12 Days of OpenAIの最終日(OpenAIの12日連続のプレスリリース)、OpenAIは次世代モデルである「o3」と「o3-mini」を発表しました。o3は数学やプログラミングなどで高い性能を発揮しつつ、自律性を備えています。また、o3-miniはコンピューティングコストを抑えつつ、優れたパフォーマンスを提供するモデルです。この2つのモデルは、性能と処理時間(コスト)をトレードオフとしており、目的や用途に応じた柔軟な使い分けが推奨されます。安全性を重視しており、研究者によるテストを実施した上で、2025年1月にo3-miniが、その後o3がリリースされる予定です。

o3の概要
OpenAIは、AI技術の限界を超える「o3」と「o3-mini」を発表しました。この新しいAIモデルは、複雑な推論が求められる課題において高い性能を発揮し、数学、プログラミング、科学などの分野で画期的な成果をもたらします。
現在、このモデルは安全性テストの一環として、研究者やセキュリティ専門家に公開されています。興味がある方は、OpenAIの公式ウェブサイトからテストプログラムに申し込むことができます。この取り組みにより、モデルの安全性や使いやすさが検証され、一般公開時に広いニーズに応えられるようになります。
o3-miniは2024年1月末の正式リリースを予定しており、その直後にo3が公開される見込みです。これらのモデルは、教育分野、研究開発、アプリケーション開発など、さまざまな用途で活用されることが期待されています。特に、これまで困難だった課題の解決や高度な問題に取り組む際の新たなパートナーとして注目されています。
o3の性能
o3の特徴は、圧倒的な性能を誇り、特に数学、科学、プログラミングにおいて、過去のモデルを大きく上回る成果を示しています。
数学・科学分野での驚異的な成果
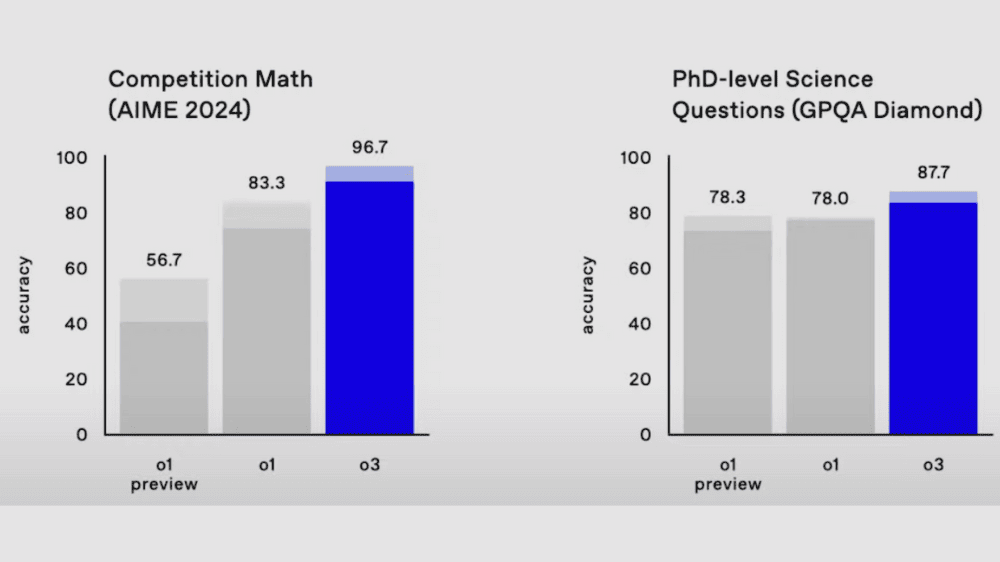
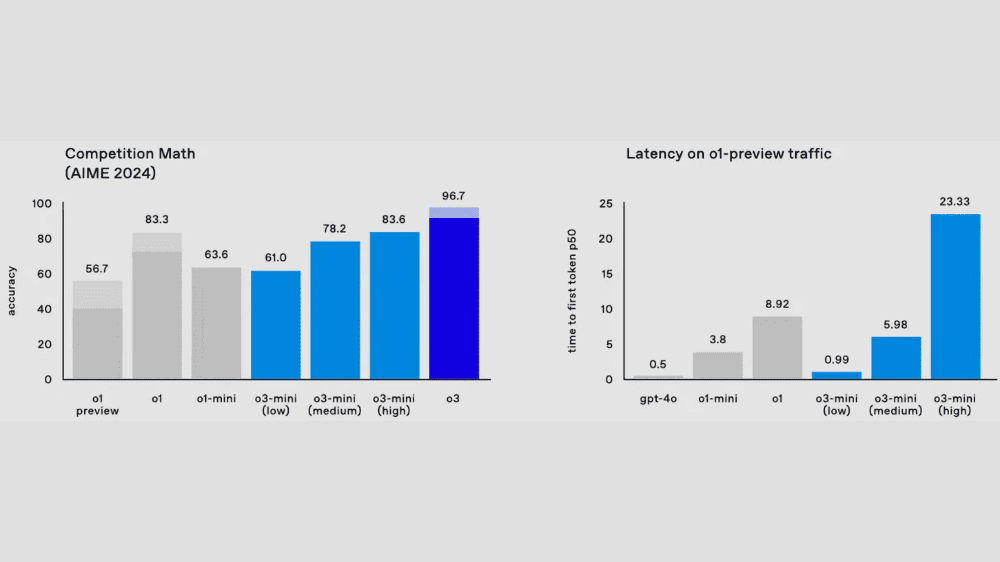
1枚目の画像左の「AIME(American Invitational Mathematics Examination)」は数学のテストでのモデル性能が示されています。このテストは、高度な数学的思考を必要とする問題が多く含まれるため、AIにとっても非常に難しい課題です。o3は96.7%の正確性を記録し、前モデルであるo1の83.3%(最高値)を大きく超えました。o3はほとんど全問正解に近いスコアを達成し、人間のトップクラスの成績を上回るレベルに達しています。
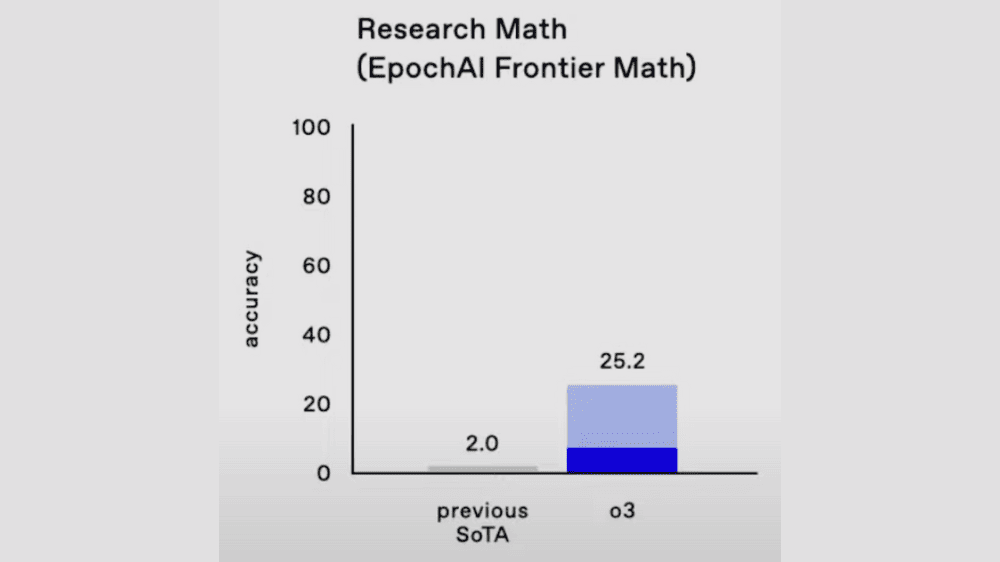
さらに、2枚目の画像の「EpochAI Frontier Math」という、数学研究者向けに設計された最難関のテストでは、o3が25.2%(前最高値2%)の正確性を記録しました。これまでのAIモデルは2%しか正解できなかったことを考えると、この結果は飛躍的な進歩を意味します。
1枚目の画像右に示される「GPQA Diamond」というベンチマークでは、博士号レベルの科学的質問に対してo3が87.7%(前最高値78%)の正確性を記録しました。これまで人間の専門家が70%程度のスコアだったことを考えると、AIが専門家を超えるパフォーマンスを発揮したことがわかります。
プログラミングでの成果
プログラミングの分野でもo3は壮大な結果を残していることを示しています。SWE-bench Verifiedという実際のソフトウェアタスクを評価するベンチマークで、o3は71.7%の正確性を達成し、従来のo1(48.9%)を大幅に上回りました。また、競技プログラミングELOスコアでは、o3が2,727という非常に高い値を記録し、世界トップクラスのプログラマーに匹敵する成果を見せています。
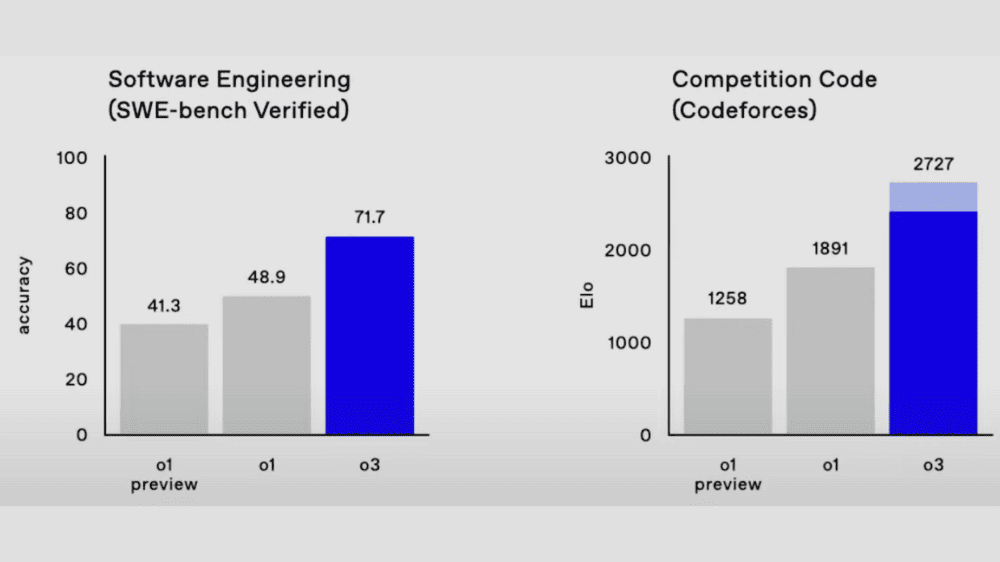
o3ファミリー(mini含む)の性能
o3シリーズには、フルスケールのo3に加えて、コストと効率に優れた「o3-mini」が含まれています。このモデルは、推論時間やコストを調整しながらも高い性能を発揮できる設計となっています。
数学でのモデル別性能
o3-miniは推論時間を3段階(low/medium/high)で調整可能です。この柔軟性により、利用者はタスクの複雑さに応じて最適な性能を選ぶことができます。low設定では、AIME 2024で61.0%の精度を記録。medium設定で78.2%、high設定では83.6%に達し、従来モデルであるo1を上回る性能を発揮しました。
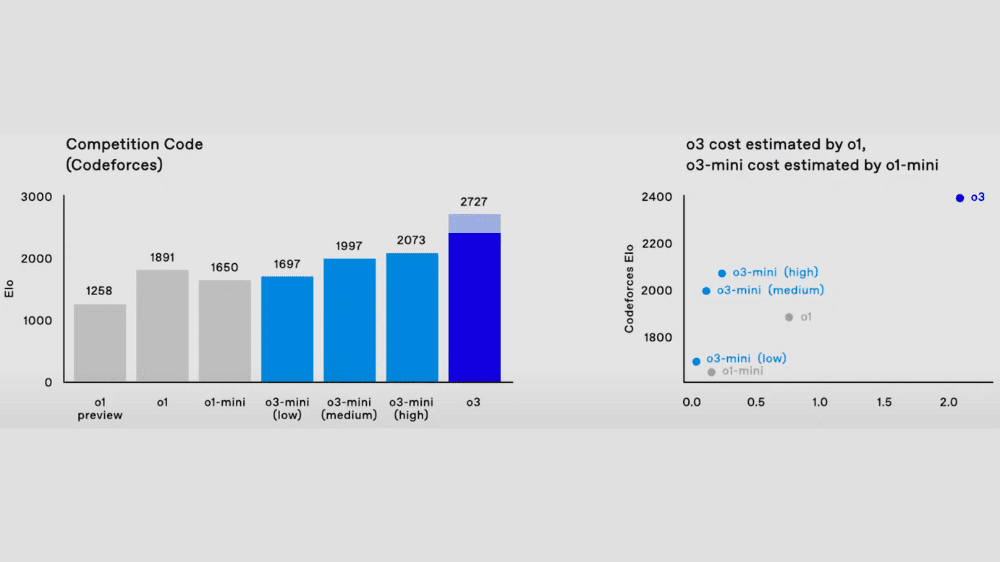
プログラミングでの性能と効率性
競技プログラミングELOスコアでは、o3-miniは最大2,073のスコアを記録し、o1の1,891を超える成果を示しました。また、コスト効率の観点では、o3-miniは従来のo1モデルやo1-miniと比較して圧倒的に優れた性能対コスト比を実現しています。
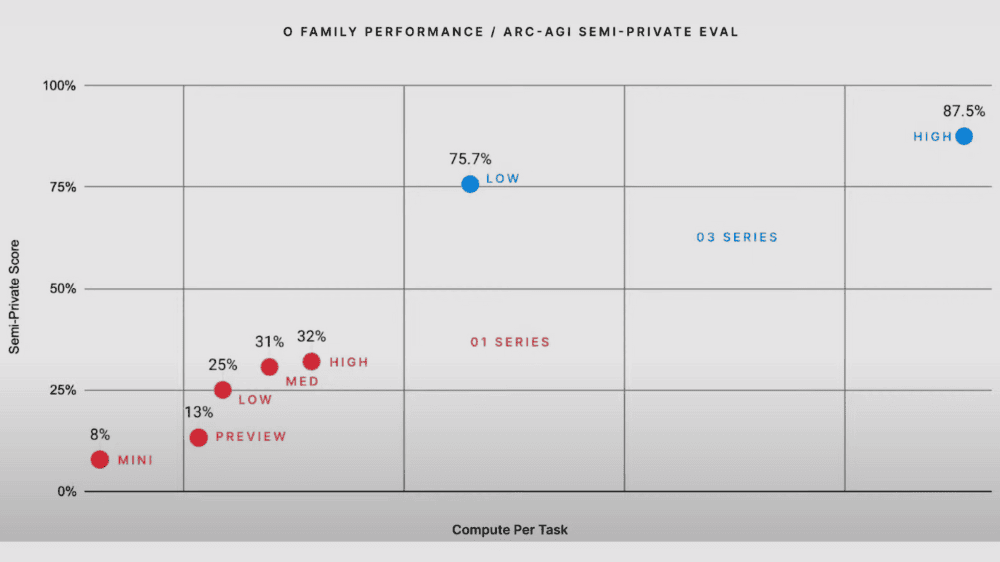
AIの自律的性能
また、モデルの自律的なタスク処理による性能評価をするARC-AGIベンチマークでは、low設定で75.7%、high設定で87.5%とo1シリーズを大きく上回るスコアを達成し、AIが人間のパフォーマンスを上回る新たな基準を作り上げました。横軸が推論回数、縦軸が性能を表しており、o3のモデルシシリーズは右上(推論回数が多く、性能も高い)に位置しています。
o3-miniの実例
o3-miniは、その柔軟性と高性能を活かして、さまざまなタスクにおいて活躍しています。以下では、その実例として2つのデモを紹介します。
1つ目は、AIがPythonを使ったプログラムの生成と実行を完全自動化するデモです。ユーザーが「特定のタスクを行うプログラムを生成して実行してください」と命令すると、AIはその指示に基づいてPythonコードを作成します。このコードはローカルサーバーを起動し、ユーザーが入力できる画面を提供します。ユーザーが「‘OpenAI’という文字とランダムな数字を表示してください」といった簡単な命令を入力すると、AIが即座にコードを生成し、実行して結果を返します。このプロセスは全て自動で行われ、プログラミング経験がないユーザーでも簡単に利用できる仕組みになっています。
2つ目は、AI自身が自分の性能を評価するためのプログラムを作成して実行するデモです。このデモでは、AIが必要なデータセットを取得し、それを解析して評価を行います。具体的には、データセット内の問題を解き、その正答率を計算して結果を報告します。非常に難しい課題に対しても、AIは迅速かつ正確に自己評価を完了させました。これにより、AIが自己検証能力を持ち、独立して性能を確認できることが示されました。
Deliberative Alignment(熟考型アラインメント)
o3シリーズでは、安全性の確保を目的として「Deliberative Alignment」という新しいアプローチが採用されています。この技術は、モデルが与えられたプロンプトを深く分析し、その中に潜む意図を正確に解釈することで、より安全な応答を可能にします。
従来のAIモデルでは、「安全」「危険」といった単純な分類を基にトレーニングされていました。しかし、o3シリーズは、モデル自身がユーザーの意図を熟考する能力を持ち、危険性のあるプロンプトや隠れた意図を見抜く仕組みを備えています。これにより、不適切なリクエストを拒否するだけでなく、より適切で安全な形に再構成して応答することが可能です。
このアプローチにより、意図的な悪用や情報漏洩を防ぐだけでなく、信頼性の高いAIの実現に大きく寄与しています。また、ユーザーは安心してモデルを利用できる環境が整い、非エンジニアでも安心して複雑なタスクを依頼できるようになります。さらに、熟考型アラインメントは、モデルが何が安全であるかを常に学び続ける仕組みを取り入れており、適応性と信頼性の向上を実現しています。
この新技術の採用により、OpenAIのo3シリーズは安全性と利便性の両立を達成し、あらゆるユーザーにとって信頼できるパートナーとして活用されることでしょう。
「OpenAIのo3発表」について一言
多くのニュースを提供してくれた12 Days of OpenAIの最終日、やはり最も注目度の高いAGIを想起させるニュースが発表されました。o3がo1と比較してさらに性能を高めたことの示唆として、「多重推論(=コンピューティング)とモデル性能に正の相関があり、すでに人間の9割方が対峙する日常の問題解決能力を凌駕していること」かと思います。意味があるかは置いておいて、推論サイクルを重ねることで、更に精度を高めることは可能なのでしょう。
翻って言えることが2点ほどあるかと思っています。1点目は、AGIやエージェントといった自律的なAIを実現するという意味においては、アプリケーションや異なるデバイス間に染み出し、情報を参照する仕組みが必要であること。今回のo3でもウェブ上の情報を取得して学習するという自律性は見られましたが、例えば国内線のチケットを予約するという単純なタスクですら現時点の枠組みでは実現できません。これはAIにとどまらないネットワークの拡張性の領域であり、この分野の開発、AIとの統合が次なる課題となることを示しています。
2点目は、AIは性能&コストのバランスで選択する時代がやってくるということです。上述の通り、多重推論により性能が上がるo3ですが、当然ながら推論回数とコンピューティングリソースのコストは正の相関があります。また、数学や科学の難問と対峙する人類は一握りであることも踏まえると、o3水準の高性能なモデルは必要ないのかもしれません。このことからも、今後は個人の向き合うタスクに応じてモデルを使い分けることが基本となる時代が来ると考えられます。
出所:OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12