
自然言語処理とは、人間が日常的に使用する言語をコンピュータが処理し、文章を理解する技術です。この技術はAIの中核を成す分野であり、機械学習やディープラーニングの進展により、急速に進化しています。ChatGPTのような高度な言語モデルが登場し、さまざまなタスクを1つのシステムでこなせるようになり、日常会話やビジネスでの利用が広がっており、自然言語処理は今やテキストデータや音声データの処理において不可欠な技術となり、その応用範囲はさらに拡大しています。

自然言語処理とは
自然言語処理(NLP、Natural Language Processing)とは、人間が生まれながらに使う言語をコンピュータで処理する技術のことです。人工知能(AI)の研究分野の中核を成す技術の1つであり、大きく分けると言語理解と言語生成の2つの能力を持っています。
- 言語理解:人間が書いた文章に対して何かしらの処理をする技術(メールの自動振り分け、WEB検索など)
- 言語生成:コンピュータに文章を生成させる技術(文章の要約や機械翻訳など)
従来は言語理解と言語生成は用途ごとに開発が進められてきましたが、ChatGPTを始めとするシステムが高度な言語理解と言語生成を可能にしたことにより、さまざまなタスクを1つのシステムでこなすことができるようになりました。
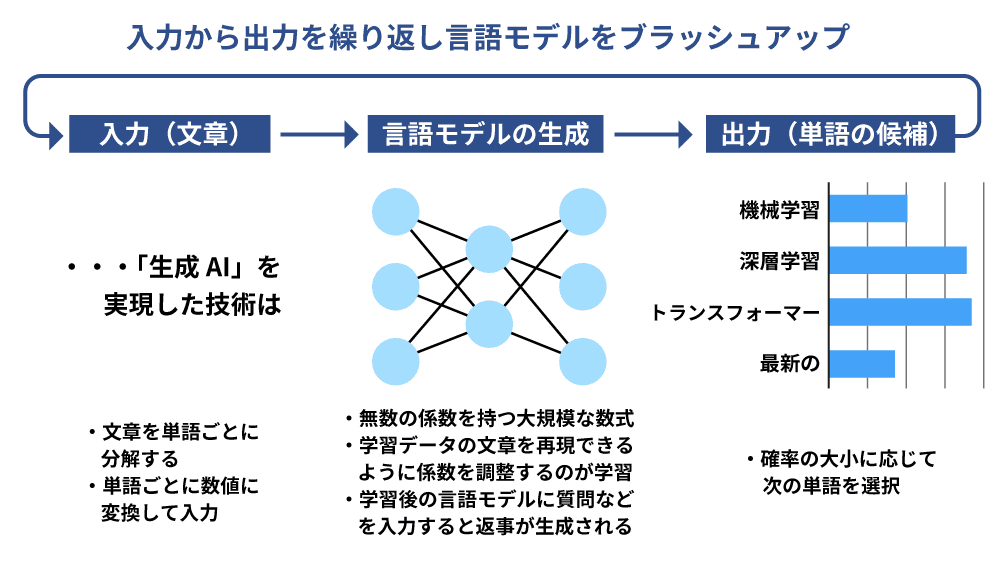
急速なAIの進化にはディープラーニング(深層学習)が大きく関わっています。ディープラーニングを用いた自然言語処理には言語モデル(人間の言語を単語の出現確率を用いてモデル化したもの)が使われ学習させています。文章を入力後に次に来る単語を予測させる学習を繰り返すことで文章パターンを覚えていくことができるようになります。
言語モデルは言い換えれば計算式を組み合わせた数式であり、数式に使われているパラメータ(係数)を含んでいます。このパラメータを調整することを学習と呼び、コンピュータが自動的に実行を繰り返すことで学習が進みます。現在の言語モデルは大規模言語モデル(LLM、Large Language Models)と呼ばれ、パラメータの数は数千億以上あります。ChatGPTが人間に匹敵するほどの能力を持つようになったのは、LLMを基に能力を高める学習を繰り返した結果と考えられています。
自然言語処理の重要性
自然言語処理はテキストデータと音声データを効率的に分析する際に役立ちます。学習を繰り返すことで日常会話、ビジネス会話、方言、スラングなどにも対応することができ、企業内では次のような自動タスクに利用することが可能になります。
- 膨大な文書を分析し、保管する
- 顧客からのフィードバック情報やコールセンターの録音データを分析する
- チャットボットで自動化されたカスタマーサービスを提供する
- テキストを分類し、解析結果を基に抽出する
自然言語処理とは、言い換えれば人間が理解できる文章を処理することですので、膨大な文書や音声データを人間にはできない速度で処理することに長けています。企業に蓄積されたノウハウや長年入力だけされているデータの有効活用などの分野ではAIの活用は非常に強く、人間による処理と比較し、極めて効率的に処理することが可能です。
自然言語処理の仕組み(個別文章の意味理解)
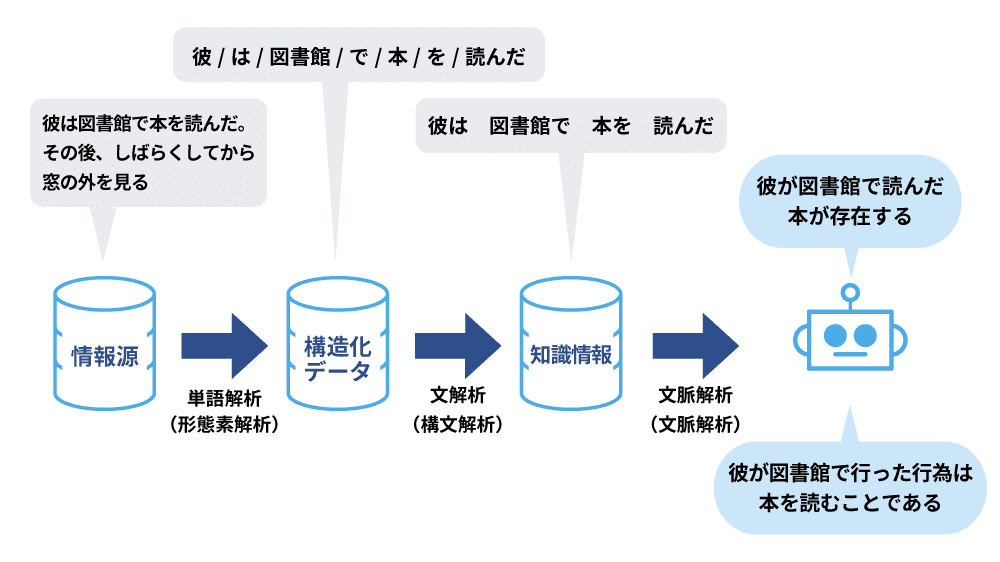
自然言語処理の仕組みは、次の4つの解析に分けられ、文章の言語単位の構造、単語の同義語・類義語、前後の文脈などを踏まえ、個別文章の意味を理解します。
- 形態素解析
- 構文解析
- 意味解析
- 文脈解析
まず、形態素解析では、文章を名詞や動詞などの最小単位に分割し、言語の構造を理解します。特に日本語はスペースを用いないため、この解析が重要です。次に、構文解析では、形態素解析で得られた単語間の関連性を分析し、文法構造を組み立てます。その後、意味解析が行われ、構文解析で得られた複数の意味から正しい解釈を選びます。最後に、文脈解析では、前後の文脈を考慮して文章の意味をさらに精査しますが、この段階ではまだ技術的な課題が多く、文脈を完全に理解するシステムはまだ開発途上です。
形態素解析
形態素解析では、名詞、動詞、助詞、形容詞のような文章を構成する最小単位(形態素)に分割し、学習することで文章作成時に利用できるようになります。英語やフランス語など、多くの言語では文章内の単語間にスペースが使われていますが、日本語にはスペースが使われていないため、形態素解析を行うことで文章理解が始まります。
構文解析
構文解析とは、形態素解析で分割した単語同士の関連性を分析し、文章の構文を組み立てることです。同じ文章であっても受け取り方や文脈によって意味が変わることがありますが、構文解析の段階では、文法的に考えられる構造のすべてを網羅的に挙げる必要があります。
意味解析
構文解析の時点で文章はできあがっていますが、複数の意味が存在することがありますので、構文解析で挙げた文章の中から正しい解釈を探して、文章を作成するのが意味解析です。
文脈解析
同じ文章であっても、文脈によって異なる意味を持つことがあります。自然言語処理では前後の文章にも構造解析と意味解析を実施し、正しい文脈を理解しようとします。しかし、文章同士の関係性は非常に複雑であり、正しい文脈を理解するためには機械学習やニューラルネットワークの精度向上が課題として挙げられており、現時点で実用的な文脈解析システムはできておりません。
自然言語処理の仕組み(コンテンツ全体の意味理解)
自然言語処理では、文章から情報を抽出し、トピックや感情といったコンテンツ全体に共通するニュアンスや意味を理解するための手法が利用されます。主な手法には共起語解析、トピックモデル、感情分析があり、共起語解析は特定の言葉と関連性が高く、同時に使われることが多い言葉を特定し、自然な文章生成に役立てます。トピックモデルは文章がどのトピックを扱っているかを解析し、複数のトピックを含むテキストを正しく分類し、感情分析では文章内の単語から感情を読み取り、全体がポジティブかネガティブかを判断します。これらの手法を用いることで、文章の内容を深く理解し、人間が書いたような自然な文章を生成することが可能になります。
共起語解析
共起語とは、特定の言葉と関連性が高く、同時に使われることの多い言葉のことです。例えば、AIの共起語としてはニューラルネットワークや機械学習などとの関連性が非常に高く、同じ文章内に出てくることが多い言葉です。人間が話すような自然な文章を作るためには、この共起語を正しく理解し、文章の中に違和感なく取り入れる必要があります。
トピックモデル
トピックモデルとは、文章のトピック(題目)を把握する技術のことで、処理対象の文章がどのようなトピックを扱ったものなのかを解析する際に使われます。同じコンピュータに関する文章であっても、AIや機械学習といった単語が頻出する文章とモニタやCPUなどの単語が頻出する文章ではトピックが異なります。トピックモデルにより複数のトピックが含まれているテキストデータであっても正しく分類することができるようになります。
感情分析
感情分析とは、単語の意味から文章全体の感情を分析する技術のことです。SNSやレビューサイトを分析する際には感情分析が使われ、「面白い」や「好き」のような言葉はポジティブ、「つまらない」や「嫌い」のような言葉はネガティブと判断し、文章全体がプラスの感情なのかマイナスの感情なのかを判断する際に利用されます。
自然言語処理の課題
ChatGPTでは自然な文章が生成できるということで話題になりましたが、高度な自然言語処理を用いても文章構造や前後の文脈から正しい意図を解釈し、分析することは容易ではありません。日常的に、あるいはビジネスでAIを利用するためには十分な精度であると言い難いこともあり、現状でも課題は山積しています。特に日本語は単語間にスペースがなく、単語の切れ目がわかりづらいこともあり、対象言語によっては処理制度に偏りが出ていることも大きな課題です。
自然言語の曖昧性
自然言語処理の仕組みは前述したとおりですが、文章を正確に把握するためには、文章を言葉とおりに理解するだけでは不十分であり、代名詞が何を示すのか、文中では明記されていない情報をどう推測するかなどの点で課題があります。
例えば、病気の人に対して「お身体は大丈夫ですか?」に対して「大丈夫」と答えた場合には症状は治ったと解釈できますが、買い物をした人に対して「レシートは大丈夫ですか?」に対する「大丈夫」は不要という意味で解釈できます。まったく同じ言葉であっても状況によって意味がまったく異なるため、技術的に正確に把握することは困難といわれています。
常識の必要性
人間同士の会話では前提となる常識があるために誤解なく伝わる文章であっても、自然言語処理では解釈が難しいことがあります。例えば、「今から飛んでいきます」という言葉を発した場合には「急いで行く」という意味で使っていますが、言葉どおりに解釈すれば空を飛んで向かうことになります。このように人間であれば自然と身につく前提知識であっても自然言語処理に理解させることは難しいことが多いのが実情です。
また、比喩表現として使っていない場合であっても、環境が変われば問題なく使えることもあります。例えば、「遠くにライオンが見える」という文章は、日本では動物園以外では使いづらい表現ですが、サバンナであれば違和感のない文章です。このように前提となる常識をAIに学習させることが大きな課題となっています。
対象言語による違い
自然言語処理のタスクやアルゴリズムは言語に大きく依存してしまうことも大きな課題です。英語では単語同士はスペースで区切られていますが、日本語では区切らないため単語の把握が英語よりも難しく、さらに日本語では平仮名、カタカナ、漢字を使い分ける必要があるため表記がさらに難しくなります。言語に依存する複雑さは、そのまま言語処理のタスクの複雑さに直結するため、言語によって解釈がしやすい、しづらいという差異が生じます。
自然言語処理が注目される背景
自然言語処理が注目される背景には、ビジネス環境でのテキストデータの急増、汎用言語モデルの進化、そしてデジタルトランスフォーメーション(DX)の推進が挙げられます。これらの要因により、膨大なテキストデータの効率的な処理が可能となり、特に大規模企業での労働効率化や自動化において、その重要性が増しています。自然言語処理は、ビジネスにおけるデータ活用の新たな可能性を切り開いています。
テキストデータの増大化
現代のビジネスでは、社内コミュニケーションツールとしてSlackやChatworkなどが導入されるケースが多く、SNSやWEBコンテンツも非常に多いためテキストデータの収集がしやすくなっています。さらに社外コミュニケーションもZoomやMeetのようなオンラインツールが用いられることから、データの文字起こしによるテキストデータの取得も容易になっています。
従来は紙媒体のやり取りが主流でしたがデジタルデータに置き換わったことで膨大なテキストデータを一気に処理できる自然言語処理が注目されるようになりました。
汎用言語モデルの進化
Googleによる汎用言語モデルBERTが発表され、OpenAIからは言語モデルGPT-4が発表されました。このように言語処理研究開発では汎用言語モデルの研究が進んでいます。汎用言語モデルの研究が進んだ結果、高度な言語処理ができるようになり、処理が難しいといわれている日本語でも自然な文章の作成ができるようになってきています。
市場規模の高まりやDXの実現
労働効率化の向上を求めて、自動化やAI技術によるデジタルトランスフォーメーションが欠かせなくなってきています。企業規模が大きくなるほど蓄積しているデータは多く、自然言語処理の応用による恩恵が大きいこともあり、ビジネスへの活用の幅が大きく広がったことも注目される背景となっています。
最後に
自然言語処理は、膨大なテキストや音声データを効率的に処理する技術として、ビジネスや日常生活での重要性が増しています。形態素解析や構文解析、意味解析など、言語の理解や生成のプロセスを通じて、企業は大量のデータから有益な情報を抽出し、労働効率化や自動化を実現しています。汎用言語モデルの進化やデジタルトランスフォーメーションの推進により、その応用範囲はさらに広がり、今後も重要な技術として発展が期待されます。一方で、曖昧な言語の解釈や常識の理解、言語依存性など、技術的な課題も残っており、課題を克服することでさらに精度の高い自然言語処理が可能になるはずです。







