
ファインチューニングとは、すでに大量のデータで訓練されたモデルを特定のタスクや目的に合わせて微調整し、精度を高める手法です。事前に汎用データで学習されたモデルは、幅広い用途に対応できる一方で、特定の業務や目的においては最適な結果を得るためには調整が必要です。ファインチューニングを行うことで、モデルの能力を最大限に引き出し、業界特有のニーズや自社の独自データを反映した高精度な予測や分析を実現します。

ファインチューニングとは
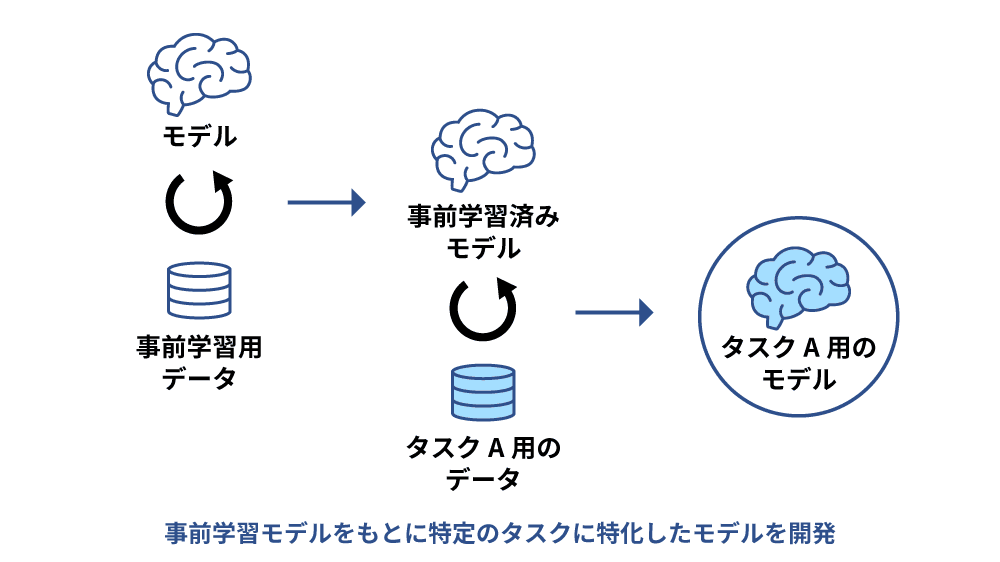
ファインチューニングとは、大量の汎用データを使って事前学習したモデルに対し、特定のタスクに適したデータを追加で学習させ、パラメータを微調整することです。事前学習済みモデルは汎用的なモデルではありますが、必ずしも特定のタスクに対して有効とは限りません。ファインチューニングを行うことで自社の業界や特定のタスクに対して精度の高い活用をすることができます。
ChatGPTを始めとする大規模言語モデル(LLM)は事前に膨大な量のデータによる学習が終わっており、インターネット上にあるデータを使って非常に高いパフォーマンスを発揮しています。しかし、そこまで高い汎用性を持つChatGPTであっても企業で特定のタスクを行う場合にはカスタマイズが必要であり、現時点でカスタマイズの方法は大きく2つです。
1つは大規模言語モデルのプロンプトに関連情報を追加して、追加情報を基に回答を生成する方法であり(RAG:検索拡張生成)、もう1つはファインチューニングによるカスタマイズです。大規模言語モデルのプロンプトに関連情報を追加する場合、入力プロンプトが増えることでレスポンスや出力速度に影響することが考えられますが、ファインチューニングでは事前にトレーニング済みのモデルを洗練させることができるため簡単で、かつ、安価に設定できるところに強みがあります。
ChatGPTを使った事例
ChatGPTは大量のインターネット文書から学習して高い会話能力を持っていますが、社内文書やドメイン固有の知識を含む会話には対応が難しい場合があります。これは、事前学習されたデータにはそのような非公開情報が含まれていないためです。この問題を解決するために、ファインチューニングが用いられます。この場合の、ChatGPTに新たな社内文書を学習させ、その内容に基づく会話能力を付与するための学習といえます。
なお、社内文書を学習に使用する際には、セキュリティ上のリスクが生じる可能性があります。特に、学習データが想定外の用途で再利用されることを防ぐため、安全なデータ取り扱いが重要です。
OpenAIおよびAzure OpenAI Serviceの規約によれば、APIから入力された情報はサービスの開発や改善に再利用されることはなく、データは暗号化され、特定の条件下でのみアクセスが許可されるとあります。さらに、ユーザーは申請を通じて、API以外から入力された情報の再利用を拒否することができ、データの保存やMicrosoft社員によるアクセスを拒否するオプションも提供されています。これにより、ファインチューニングにおけるデータの安全な取り扱いが保証されています。


ファインチューニングの仕組み
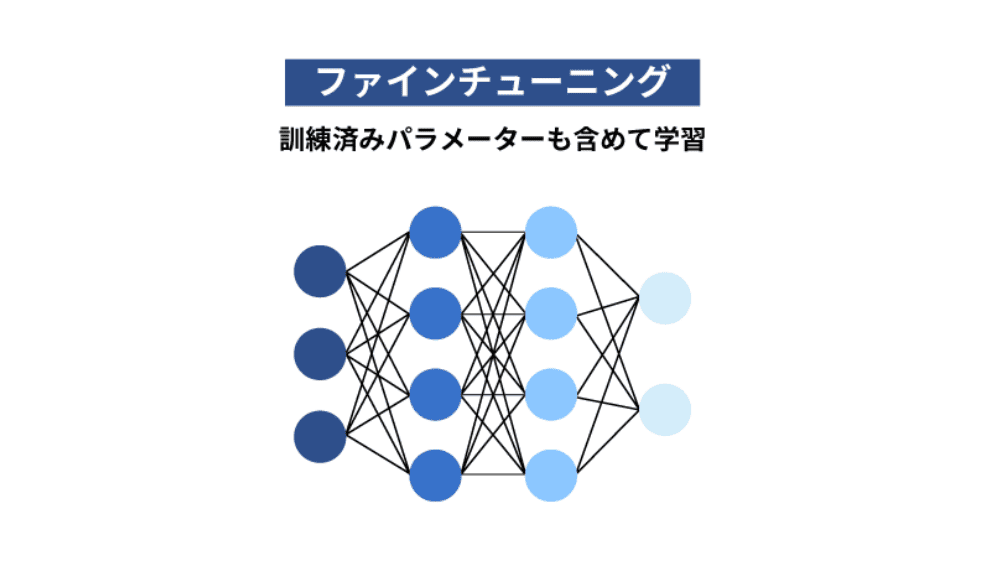
ファインチューニングでは、基盤となる事前学習済みモデルを用意し、このモデルに対して特定のタスクに関連するデータセットで再訓練をします。モデルに追加した最終層または複数の層を調整することでタスクに最適なパラメータを見つけていくことで追加したデータに対する予測能力が高まります。そのため、追加学習用のデータセットの準備は非常に重要であり、一般的には次のようなステップでデータセットを作成することになります。
目的の明確化
事前準備として、最初に解決しようとしている問題を明確に定義する必要があります。目的に応じて必要なデータの種類や特徴が変わるため、次のステップのデータ収集やデータの前処理の方向性に関わるためです。
データ収集
学習に使用するデータを収集する必要があります。データ収集に重要なことは、タスクに関連性が高く、多様性を持ち、かつ、十分な量を確保することです。データの収集は公開データの利用、WEBデータのスクレイピング(抽出)、社内データベースなどさまざまな方法があります。
データの前処理
収集したデータをモデルに適した形式に加工するステップです。不要な情報の削除、サイズの統一、トークン化(テキストデータを処理しやすい単位に分割すること)などの方法があり、前処理を行うことでデータの品質が向上し、効率的に学習することができるようになります。
なお、教師あり学習を行う場合には、モデルの学習の際に「正解」として機能させるためのラベル付け(タグやカテゴリ)を行う必要があります。
データセットの分割
用意したデータセットを訓練セット、検証セット、テストセットの3つに分割します。データセットの分割はモデルが追加されたデータに対して、どの程度うまく一般かしたかを評価する際に重要視され、一般的には訓練セットが7割〜8割、残りの2割〜3割が検証セットとテストセットになります。
データの拡張
データが不足している場合や多様なデータを学習させたい場合には、モデルの汎用性を高めるためにデータの拡張が必要です。テキストデータであれば同義語への置き換えや文章の再構築、画像データであれば回転や反転などを行うことで拡張できますが、拡張の際には元のデータセットの意味を変えないように変更する必要があります。
品質の確認
データセットの品質はファインチューニングの結果に大きく影響するため、データセットが完成した時点で品質をチェックし、必要に応じてクリーニングや再ラベリングを行うことになります。データセットの準備は手間がかかりますが、モデルの性能向上の成否にかかわる重要なポイントです。
ファインチューニングと他の学習方法との違い
転移学習との違い
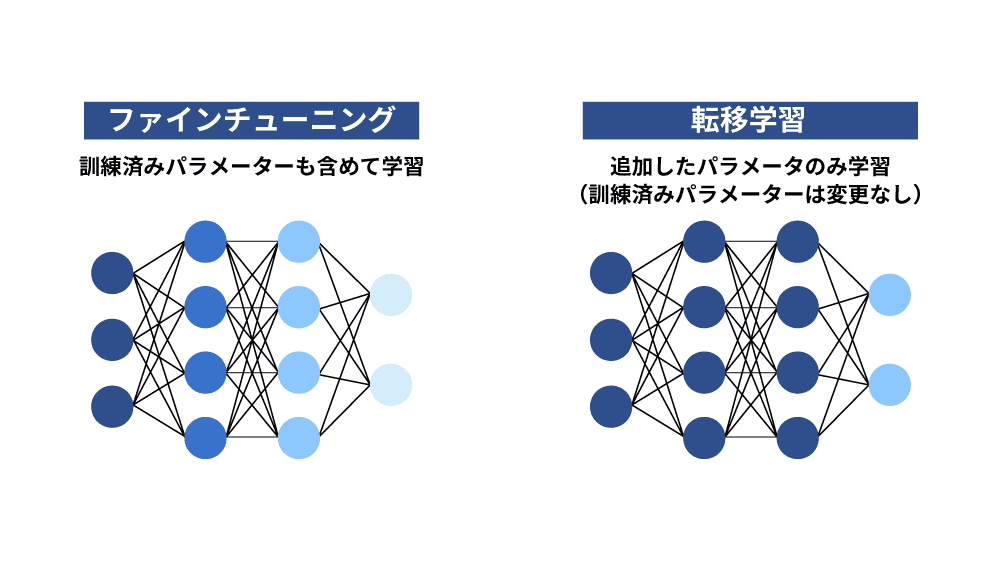
転移学習は、新たに追加した層だけを追加で学習し、その他の層の既存パラメータは調整しません。ファインチューニングでは新しいデータを追加し、モデルの一部または全体を学習するため、追加された層だけを学習するか、モデルの一部または全体を学習するかという点で異なります。
また、必要なデータ量でも異なり、データ量が豊富であればファインチューニングが適しており、データ量が少なければ転移学習が適しています。
蒸留との違い
ファインチューニングと蒸留はどちらもモデルを改善する方法ですが、蒸留では大きな学習済みモデルから重要な情報を抜き出し、小さなモデルに学ばせるという点で異なります。大きな学習済みモデルから学ぶことで高い性能を出すことができるようになり、効率と速さの向上に重きを置いている手法といえます。

プロンプトエンジニアリングとの違い
プロンプトエンジニアリングとは、プロンプト(入力データ)を工夫することで、特定のタスクに対して最適化する方法です。モデル自体の再学習や調整は行わず、質問の仕方や情報の提示方法など、入力方法をどのように構成するかを変えることで精度を上げます。データ量が豊富にあり、特定のタスクに特化させたい場合にはファインチューニングが適していますが、追加学習のリソースや時間が限られている場合にはプロンプトエンジニアリングのほうが適しています。

インストラクションチューニングとの違い
インストラクションチューニングとは、入力データを理解して、従う能力を向上させ、さまざまなタスクを実行するための汎用性を向上させることです。追加情報に対してモデルの一部または全体を学習するという点はファインチューニングと同じですが、目的に違いがあります。ファインチューニングでは特定のタスクに対する精度向上を目指しているのに対し、インストラクションチューニングでは一般的なタスク全般に対する指示の精度向上が目的となっています。インストラクションチューニングを行うことでユーザーの意図に沿った回答を生成することができるようになります。
ファインチューニングとRAGの違い
RAG(Retrieval-Augmented Generation)は、情報検索と生成を組み合わせた手法であり、言語モデルはそのままに大規模な文書データベースから関連する情報を検索し、回答を生成するように設計されています。ファインチューニングではモデルを再学習させますが、RAGでは既存のモデルを前提に検索機能を付与させている点に違いがあります。

ファインチューニングのメリット
ファインチューニングを利用する最大のメリットは社内業務やサービスに特化した独自環境を構築できることです。社内データを用いることで既存のモデルの能力を受け継ぎながら社内データを活用することができます。
回答精度が向上する
ファインチューニングを行うことでAIモデルがアップデートされるため、自社の業界や特定のタスクに対して高い精度の回答を得られるようになります。既存モデルの持っている能力を活かしながら、理想に近い回答をする能力を向上させることが可能です。
十分なデータがなくても運用できる
ファインチューニングは、既存モデルに対して限られたデータでの再訓練をすることで高い精度の予測をすることができるようになります。既存モデルの知識を転用できるため、膨大なデータを用意する必要がなく、限られたリソースを活かして、高い品質のアウトプットを引き出せます。
開発コストやリソースを削減できる
ファインチューニングは既に訓練されたモデルを利用することができるため、ゼロからモデルを開発する必要がありません。そのため、モデル開発に掛かる膨大な時間とコストを削減することができます。既存モデルの能力を転用できるため、プロンプトの短縮が可能であり、その意味でもコストと手間を削減することが可能です。
ファインチューニングのデメリット
ファインチューニングは、特定のタスクにおいてAIモデルを最適化するための強力な手法ですが、その実施にはいくつかの課題とリスクが伴います。データの要求品質、過学習のリスク、高い導入コスト、メンテナンスとアップデートの必要性というデメリットがあり、これらが高い導入障壁となっています。
高品質な学習用データが必要
ファインチューニングは特定のタスクに対して適用させるために、準備するデータセットの質の高さと量によって結果が変わります。要求するレベルは高く、設計と実装には高いスキルを持つ人材による開発体制が求められるため、高い導入ハードルがあります。
過学習のリスク
過学習とは、特定のデータに対して適用されすぎてしまうことです。学習時のデータに対しては高い精度を出しますが、未知のデータに対する精度に問題が生じます。最適化されすぎたデータセットに対してファインチューニングを行うことで、過学習の状態になってしまい、新しいデータや異なるタスクに対する能力が低下する恐れがあります。

導入コストが高い
モデルの学習には膨大なデータを学習させる必要があり、生成AIのAPIに対して従量課金での支払いをするため高いコストが必要です。また、学習に用いる膨大なデータを準備する際にもコストがかかるため、導入のための障壁にもなっています。
メンテナンスとアップデートの必要性
ファインチューニングを行い、最適化されたモデルであっても時間の経過とともに性能が低下する可能性があります。定期的なメンテナンスとアップデートは必須であり、維持管理のために時間とリソースが必要になってきます。
最後に
ファインチューニングは、すでに訓練されたモデルを特定の目的に合わせて再訓練することで、業界やタスクに特化した高精度なアウトプットを実現する手法です。その強みは、汎用モデルの既存の能力を活かしつつ、限られたデータでも効果的に運用できる点にあります。しかし、データセットの品質や量に対する高い要求、過学習のリスク、導入コストの高さ、継続的なメンテナンスの必要性といったデメリットもあります。また、元のデータセットや学習方法によっては、完全に新しいデータで学習させたモデルに性能が劣る場合があるため、ファインチューニングする際には、ターゲットとするタスクやデータセットの特性を十分に理解し、適切な前処理と調整を行うことが重要です。






