DeepSeekが開発した最新の大規模言語モデル「DeepSeek-R1」がリリースされました。本モデルは多言語環境での高度な推論能力を持ち、大規模データセットでトレーニングされています。いくつかのベンチマークではOpenAIの推論モデルo1と同水準を示しており注目されています。さらに、計算コストを抑えながら高い精度を維持する「蒸留モデル」も発表され、リソース制約のある環境でも利用可能です。

DeepSeek-R1とは
DeepSeek-R1は、DeepSeek AIによって開発された最新の自然言語処理(NLP)モデルであり、オープンソースとして提供されています。本モデルは、多言語環境での高度な推論能力を備え、大規模データセットを用いてトレーニングされています。これにより、テキスト生成、質問応答、コード生成、数学的推論など、幅広いタスクに対応可能です。
今回のリリースでは、DeepSeek-R1に加えて、知識蒸留(Distillation)を活用した軽量モデルも発表されました。蒸留モデルは、より小規模なアーキテクチャでありながら、計算コストを抑えつつ高い精度を維持することを目的としています。これにより、リソース制約のある環境でもDeepSeek-R1の技術を活用できる可能性が広がります。
DeepSeek-R1はこちらのチャット画面から利用可能です。また、いずれのモデルもAPI経由での利用ができます。
DeepSeek-R1の評価結果
DeepSeek-R1は、様々なベンチマークにおいて高い性能を示しています。特に、数学的推論やコード生成の分野で優れた結果を残しており、競争力のあるモデルといえます。DeepSeekの直近のモデルであるV3を超える性能であるだけでなく、OpenAIの最新モデルであるo1を超えるベンチマーク結果も出ています。例えば、数学ベンチマークであるMATH-500では、DeepSeek-R1は97.3%という非常に高い精度を達成し、OpenAIのo1-1217(96.4%)をわずかに上回る結果を示しました。コード関連のベンチマークであるCodeforcesでは96.3%と、OpenAIのo1-1217(96.6%)とほぼ同等の水準にあります。また、一般的な知識を問うMMLUでは90.8%のスコアを記録し、OpenAIのo1-miniやo1-1217と比較しても非常に競争力のある結果を示しています。
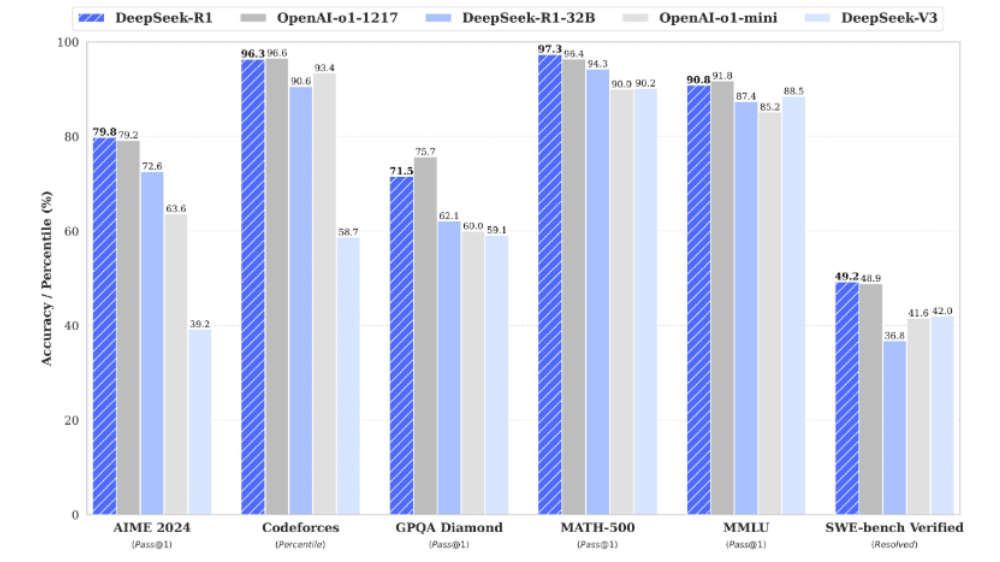
DeepSeek-R1の蒸留モデルは、より軽量ながらも高い性能を維持することを目的としています。特に、DeepSeek-R1-Distill-Qwen-32BやDeepSeek-R1-Distill-Llama-70Bのような大規模蒸留モデルは、数学的推論(MATH-500)やコード生成(CodeForces)において、OpenAIのo1-miniと同等、またはそれ以上のスコアを記録しました。このことから、大規模な計算リソースがなくても、高精度なAIモデルの活用が可能であることが示されています。また、DeepSeek-R1の蒸留モデルは、より小規模な構成のモデルでも実用性が高いことを示しています。例えば、DeepSeek-R1-Distill-Qwen-7Bや14Bモデルは、計算コストを抑えつつも、一般的なNLPタスクにおいて安定した高精度を提供しています。

「DeepSeek-R1」について一言
ここまでは読んで頂いた方向けに直近のDeepSeekの情勢について簡単にまとめをお送りしたいと思います。色々と根拠の不明確な情報もあるので、推測含みの情報としてお読みください。
まず、DeepSeekが注目されたきっかけですが、こちらは上記のDeepSeek-R1がOpenAIのo1水準のモデルであることに加え、このモデルの開発費用がOpenAIの1/10の10億円程度であることです。加えて、DeepSeekアプリ(無料)が米国のApp StoreとPlay Storeで1位となったこともその要因の一つです。
ちなみに、DeepSeekの開発費用が安価である理由は、技術的な工夫(MoEという手法を用い計算処理を減らしていること、蒸留という他社モデルのロジックを模倣することで学習を効率化していること)、ハードウェアの工夫(性能の低いGPUを代用していること)などがあると言われています。
OpenAIやGoogleといった企業のモデル開発は高価なGPUを大量に用いる力技が主流であったことから、モデル開発のデファクトに対して疑念が生じ、テクノロジー株(NVIDIAなどのハード含め)が軒並み下落することとなりましたOpenAI CEOのサム・アルトマンはこうした新興企業の台頭に対して好意的なリアクションを示していますが、そういった受け止め方だけではないのが事実です。
ネガティブサイドのリアクションとして2つの方向性があります。1つ目は米海軍が示したようにセキュリティを理由としてDeepSeekの利用を禁止する動きです。これはDeepSeekのプライバシーポリシーにおいて、ユーザーの個人情報やデータを中国のサーバーに保管する可能性が記載されていることから、広い意味では国家安全保障的な意味合いもあります。
もう一つが、OpenAIがDeepSeekの開発手法を調査するように、ビジネス上の不正疑義を明かしに行こうとする動きです。これはトレーニングデータの出所が不明であること(OpenAIのデータを盗用したと見られていて、その場合OpenAIの規約違反になる)、開発コストが異様に安価で感覚的な理解が困難であることが背景にあります。
ということでざっとDeepSeekを取り巻く事象について顕在化している情報をもとに整理してみました。技術開発の方向性を示唆する大きなトピックなので引き続きフォローしていこうと思います。