人間は重要な情報を「記憶」し、不必要なものを「忘れる」ことができます。Sakana AIはこの人間の特性を模倣した「ニューラルアテンションメモリモデル(NAMM)」という新しいメモリシステムを開発しました。これまでのLLMで課題となっていたロングコンテキスト(長くて情報量の多い会話)のやり取りにおいて精度の保持が期待されます。

ニューラルアテンションメモリモデル(NAMM)とは
Sakana AIは、トランスフォーマーモデルにおける情報の管理方法を根本的に見直すことで、AIの性能向上に大きなブレークスルーをもたらしました。「ニューラルアテンションメモリモデル(NAMM)」は、人間の記憶システムにインスパイアされ、重要な情報を選択的に保持し、不必要なデータを忘れることで効率性を高める仕組みを備えています。
従来のトランスフォーマーモデルでは、全ての入力情報を保存・処理する必要があり、長いタスクを処理する際に性能やコストの問題が発生していました。一方でNAMMは、情報の選別を可能にし、効率的な処理を実現します。この革新的なモデルは、固定的なルールではなく、ニューラルネットワークを活用して「記憶」と「忘却」の決定を行います。これにより、「長時間のタスク処理におけるメモリ使用量の削減」「情報の冗長性を排除し、重要なデータに集中」「異なるタスクやドメイン間での柔軟な適応」が可能となります。
NAMMの技術的仕組み
NAMMは、トランスフォーマーモデルの中核をなす「アテンションメカニズム」に着目し、以下の3つのステップで機能します。
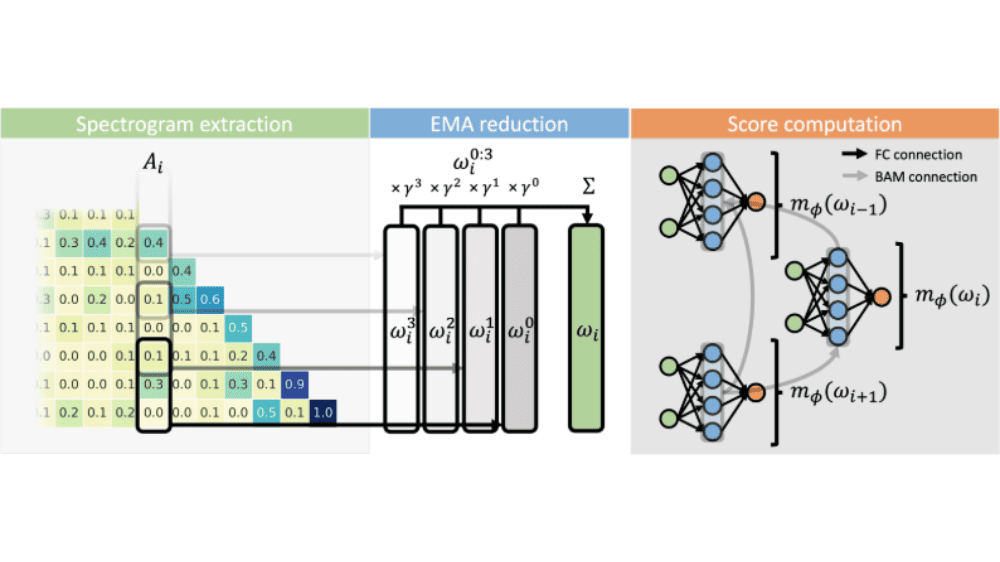
まずは「アテンションシーケンスの処理」です。トランスフォーマーモデルでは、各情報(トークン)の重要度を「アテンション値」として計算します。NAMMはこの値を「スペクトログラム」という形に変換します。音声を周波数で表現するように、情報同士の関係性を分かりやすい形で表現できるようになります。
次に「情報の圧縮」です。生成された「スペクトログラム」のデータは、「指数移動平均(EMA)」という手法で圧縮されます。これは大量の情報を効率よく保存するための重要な工程です。会議の議事録をまとめるように、データの本質を残しながら無駄を省いていきます。
最後に「重要情報の判別」です。「ニューラルネットワーク分類器」という仕組みを使って、各情報を「記憶する」か「忘れる」かを判断します。例えば、長い会話の中で重要なポイントだけを覚えておくように、タスクに応じて必要な情報を選別します。
NAMMのパフォーマンス
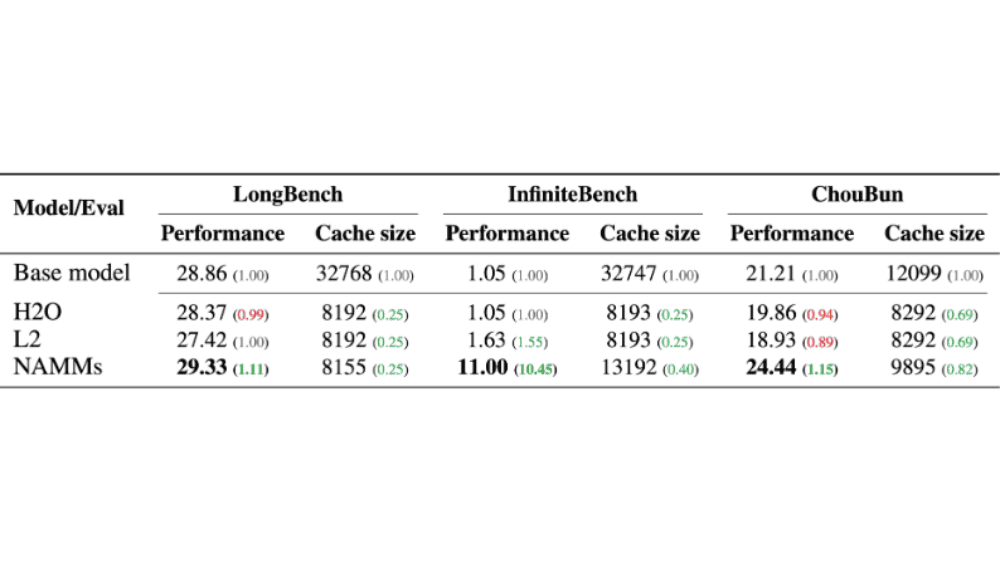
Metaの言語モデルであるLlama 3 8bをベースとしたNAMMの性能評価について、3つの重要なベンチマーク(LongBench、InfiniteBench、ChouBun)での結果が示されています。これらのベンチマークは、AIモデルが長い文章やコードを理解し処理する能力を測定するもので、計36種類のタスクが含まれています。
結果を見ると、NAMMは既存のメモリ管理手法であるH2OやL2と比較して、全体的に優れたパフォーマンスを示しています。
LongBenchでは、ベースモデルの28.86に対してNAMMは29.33とわずかに向上し、H2O(28.37)やL2(27.42)を上回っています。特に注目すべきはInfiniteBenchでの結果で、ベースモデルの1.05からNAMMは11.00と劇的な性能向上を達成しています。これはH2O(1.05)やL2(1.63)と比べても圧倒的な差となっています。ChouBunにおいても、NAMMは24.44とベースモデル(21.21)を大きく上回り、H2O(19.86)やL2(18.93)よりも優れた性能を示しています。
さらに重要な点として、キャッシュサイズ(Cache size)の観点からも効率性が確認できます。NAMMは他の手法と同程度か若干大きめのキャッシュサイズでこれらの性能向上を実現しており、特別な最適化を行うことなくメモリ効率の改善も達成しています。
NAMMは、言語モデルだけでなく、視覚や強化学習といった異なる分野にもゼロショットで適用可能です。これにより、トークンの冗長性を削減し、重要な情報に焦点を当てる能力が証明されました。
「NAMM」について一言
SakanaAIはLLM自体を開発するOpenAIやGoogleといった企業とは異なり、LLMを技術力で社会最適させる企業です。言語別や業界別での性能向上や、今回のメモリ活用方法の開発のように、LLM自体が持つ課題に対してソリューションを提供しています。そういった意味で、LLMを組み込んだアプリケーションを提供する企業群とも一線を画す独自性のある企業です。
今回のNAMMはかなり専門的ですが、起点となる課題はかなり普遍的なものです。例えばChatGPTでは、同じチャットの会話履歴を自動的に記憶しておく機能を持っています。おかげで、2回目、3回目のチャット入力の際に最初に入力した前提情報を入力する必要があります。
しかしこの会話履歴の保存機能にも容量の上限があり、チャットのボリュームが増えてくるに従い、出力の性能が低下してきます。今回のNAMMはこうした短期保存情報を「記憶」「忘却」するかを精査してくれる機能であり、文脈を保持したより会話への貢献が期待されています。
出所:An Evolved Universal Transformer Memory