
従来のロボット制御では家庭環境での多様な物体操作や複雑な協調作業に課題を抱えていました。Figure AIはHelixを開発し、「ゆっくりと環境を理解する」、「素早く反応する」というタイムスケールの異なるシステムを併用することで、視覚、言語、そして行動を統合した新たなアプローチを実現しました。抽象的な指示を実行できたり、2体のヒューマノイド間で共同作業ができたりと、ヒューマノイドの可能性を提示しています。

Figure AIとは
Figure AIは、AI搭載の人型ロボットを開発する米国のスタートアップ企業です。2022年に設立されて以来、同社は独自の先進技術でロボット市場に革新を起こしており、主力製品「Figure 01」を中心に展開しています。Figure AIは、OpenAIとの提携を通じてChatGPTを搭載し、高度な言語理解能力を実現しています。また、テキスト、画像、音声を統合的に処理するマルチモーダルAI技術を用いることで、環境を正確に把握できる仕組みを構築しています。
事業展開においては、BMWとの提携など、産業用途を含む幅広い分野での導入が進んでおり、2024年2月には大規模な資金調達に成功、さらに2025年2月には新たな資金調達が協議されるなど、企業価値が急速に高まっています。
Helixとは
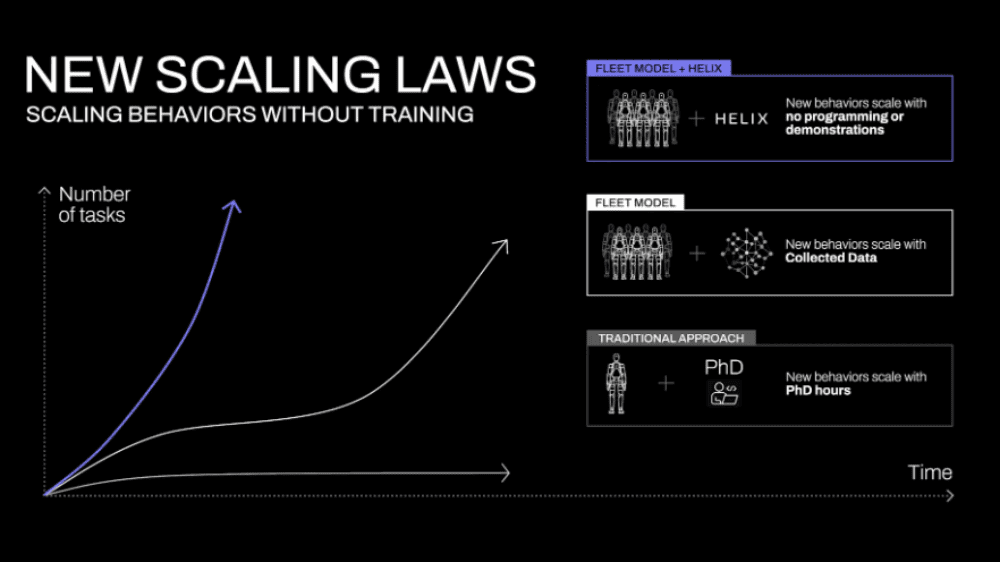
家庭環境は、ガラス製品、衣服、散らばったおもちゃなど予測不可能な形状や質感の物体があふれており、従来のロボット工学ではこうした多様な物体に柔軟に対応することが大きな課題でした。Helixは、そのような課題を解決するために開発された「視覚・言語・行動(VLA)モデル」です。従来は、各タスクごとに膨大なデモンストレーションや専門家による手動プログラミングが必要とされていた点を、Helixは自然言語の指示一つで未知の物体やシチュエーションに即応する動作を生成できるという画期的な手法へと転換しました。
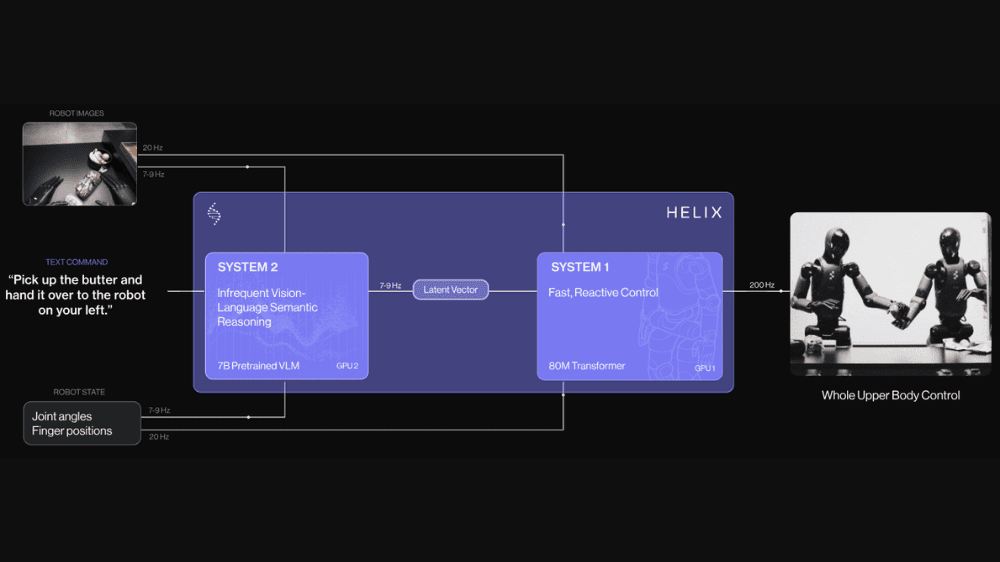
Helixのアーキテクチャは、効率的かつ安定した動作制御を実現するために、2つの補完的なシステムで構成されています。システム2(S2)は、シーン理解と言語処理を担当し、7~9Hzという低速で動作しながらインターネット規模のデータを活用して周囲の環境や自然言語の指示を広範かつ正確に把握します。一方、システム1(S1)は、S2から抽出された高レベルな意味表現を受け取り、200Hzの高速制御ループで正確な連続モーター動作に変換します。S1は80Mパラメータのトランスフォーマーモデルをベースとした視覚運動ポリシーであり、ロボットがリアルタイムに細かな動作調整を行うための重要な役割を果たしています。このように、S2が「ゆっくりと環境を理解し」、S1が「素早く反応する」ことで、それぞれの最適なタイムスケールで協調動作を実現しています。
Helixは、従来のロボット制御の限界を打破するために、いくつかの革新的な技術を実現しています。まず、ヒューマノイドの手首、胴体、頭、そして各指に至るまで、上半身全体の細かな動作を200Hzという高い周波数で連続制御することで、従来困難とされていた高次元の動作空間の精密な制御を可能にしました。また、Helixは同一のモデル重みを活用することで、2台のロボットが互いに連携し、未知のアイテムを扱う協調動作を実現しています。実際のシナリオでは、食料品の保管作業などにおいて、双方が自然言語の指示に基づいて柔軟に連携する様子が確認されています。さらに、Helixは「Pick up the desert item」といった抽象的な指示を受けた際にも、インターネット規模の言語知識を活用して対象物を正確に認識し、最適なモーター制御へと変換するため、従来数百回のデモンストレーションが必要であった新たなスキル習得を瞬時に実現しています。加えて、タスク固有の微調整や専用アクションヘッドを必要とせず、単一のニューラルネットワークウェイトで多様な動作を統一的に制御できる点も大きな特徴です。
「Helix」について一言
変わり種ですが、ヒューマノイドロボットに関してです。見るからに近未来感を感じますが、ヒューマノイドの技術革新も生成AIの発展によるものが大きいです。人間の動きは体内での情報伝達の結果です。ヒューマノイドもカメラから取得した画像情報を理解し、計画、指示、実行へとタスクを実行していきますが、生成AIにより視覚情報、コンピューター言語、機械言語の伝達効率が向上したことが技術革新に影響を与えています。
興味深いのは、「ゆっくりと考える」「素早く動く」という役割の異なるシステムを併用していることです。人間もHelixのように異なる質・速度のシステムが最適化されてできているとは思いますが、ヒューマノイドの演繹的な構築を経て、人間の機能が帰納的に証明されているようで知的好奇心的な意味で面白いなと感じます。
出所:Helix: A Vision-Language-Action Model for Generalist Humanoid Control







