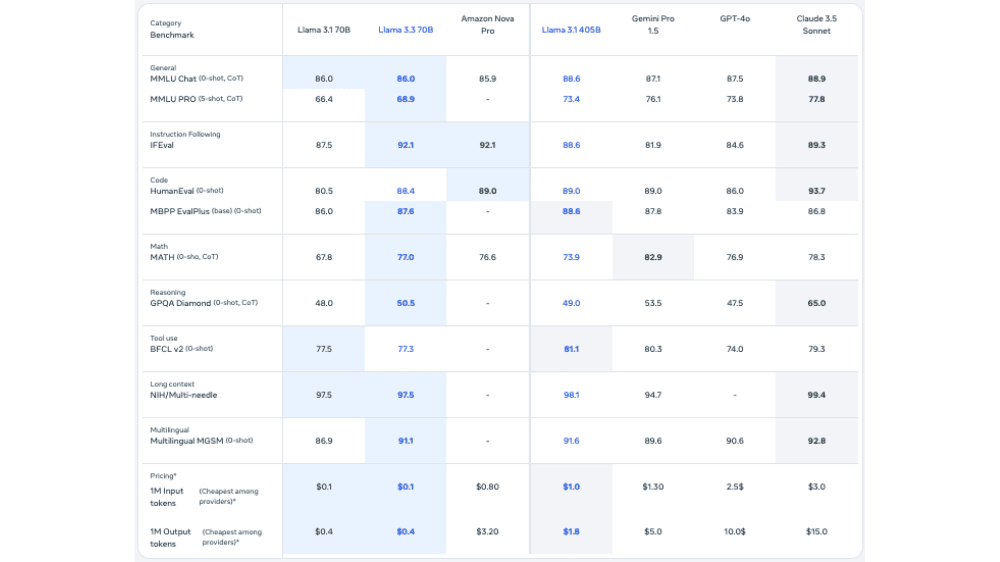
パフォーマンスについても言及していきます。表の左3つのモデルは先日リリースされたAmazon Nova Proを含む同サイズのモデルです。これらを比較すると多くの項目でLlama 3.3が高いパフォーマンスを示しています(青色背景)。特に旧モデルLlama 3.1と比較するとMATH(数学)、IFEval(指示遵守能力)が向上しており、より賢く、より安全になっていることがわかります。
また、右側にはより大型サイズのモデルの評価結果が載っています。多くの評価項目で大型サイズのモデルと同程度のパフォーマンスを示しており、IFEval(指示遵守能力)が最高値であることから、やはり人間にとってコントローラブルなモデルであると言えます。さらに、Llama 3.3 70Bは350Bと比較して小型なので、コスト効率という観点でも優位性があります。
「Llama 3.3」について一言
OpenAIが連日派手なリリースを打つ中、Llamaはひっそりと最新モデルをリリースしました。上述の通り、大型でないにもかかわらず大型クラスのパフォーマンスと指示遵守能力を備えた優秀なモデルではありますが、破壊的なレベルかと言われるとそうではないかもしれません(結果としてのこの地味なリリースなのかもしれません)。
いずれにせよ、LlamaはオープンソースのモデルでありPerplexityのように再活用してサービス展開する企業も多く存在するので、より性能の出るモデルが発表されることを引き続き期待しています。