
Inception Labsが開発した革新的な拡散大規模言語モデル「Mercury」が登場しました。従来型の言語モデルと比較して最大10倍の速度向上と大幅なコスト削減を実現したこの新技術は、AIの常識を覆し、今後さまざまなビジネス分野に革命をもたらす可能性を秘めています。

拡散大規模言語モデル「Mercury」とは
従来の大規模言語モデル(LLM)は、自己回帰型と呼ばれる仕組みで動作しています。このモデルでは、一つひとつの単語(トークン)を順番に生成するため、前のトークンが生成されるまで次のトークンを処理できません。そのため推論処理には時間とコストが非常にかかります。また、誤った情報や幻覚(存在しない情報)が生じても、即時修正が難しいという課題もあります。
これらの問題に対し、Mercuryが採用するのは拡散モデルという手法です。拡散モデルでは、まず粗い情報を生成し、その後に細かい情報を並列かつ段階的に付加・修正していきます。この方法により、トークンを一つずつ処理する制約を打ち破り、生成速度を飛躍的に高めることが可能となりました。具体的には、市販のGPU(NVIDIA H100)で1秒あたり1000トークン以上という、従来は専用チップでしか達成できなかったレベルの高速性を実現しています。



Mercuryファミリーの中でもコード生成に特化した「Mercury Coder」は、性能評価においても驚くべき結果を出しています。例えば、GPT-4o MiniやClaude 3.5 Haikuといった最速クラスの自己回帰型LLMを遥かに凌駕する速度と精度を示しました。さらに、Copilot Arenaなどの実際の開発環境において、開発者からもMercuryのコード生成能力が非常に高評価を受けています。Mercuryは高速でありながら高品質のコード生成が可能であることから、開発者の満足度も極めて高いです。
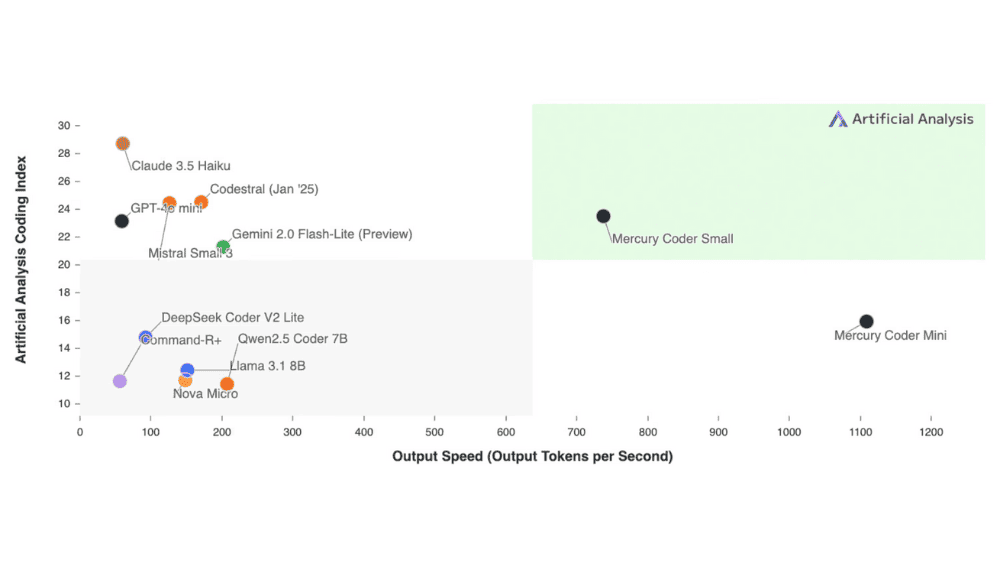
MercuryはAPIやオンプレミスでの展開が可能であり、既存のハードウェアやデータセットとも完全に互換性を持っています。そのため、企業のカスタマーサポートやコード生成をはじめ、エンタープライズオートメーション、さらにはリソースが限られたエッジデバイスへの展開にも有効です。Mercuryの高速性とエラー修正能力を生かし、リアルタイムでの高度な推論や、エージェントアプリケーションの高度化など、従来のAIでは難しかった用途にも新たな可能性を拓くことが期待されます。
「Mercury」について一言
拡散型モデルは画像生成の分野で主流となっておりましたが、Inception社はこのアプローチを言語生成の分野に応用したモデルを商用リリースしました。現在の言語生成は、言葉を前から順番に紡いでいく人間が話す時のようなスタイルですが、Mercuryでは一気に全文を出力した上で少しずつ品質を高めていくイメージです。
出力スピードが自己回帰型のモデルと比較して10倍という点は魅力的ではありますが、言語生成の分野がOpenAIやGoogle、Metaといったモデルを中心にエコシステム形成されつつあるので、若干遅いのではないかという印象もあります。今後どのような浸透の仕方をしていくのか、注目していきたいと思います。
出所:Introducing Mercury, the first commercial-scale diffusion large language model







