
東京大学松尾・岩澤研究室が、経済産業省とNEDOの支援を受けて開発した大規模言語モデル「Tanuki-8×8B」を公開しました。日本でフルスクラッチから開発されたこのモデルは、対話と作文能力においてGPT-3.5 Turboに匹敵する性能を達成しています。

開発の背景
「Tanuki-8×8B」の開発は、2023年8月に公開された100億パラメータのLLM「Weblab-10B」の成功を受け、さらなる日本国内の生成AI基盤の強化を目指して開始されました。このプロジェクトは、東京大学の松尾・岩澤研究室が主導し、経産省およびNEDOが推進する「GENIAC(Generative AI Accelerator Challenge)」プロジェクトの一環として行われました。
このモデルの開発プロジェクトは2つのフェーズに分かれており、Phase1では7つのチームがそれぞれ開発を行い、性能を競いました。Phase1で最優秀チームとして選ばれたチームが、Phase2で「Tanuki-8×8B」の最終開発に取り組みました。この競争的なプロセスによって、各チームの知見や技術が結集され、最終的に「Tanuki-8×8B」が完成しました。
「Tanuki-8×8B」の概要
「Tanuki-8×8B」はPhase1で構築された8Bモデル(80億パラメーター)を8つに複製し、それぞれを専門家モデルとして分化・連携させることで効率的に追加学習されたモデルです。本モデルはフルスクラッチで開発され、作文と会話を評価する指標である「Japanese MT-Bench」において、OpenAIの「GPT-3.5 Turbo」と同等以上の性能を達成しています。
モデル名は、「日本らしく、親しみを覚える動物の名前」というテーマでチームメンバーが案を出し、最終的に「Tanuki」に決定されました。
開発モデルはApache License 2.0のライセンスに基づき、研究および商業目的で自由に利用できます。また、軽量版の「Tanuki-8B」をチャット形式で利用できるデモも公開されており、以下のURLからアクセス可能です。
開発モデル公開URL: Tanuki-8×8B
軽量版デモ公開URL:Tanuki-8Bデモ
「Tanuki-8×8B」の特徴
「Tanuki-8×8B」は文章の作文や対話を中心に学習しており、その能力を測る「Japanese MT-Bench」において、GPT-3.5 Turboと同等の性能を達成しています。さらに、「Nejumi LLMリーダーボード3(日本語能力を総合的に評価するための最新のベンチマークシステム)」を用いたベンチマークでも、総合スコア0.57/1.00を記録し、GPT-3.5 Turbo(0.58/1.00)と同程度の性能を示しました。ただし、推論性能においてはGPT-4oやClaude-3.5-sonnetといった最先端の海外モデルには及ばない部分もあり、今後の課題としています。
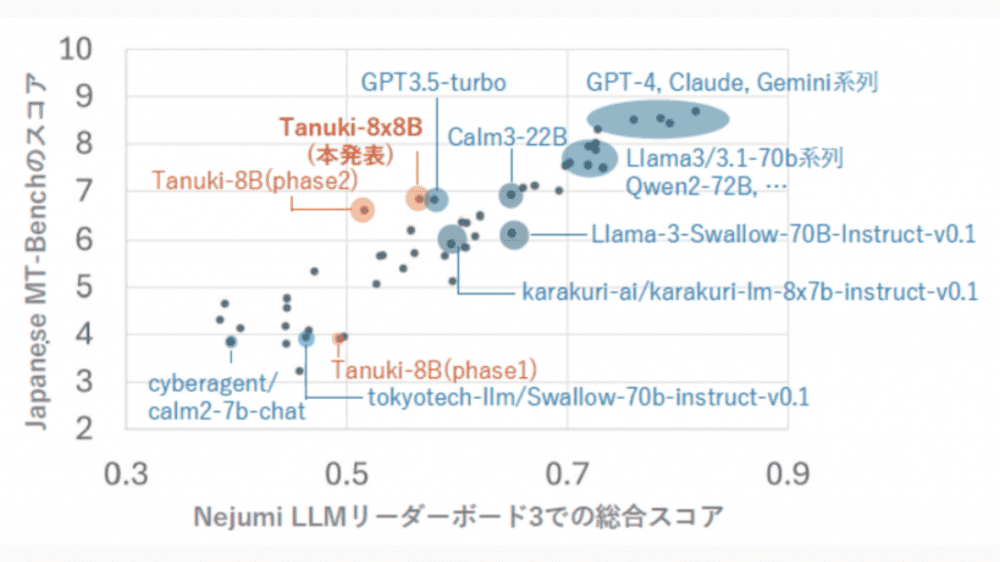
一方で、海外モデルと比較して、特に共感性や自然な言葉遣いでの対話能力に優れている点が明らかになっています。

「Tanuki-8×8B」について一言
国内での商業的な大規模言語モデル開発としては、NTTの「Tsuzami」やElyzaの「Elyza」がありますが、松尾・岩澤研究室の発表の意義は、学生を主体とした組織によってフルスクラッチでモデル構築を行い、その性能がGPT-3.5 Turboに匹敵する点にあります。
松尾・岩澤研究室は、人工知能技術の研究開発、人材育成、社会実装を通じて社会に変革をもたらすことを使命としており、学生の教育に留まらず、社会人への無償講座の提供を通じて、AI分野の裾野を広げることに尽力しています。こうした開発事例が、その取り組みをさらに後押しすることでしょう。
出所:東京大学松尾・岩澤研究室 GENIACプロジェクトにおいて、大規模言語モデル「Tanuki-8×8B」を開発・公開







