
マルチモーダルAIとは、テキストや画像、音声、動画など、異なる種類のデータを統合的に処理する人工知能技術です。人間が情報を認識する際、言葉だけでなく、表情や声のトーン、ジェスチャーなどを総合的に理解するように、AIも複数のデータを組み合わせることで、より正確な判断を行えます。
マルチモーダルAIは生成AIの発展とともに進化を続けています。OpenAIのGPT-4oのように、テキストや画像、音声を統合的に処理するモデルが登場し、より高度な推論や応用が可能になったことにより、自然な対話、精度の高い異常検知、より直感的なインターフェースの実現が進んでいます。
また、マルチモーダルAIは、産業や医療、防犯、自動運転など幅広い分野で活用されています。画像や音声、センサーデータを組み合わせることで、人間に近い理解力を持つAIが実現しつつあります。

マルチモーダルAIとは
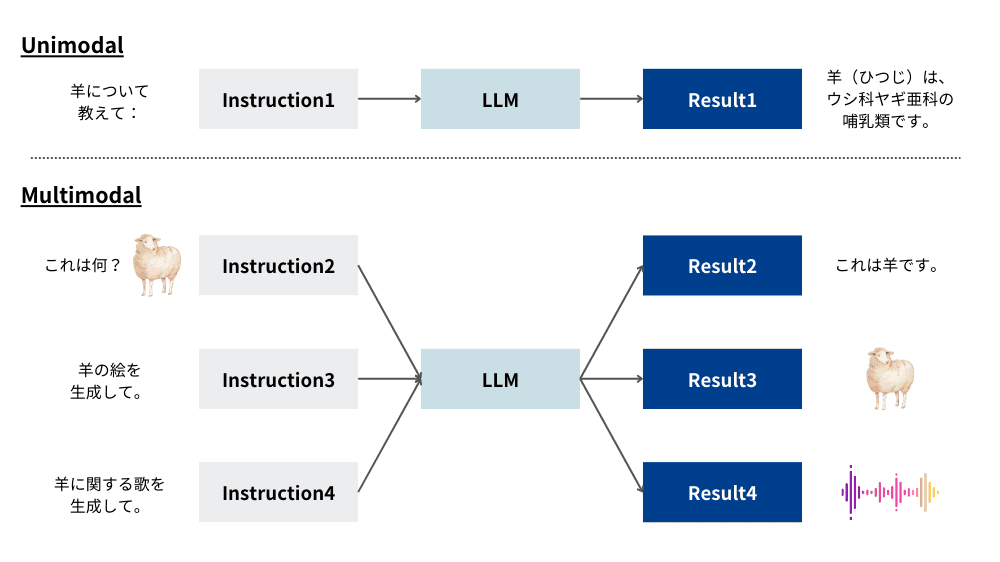
マルチモーダルAIは、異なる種類のデータ(モダリティ)を同時に処理し、統合的な理解や分析を行う人工知能技術です。人間が会話をする際、言語だけでなく、声のトーンや表情、身振りなどを総合的に理解するように、AIもテキスト、音声、画像、動画など複数の情報源を組み合わせて処理することで、より精度の高い判断や分析が可能になります。
マルチモーダルAIの進化
OpenAIが2022年にChatGPTを発表したことで生成AIは広く注目を集めました。当初はテキストのみを処理するシングルモーダルAIでしたが、その後、DALL-EなどのマルチモーダルAIが登場しました。現在ではGPT-4oのようにテキスト、音声、画像を統合的に扱うモデルも開発されています。
マルチモーダルAIはデータの統合処理により、より正確で包括的な分析を可能にします。異なる情報を統合することでコンテキストをより深く把握し、曖昧さを減らせるのも特徴です。さらに、ノイズや欠損データにも強く、一部の情報が欠けていても、ほかのデータを活用して適切な判断を下せます。
現在でも主流のAIはテキストや音声など単一のデータ形式に特化したシングルモーダルAIですが、特定のデータタイプに最適化されているため、高い精度を発揮できますが、適用範囲が限定されるという課題があります。
そこで自然言語処理と画像認識を統合するマルチモーダルAIが開発され、生成AIへの搭載が進んでいます。異なるモーダルを組み合わせることで、より高度な判断や推論が可能になりますが、扱う情報が増えることで、どのデータを基に判断しているのかが不透明になるという問題もあります。このため、AIの判断根拠を可視化し、信頼性を向上させるExplainable AI(説明可能なAI、XAI)が重要視されています。
| 項目 | シングルモーダルAI | マルチモーダルAI |
| 情報入力 | テキスト、音声、画像など単一のモーダルのみを使用 | テキスト、音声、画像など複数のモーダルを統合 |
| 応用分野 | 単一のモーダルに特化した処理を行うため、応用範囲が限られる | 異なるモーダルを組み合わせ、幅広い応用が可能 |
| データの相互補完 | 単一のモーダルのみを使用するため、相互補完の余地が少ない | 複数のモーダルを統合することで、より豊かな情報処理が可能 |
代表的なマルチモーダルAIモデル
- CLIP(OpenAI):画像と自然言語の関連付けに特化したモデルです。画像とテキストデータで学習し、ゼロショット学習能力が高く、画像分類や検索タスクで優れた性能を発揮します。
- LLaVA(Microsoft、UC Davis):視覚エンコーダーとVicuna言語モデルを組み合わせたモデルです。Visual Instruction Tuningで学習し、科学QAなどのタスクでGPT-4に匹敵する性能を発揮します。オープンソースで公開されています。
- Gemini(Google DeepMind):テキスト、画像、音声、動画を統合的に処理できます。長いコンテキストウィンドウを持ち、複雑な推論や多言語処理に対応しています。
- GPT-4V(OpenAI):GPT-4に視覚認識機能を追加したモデルです。高度な画像理解と文脈に基づく回答が可能で、数学的OCRや細かい物体検出にも対応しています。
- DALL·E(OpenAI):テキスト記述から画像を生成できるモデルです。創造的で多様な画像を生成でき、抽象的な指示にも対応しています。
マルチモーダルAIの特徴
AIの精度向上
マルチモーダルAIはテキスト、画像、動画、音声など、複数の種類のデータを同時に処理します。情報の量と質が向上することで、シングルモーダルAIに比べて精度が大幅に向上します。ディープラーニングによる継続的な学習を行うことで、より高い精度での判断が可能になります。
人間らしい判断ができる
マルチモーダルAIは、画像データや音声データ、センサーで感知した情報など、異なる種類のデータを並行して処理できます。この仕組みは人間が視覚や聴覚、触覚などの五感を使って認知や判断を行うプロセスと似ています。そのため、シングルモーダルAIよりも、より人間に近い判断が可能になります。
熟練した技能の獲得ができる
マルチモーダルAIは多様な情報を同時に取り込み、瞬時に処理できるため、直感的な作業を学習しやすい特徴があります。さらに、学習した動作をディープラーニングで応用し、次の動きを予測することで、熟練した技能の獲得も可能になります。
マルチモーダルAIにより実現できること
画像とテキストの組み合わせ
OpenAIのGPT-4は、画像データとテキストデータを組み合わせて処理できるマルチモーダルAIです。画像と質問文を入力すると、自動で回答を生成できます。GPT-4の発表時には、手書きのメモとテキストを基にWebサイト構築用のコードを生成するデモも公開されました。また、2022年に発表したDALL·E2は、テキストによる指示をもとに、内容に沿った画像やイラストを生成できます。
行動認識
マルチモーダルAIは、画像、音声、動作などの情報を同時に処理し、行動認識に活用されています。
従来のカメラでは異常を検知できない場合でも音声情報を組み合わせることで危険を察知できます。マルチモーダルAIを搭載した監視システムなら総合的な判断を行い、警備室のアラームを作動させるといった対応も可能です。
異常検知
工場の生産設備では振動、温度、湿度などのセンサーデータと、画像や音声データを組み合わせることで、機械の異音や摩耗、異物混入を早期に発見できます。マルチモーダルAIによる高精度な異常検知は、生産設備のメンテナンスの効率化、作業員の安全確保、製品の品質向上につながります。
自動運転
マルチモーダルAIは、自動運転技術にも活用されています。人間が運転する際は、周囲の車や人、標識、信号などを認識し、危険を予測しながら運転しています。自動運転ではカメラ、マイク、ミリ波センサー、加速度センサー、GPSなどのデータを組み合わせ、総合的な処理を行い、すでにマルチモーダルAIを搭載した自動運転車が公道を走行しています。
産業用ロボット
マルチモーダルAIを搭載した産業用ロボットも登場しています。株式会社デンソーウェーブは「2017国際ロボット展」で、ベッコフオートメーション、エクサウィザーズと共同開発したマルチモーダルAIロボットを発表しました。このロボットには全天球カメラと複数のセンサーが搭載されており、画像、角度、速度、触覚などのデータを統合的に処理できます。ロボットアームには多指ハンドが装着されており、タオルを折りたたんだり、サラダを盛り付けたりするような繊細な作業を学習し、実行できます。
参考:デンソーウェーブ、ベッコフオートメーション、エクサウィザーズ、ディープラーニングでロボットアームをリアルタイム制御する双腕型マルチモーダルAIロボットを開発
マルチモーダルAIの仕組み
人工知能の進化に伴い、基盤モデルのトレーニングやアルゴリズムの発展がマルチモーダルAIの研究に応用されています。ディープラーニングやデータサイエンスの進歩が生成AIの発展を後押しする以前から、視聴覚音声認識やマルチメディア・コンテンツの解析といった技術が発展してきました。
現在、医療や自動運転など、多様な分野でマルチモーダルAIが活用されています。医療分野では医用画像の分析に活用されており、自動運転ではコンピュータービジョンと各種センサーによるデータを統合し、精度の高い判断を実現しています。
マルチモーダルAIの特性
カーネギーメロン大学の2022年の論文では、マルチモーダルAIの特性として異質性、接続性、相互作用が挙げられています。
- 異質性:異なるモダリティごとに性質や構造、表現が異なる点を指します。
- 接続性:異なるモダリティ間で共有される補足情報を指します。
- 相互作用:異なるモダリティを組み合わせることで、新たな情報やパターンが生じることを指します。
参考:https://arxiv.org/abs/2209.03430
マルチモーダルAIでは、こうした特性を活かしながら、各モダリティーの強みを統合し、個々の限界を克服するモデルの構築が求められます。
マルチモーダルAIの課題
マルチモーダルAIの開発において、解決すべき重要な課題がいくつかあります。
- 表現:異なるモダリティのデータをどのように統一して表現するかが重要になります。画像には畳み込みニューラルネットワーク(CNN)、テキストにはトランスフォーマーを用いるなど、適切な手法が求められます。
- 整合:異なるモダリティーの間でどのような関連性があるかを特定し、整合性を確保する必要があります。動画と音声の時間的整合や画像とテキストの空間的整合が挙げられます。
- 推論:複数のモダリティーの情報を組み合わせ、知識を構成するプロセスを指します。通常、複数の推論ステップを経て結論を導きます。
- 生成:クロスモーダルのデータを活用し、意味のある出力を生成することが求められます。テキストから画像を生成するDALL·Eのような技術が該当します。
- 転移:モダリティ間で知識を転移する技術が必要です。転移学習や埋め込み空間の共有を活用し、異なる種類のデータを統合的に扱います。
- 定量化:マルチモーダルAIのパフォーマンスを評価し、最適化するための手法が求められます。
マルチモーダルAIのデータ処理プロセス
マルチモーダルAIは、データの収集から最終的な出力まで、いくつかの段階を経て動作します。
- データ収集:AIの用途に応じて、必要な形式のデータを集めます。音声アシスタントであれば音声データ、画像解析であればカメラの映像データなどを組み合わせる点が特徴です。近年ではクラウドやIoTセンサーを活用し、リアルタイムでデータを収集する仕組みが整っています。
- データ前処理:収集したデータにはノイズや欠損が含まれるため、分析に適した形に整える必要があります。音声データでは背景雑音を除去し、画像データでは解像度の調整や色空間の統一を行います。前処理の精度がAIの学習結果に大きく影響します。
- 特徴抽出:前処理を終えたデータから、AIが学習に利用できる特徴を抽出します。画像ではエッジや輪郭、テキストでは単語の埋め込みなどが使用されます。
- データ融合:異なる種類のデータを統合するプロセスです。データの統合には、早期融合(各モダリティのデータを前処理後すぐに統合して1つのベクトルにまとめる方法)と後期融合(各モダリティのデータを個別に処理して結果を統合する方法)が取られます。リアルタイムの処理が求められる場合には早期融合、精度を重視する場合には後期融合が適しています。
- モデルの学習と推論:融合したデータをもとに、機械学習やディープラーニングのアルゴリズムを使ってモデルを構築し、推論を行います。近年は、大規模なデータセットと高性能なGPUを活用し、学習と推論の精度が大幅に向上しています。
- 出力:最終的に得られた結果をユーザーが活用しやすい形式で提示します。製造業の品質検査システムであれば、不良品を識別してアラートを出す仕組みが導入されます。チャットボットであれば、音声やテキストで自動応答を行うなど、用途に応じてさまざまな出力方法が採用されます。
マルチモーダルAIの活用事例
電子カルテとAIの融合
日本電気株式会社(NEC)、理化学研究所、日本医科大学は、医療分野における電子カルテとAIの融合を進め、医療ビッグデータを統合的に解析するマルチモーダルAIを開発しました。
この研究では、前立腺がんを対象として病気の早期発見や治療計画の最適化を目指し、医療費の削減や医療従事者の負担軽減が期待されています。
このAIシステムは、複数の検査データを統合的に解析し、病気の状態や経過を多角的に予測します。電子カルテのデータやがんの組織画像をマルチモーダルAIで分析した結果、手術後から再発までの期間によってAIが捉える予測因子のパターンに違いが見られました。従来の手法と比較し、再発予測の精度を約10%向上させることができました。
参考:https://jpn.nec.com/press/202306/20230613_01.html
完全自動運転の実現
自動運転スタートアップのTuring株式会社は、ハンドル不要の完全自動運転(レベル5)の実現を目指し、2029年までの開発を進めています。
自動運転の研究は世界的に活発に行われており、その中心にあるのがマルチモーダルAIです。人間が運転する際は周囲の車両や歩行者、交通標識、信号、気温やエンジン音など、さまざまな情報を統合して状況を判断し、運転を行います。このような高度な判断をAIに実装するためには、画像処理だけでなく、音声や自然言語を入力として処理できるマルチモーダルAIの技術が不可欠であり、AIの学習には、マルチモーダルAIと大規模言語モデル(LLM)の組み合わせが鍵となります。カメラを活用した画像解析だけでなく、音声や自然言語の入力を統合することで、より安全で高度な自動運転システムの開発が進められています。
参考:https://prtimes.jp/main/html/rd/p/000000024.000098132.html
対話型AIの介護モニタリング
KDDI株式会社、国立研究開発法人情報通信研究機構(NICT)、NECソリューションイノベータ株式会社は、高齢者向けの対話システムAIを活用した介護モニタリングの実証実験を実施しました。
この実証実験では、マルチモーダルAIを実装した介護モニタリング支援システム「MICSUS」を用いて、高齢者の健康状態や生活状況の変化を確認しました。
介護モニタリングとは、ケアマネージャーが高齢者の自宅を訪問し、健康状態や生活状況の変化を把握する業務です。この業務は、ケアマネージャーの業務全体の約4分の1を占める重要なプロセスですが、時間と労力がかかる課題がありました。
実証実験では、ぬいぐるみ型の専用端末とスマートフォンを活用し、対話AIシステムが高齢者の健康状態を確認しました。その結果、面談や記録業務に要する時間を約7割削減できたと報告されています。
参考:https://newsroom.kddi.com/news/detail/kddi_pr-810.html
ホームロボットへの活用
Amazonは家庭用ロボットAstroを販売しており、警備や見守り機能を重視したサービスを展開しています。機能のアップデートを重ね、マルチモーダルAIに対応しました。
Astroは、周囲の環境を認識するために複数のセンサーを搭載しています。カメラや音声認識などのデータを組み合わせ、対象物の状態を学習し、より正確な判断が可能になっています。また、部屋の対象物をカメラで捉えながら、その説明を音声で学習することで、物の種類や状態を把握できます。
ユーザーが特定の項目を確認したい場合にはAstroが学習し、異常があれば通知を行います。例えば、どのドアが玄関か、どの窓が寝室かを学習し、それらが開いているか閉まっているかを判定できます。閉まっているべきドアが開いていた場合、アラートを出すことも可能です。
参考:https://xtech.nikkei.com/atcl/nxt/column/18/00001/07673/
材料データから機能を予測
日本ゼオン株式会社、先端素材高速開発技術研究組合(ADMAT)、産業技術総合研究所(産総研)は、複数のAIを用いて複雑な材料データを処理し、高速かつ高精度でさまざまな機能を予測する技術を開発しました。このマルチモーダルAI技術は、複雑な構造を持つ材料データの解析に適用され、マテリアルズ・インフォマティクス分野で活用されています。
従来のAIでは、異なる特性を持つ複雑な材料の解析が困難でしたが、画像データや分光スペクトルなどの異なるデータを統合することで、従来の手法では適用できなかった材料系でも高精度な特性予測が可能になりました。この技術により、膨大な条件の中から適切な配合を選定し、成形加工や評価を迅速に行うことができ、材料開発のプロセスを大幅に効率化できると期待されています。
参考:https://www.zeon.co.jp/news/assets/pdf/210830.pdf
最後に
マルチモーダルAIは、異なる種類のデータを統合し、高度な分析や判断を可能にする技術です。従来のシングルモーダルAIに比べ、幅広い応用が可能になり、精度や利便性が大きく向上しています。
マルチモーダルAIは情報の相互補完によって曖昧さを減らし、より的確な判断を行える点が特徴です。テキストだけでは理解が難しい場面でも画像や音声のデータを組み合わせることで、より深いコンテキストを把握でき、ノイズやデータ欠損への耐性が強く、一部の情報が不足していても適切な判断を維持できます。一方で、複数のモダリティを扱うことで、AIがどのデータを根拠に判断を下したのかが不透明になりやすいという課題もあります。このため、Explainable AI(説明可能なAI)が重要視され、判断の根拠を可視化する研究が進められています。
今後、マルチモーダルAIはより高度な推論や応用が可能になり、生成AIの発展とともにさらなる進化が期待されています。直感的なインターフェースの実現や、人間に近い認識能力を持つAIの登場により、私たちの生活やビジネスに与える影響はますます大きくなっていくでしょう。







